
本文翻译自 Kubernetes network monitoring: What is it, and why do you need it? 。
在本文中,我们将深入探讨 Kubernetes 网络监控和指标,详细研究这些概念,并探索如何将应用程序中的指标转化为有形的、人类可读的报告。本文还将包含有关如何启用 Calico 与 Prometheus 集成的分步教程,Prometheus 是为监控云而创建的免费开源 CNCF 项目。到本文结束时,您将能够根据 Calico 发布的指标创建自定义报告和图形仪表板,以更好地了解集群及其各种组件的内部运作。此外,您还将了解这些碎片如何组合在一起为所有环境建立 Kubernetes 网络监控的基础知识。
云计算和基础架构即代码提供的优势(包括可扩展性、易于分发以及快速灵活的部署)已导致云服务采用率飙升。但这种快速采用需要检查和平衡,以确保云服务安全并以期望的状态运行。此外,应记录和报告任何安全事件和问题以供将来检查。
过去,Nagios 和 Zabbix 等传统监控解决方案主导着监控领域。在基础层面上,传统的监控模型使用基于拉取的系统来查询环境组件并得出结论。基于 ICMP 的检查可以说是使用拉取系统的最具标志性的监控检索。虽然可以使用传统系统来监控云原生环境,但其单体和刚性架构限制了利用云环境能力的各个方面。为了克服这个问题,您应该考虑使用基于推送的监控系统,它可以降低操作复杂性、网络和安全开销以及您需要监控的资源的攻击面。
现在,让我们简要概述一下 Kubernetes 和 Calico 项目。
Kubernetes 有一种网络的抽象方法,它依赖于能够使用容器网络接口 (CNI) 为其资源和组件建立网络的软件。
Calico 项目是一个纯网络层(第 3 层)方法背后的社区,这个网络可以用于高度可扩展数据中心的虚拟网络和安全性。它提供 Calico Open Source,这是一种免费的开源网络和网络安全解决方案,适用于容器、虚拟机和基于主机的本地工作负载。 Calico 提供了许多功能,例如 IP 地址管理、network overlay、可插入数据平面(Linux、eBPF 和 VPP)等等。除了这些功能之外,Calico 还可以暴露指标,让您深入了解环境的健康状况。如果您在运行 Kubernetes 集群方面需要帮助,请查看此 CNCF 点播网络研讨会,了解 Calico 安装最佳实践。
每个应用程序都在不断尝试通过与 CPU 通信来访问系统硬件资源以执行其任务,即使我们通过其图形用户界面 (GUI) 与应用程序进行交互也是如此。虽然我们可能只看到更高级别的应用程序界面,但应用程序在后台不断运行以满足我们的需求。
在开发环境中,应用程序开发人员可以使用断点来暂停进程并查看应用程序的内部工作情况以确定应用程序的运行状况。然而,在生产环境中,这种中断可能会带来高昂的成本,因为它会暂时使服务无响应。作为一种替代方法,开发人员通常会在他们的代码中实现逻辑,以将这些有价值的信息片段暴露给最终用户。这些预定义的值通常被称为监控指标。
例如,Calico 能够通过 HTTP 协议发布其健康和性能指标。这些指标可以被其他程序访问并用于自动执行任务和识别系统的潜在问题。Calico 跟踪的一种指标与其 IP 地址管理 (IPAM) 组件有关,其中包括有关有多少工作负载已获取 IP 的信息地址和特定 IP 池中 IP 地址的可用性。除了 IPAM 指标外,Calico 还跟踪多个其他指标,这些指标可用于评估 Calico 系统及其网络元素的健康状况和性能。
以下截图显示了 calico-kube-controllers-metrics 服务的结果:
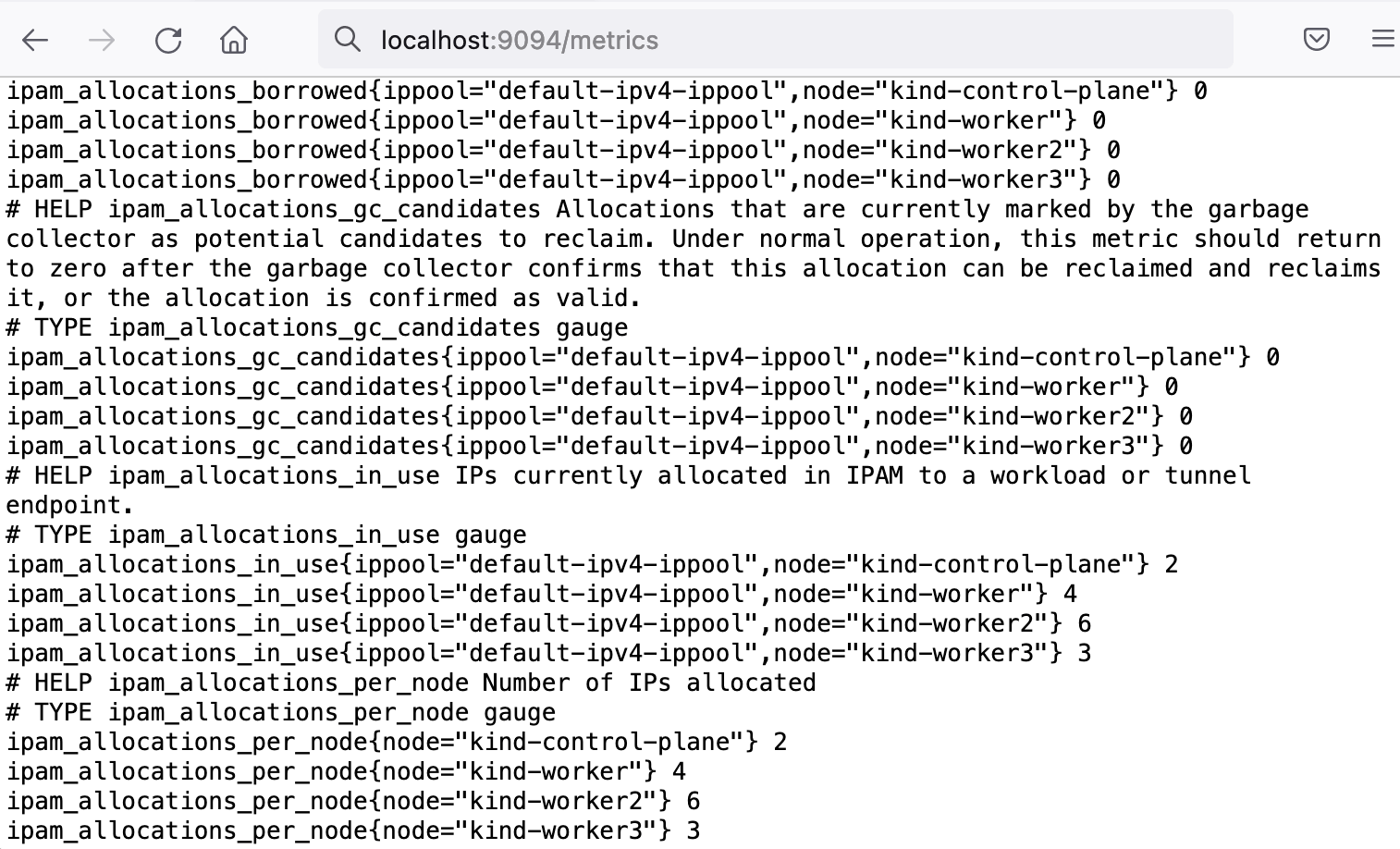
必须注意,应用程序指标不会存储,只会按需实时显示给观察者。为了存储和处理这些指标,我们需要依赖其他应用程序,例如 Prometheus。可在此处找到可用 Calico 指标的完整列表。
Prometheus 是一个免费的开源 CNCF 项目,可以从各种源收集和抓取指标。 Prometheus 可以充当收集和存储系统指标的中央存储库,并可用于生成将技术信息转换为非技术业务语言的综合报告。非技术报告可以让其他人更容易了解您系统的健康状况和性能,并帮助他们根据该信息做出明智的决定。这些报告可用于监控系统的性能和可靠性、识别问题并跟踪一段时间内的趋势。阅读我们的学习指南 Prometheus for Kubernetes,了解有关 Prometheus 工作原理及其优缺点的更多信息。
Prometheus 维护 series 数据的磁盘检查点,并支持对其他存储系统的远程读/写,使其成为与大多数系统集成的简单解决方案。但是让 Prometheus 知道从哪里抓取数据是你的责任,这通常是通过命令行参数和配置文件来完成的。
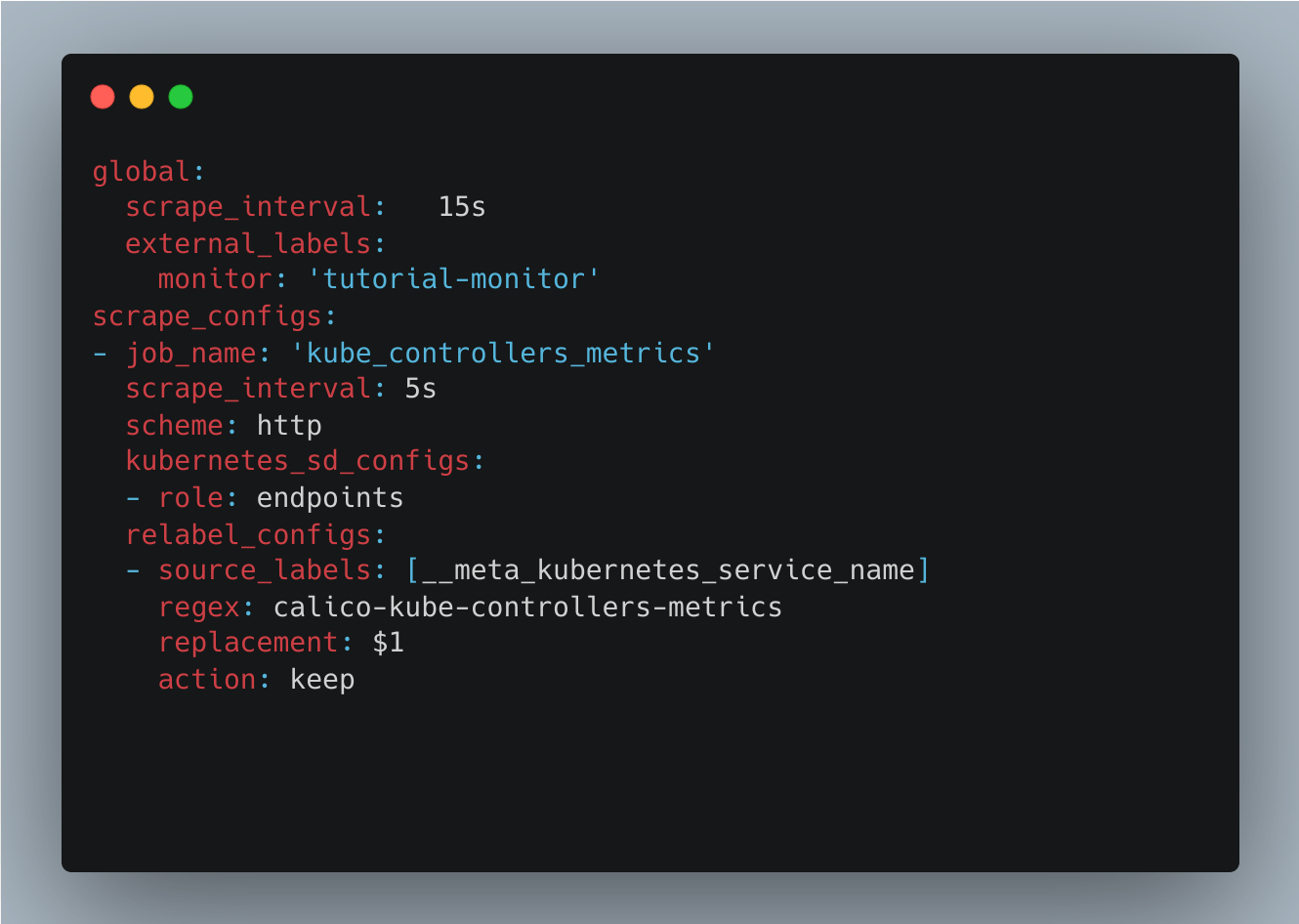
下图说明了从名为 calico-kube-controllers-metrics 的 Kubernetes 服务中抓取 Calico 指标值的配置:
预定义指标通常围绕测量软件的服务在运行时的可用性和性能方面而构建。存储这些信息可以让您更好地了解您的环境在特定时间段内的表现。此类值的中心集合可以让您处理这些不同的指标,以构建具有其他价值的报告。
下图说明了 ipam_allocations_in_use 指标在 1 分钟内的增长:

注意:您可以按照监视 Calico 组件指标的文档启用 Calico 指标和 Prometheus 集成。
Prometheus 不仅仅是一个简单的指标存储系统;它还提供了一种强大的方式来与存储在其数据库中的基于时间序列的值进行交互。 Prometheus 查询语言 (PromQL) 是一种自定义查询语言,旨在查询时间序列和多维数据以操作存储的指标并将结果创建或变异为更好的指标。 PromQL 还实现了数学/日期时间和其他运算符功能,可以帮助我们创建主动报告以构建我们的云原生监控平台。
例如,我们之前的指标 ipam_allocations_in_use 显示了每个参与的集群节点中当前从我们的 ippools 使用了多少 IP。我们还知道 ipam_ippool_size 为我们提供了 ippools 中可用 IP 地址的总数。
使用 PromQL,我们可以编写一行简单的代码来显示我们的 ippools 中可用 IP 地址的当前百分比;
sum(ipam_allocations_in_use)/sum(ipam_ippool_size)*100
下图说明了如何使用 PromQL 来聚合单个指标:

另外值得注意的是,Prometheus 可以用图表的形式表示指标值:

Prometheus 图是一种简单的方法,可以将可视化添加到您的数据以进行 Kubernetes 网络监控。但是,由于 Prometheus 并不专注于可视化,因此您的图形选项是有限的。更直观的可视化表示将需要您安装其他可视化软件,例如 Grafana,我们将在下一节中讨论。
注意:如果您想了解有关 PromQL 的更多信息,请访问此网站。
Grafana 是另一个出色的 CNCF 开源项目,它可能是可视化指标的更好选择。 Grafana 可以使用 Prometheus 作为数据源并使用其存储来创建永久可视化。由于 Grafana 具有内置的身份验证和授权机制,您可以构建 permissions 以允许或拒绝访问您的仪表板。
下图展示了 Grafana 仪表盘中的 Calico 指标:

注意: Grafana 文档中的可视化指标是一个很好的分步指南,可指导您在配备 Calico 的集群中配置 Prometheus 和 Grafana。
在本文中,我们了解了 Kubernetes 网络监控的基础知识,并探讨了如何结合使用 Calico、Prometheus 和 Grafana 等开源项目来运行云原生监控平台。
准备好了吗?查看此学习指南,Prometheus 监控:用例、指标和最佳实践。