OpenTelemetry Collector 是由 OpenTelemetry 提供的独立服务。它可以用作遥测处理系统,具有许多灵活的配置选项,用于收集和管理遥测数据。让我们深入了解一下 OpenTelemetry Collector,以了解它的工作原理。
翻译自 SigNoz 博客 OpenTelemetry Collector - architecture and configuration guide 。

在使用 OpenTelemetry 设置可观测性时的第一步是进行 instrumentation 。应用程序代码会被添加 OpenTelemetry 客户端库的 instrumentation ,这些库有助于生成日志、指标和追踪等遥测数据。
一旦遥测数据生成,它可以直接导出到一个可观测性后端或者 OpenTelemetry Collector。这个 Collector 提供了一个供应商中立的方式来收集、处理和导出您的遥测数据(日志、指标和追踪),这也是为什么更倾向于使用 Collector 的原因。使用 OpenTelemetry Collector 的最大优势在于可以灵活创建不同的数据流水线。
OpenTelemetry Collector 可以以不同的方式部署。它可以作为代理部署在每台主机上。当收集器部署在主机上时,您可以直接收集主机指标,如 CPU 使用率、RAM、磁盘 I/O 指标等。
您还可以将 OpenTelemetry Collector 作为独立服务运行。OpenTelemetry 的客户端库具有可以配置为将遥测数据发送到 Collector 的 exporter 。通常建议混合使用 OpenTelemetry Collector 来处理规模扩展。
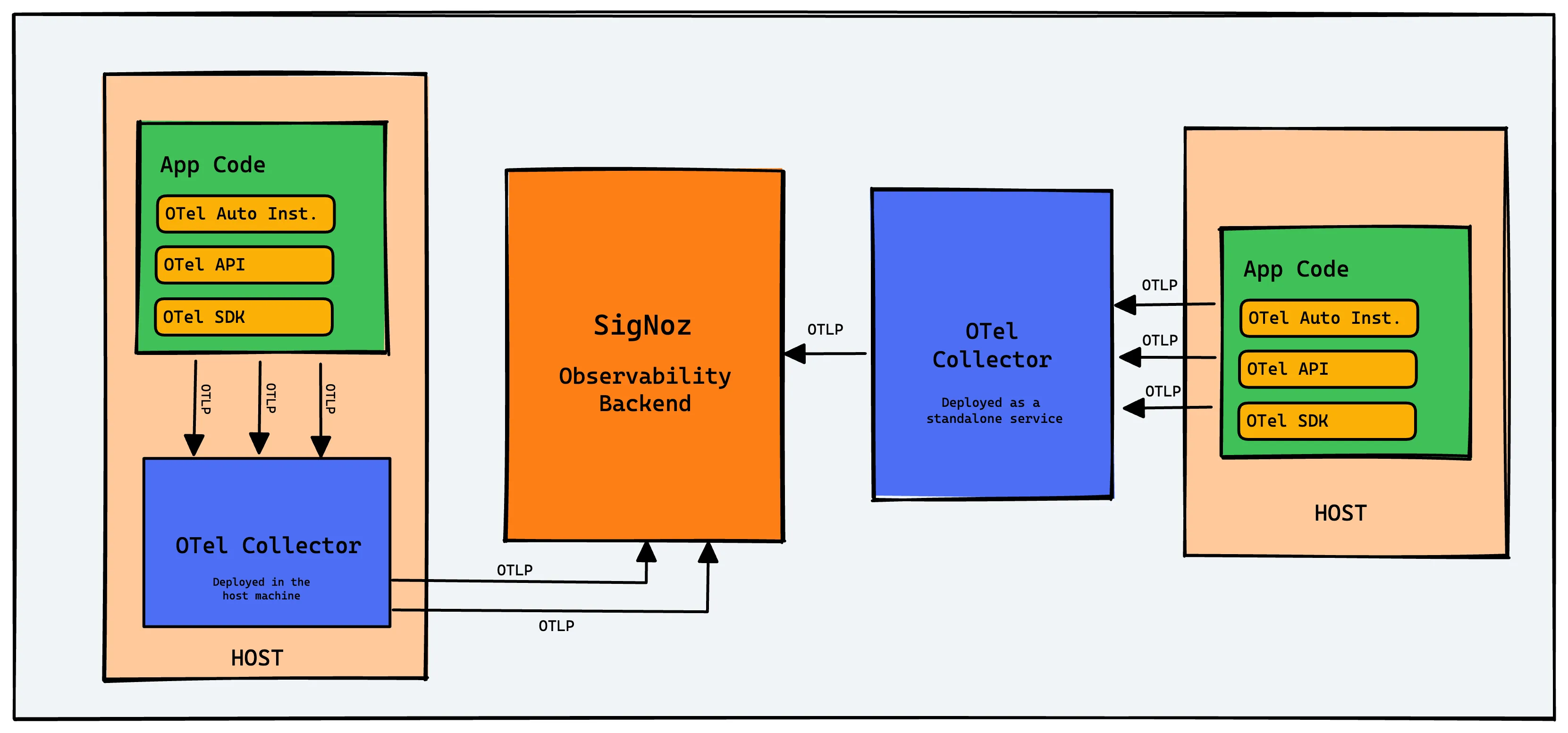
在深入研究 OpenTelemetry Collector 之前,让我们先稍微了解一下什么是 OpenTelemetry。
OpenTelemetry 是一个开源的可观测性框架,旨在标准化遥测数据(日志、指标和追踪)的生成、收集和管理。它孵化在云原生计算基金会(Cloud Native Computing Foundation)下,这也是孵化 Kubernetes 的同一基金会。
OpenTelemetry 遵循规范驱动的开发,并提供客户端库以在大多数编程语言中对应用程序进行 instrumention 。一旦使用 OpenTelemetry 进行了 instrumented ,您应该能够从中收集各种遥测信号,如日志、指标和追踪。这也是 OpenTelemetry Collector 收集器的用武之地。
OpenTelemetry Collector 有三个主要功能:收集、处理和导出收集到的遥测数据。让我们首先了解一下为什么它是您可观测性架构中关键的组成部分。
OpenTelemetry Collector 为处理多种数据格式提供了灵活性,并减轻了应用程序处理遥测数据的负担。
以下是使用 OpenTelemetry Collector 的原因列表:
- 它提供了一种供应商无关的方式来收集遥测数据。
- Collector 可以减轻应用程序处理遥测数据的负担,从而降低开销,并为应用程序提供独立的遥测配置。
- 使用 OpenTelemetry Collector,您可以将遥测数据以多种格式导出到您选择的多个可观察性供应商。
- 它支持基于配置的快速数据管道更新。只需更新配置文件以接收其他格式的数据。
- 它还可以帮助收集主机指标,如 RAM、CPU 和存储容量。
OpenTelemetry Collector 由三个主要组件组成:接收器(Receivers)、处理器(Processors)和导出器(Exporters)。

接收器用于将数据传输到收集器。目前,收集器支持超过四十种不同类型的接收器。您可以使用接收器来配置收集器可以接收数据的端口和格式。这可以是推送或拉取方式。
您可以以多种格式接收数据。它具有默认的 OTLP 格式,但您还可以接收其他流行的开源格式,如 Jaeger 或 Prometheus。
处理器用于对收集到的数据执行所需的任何处理,例如数据整理、数据操作或数据在收集器中流动时的任何更改。它还可以用于从收集的遥测数据中删除 PII 数据,这可能非常有用。
您还可以在发送数据之前对数据进行批处理、在导出失败时进行重试、添加元数据、基于尾部的采样等等。
导出器用于将数据导出到可观测性后端,如 SigNoz。您可以以多种数据格式发送数据。您可以将不同的遥测信号发送到不同的后端分析工具。例如,您可以将追踪发送到 Jaeger,将指标发送到 Prometheus。
通过这三个组件的组合,OpenTelemetry Collector 可用于构建数据管道。通过一个 YAML 配置文件轻松配置这些管道。这为管理遥测数据的团队提供了灵活性。
您需要配置上述 OpenTelemetry 收集器的三个组件。配置完成后,必须通过服务部分中的管道启用这些组件。SigNoz 预先安装了一个 OpenTelemetry 收集器。您可以在这里找到 SigNoz OpenTelemetry 收集器的配置文件。
在下面的示例代码中,我们有两个接收器:
- OTLP
默认的 OpenTelemetry 协议,用于传输遥测数据。SigNoz 使用 OTLP 格式接收遥测数据。
- Jaeger
您还可以以 Jaeger 格式接收追踪数据,这是一种流行的分布式跟踪工具。
receivers:
otlp:
protocols:
grpc:
http:
jaeger:
protocols:
grpc:
thrift_http:以下示例代码中有三个处理器:
- Batch
批处理有助于更好地压缩数据并减少传输数据所需的出站连接数量。此处理器支持基于大小和时间的批处理。
- Memory Limiter
内存限制器处理器用于防止收集器出现内存不足的情况。考虑到收集器处理的数据量和类型是特定于环境的,而收集器的资源利用也取决于配置的处理器,因此有必要对内存使用情况进行检查。
- Queued Retry
强烈建议为每个收集器配置此处理器,因为它可以最大程度地减少由于处理延迟或导出数据问题而丢失数据的可能性。
processors:
batch:
send_batch_size: 1000
timeout: 10s
memory_limiter:
# 与 --mem-ballast-size-mib CLI 参数相同
ballast_size_mib: 683
# 最大内存的80%,上限为 2G
limit_mib: 1500
# 上限的25%,上限为 2G
spike_limit_mib: 512
check_interval: 5s
queued_retry:
num_workers: 4
queue_size: 100
retry_on_failure: true您可以在 OpenTelemetry Collector 的 GitHub 存储库中找到有关这些处理器和更多内容的详细信息。
在此示例代码中,我们创建了两个导出器。
- kafka/traces
这将收集到的追踪数据转发到名为 otlp_spans 的 Kafka 主题。
- kafka/metrics
这将收集到的指标数据转发到名为 otlp_metrics 的 Kafka 主题。
exporters:
kafka/traces:
brokers:
- signoz-kafka:9092
topic: 'otlp_spans'
protocol_version: 2.0.0
kafka/metrics:
brokers:
- signoz-kafka:9092
topic: 'otlp_metrics'
protocol_version: 2.0.0您还可以配置扩展,从而启用监视 OpenTelemetry Collector 的健康状态等功能。
扩展在 OpenTelemetry 收集器的主要功能之上提供了功能。
在此示例中,我们启用了两个扩展。
- 健康检查(Health Check)
它启用了一个 URL,可用于检查 OpenTelemetry 收集器的状态。
- Zpages
它启用了一个 HTTP 端点,用于为 OpenTelemetry 收集器的不同组件提供实时数据进行调试。
extensions:
health_check: {}
zpages: {}配置的所有组件都必须通过 service 部分内的管道启用。如果未在服务部分中定义组件,则不会启用该组件。管道使 OpenTelemetry 收集器成为架构中不可或缺的组件。它提供了以多种格式接收和导出数据的灵活性。
在下面的示例中,来自 SigNoz OTel Collector 配置文件的示例,我们已启用了两个管道。
- 追踪(traces)
在此管道中,我们可以以 jaeger 和 otlp 格式接收追踪。然后,我们对收集到的追踪使用三个处理器,即 signozspanmetrics/prometheus 和 batch。我们将处理后的追踪导出到写入 ClickHouse 数据库。
- 指标(metrics)
在此管道中,我们以 otlp 格式接收指标。使用 batch 处理器处理收集到的指标,然后将处理后的指标导出到 ClickHouse。
service:
extensions: [health_check, zpages]
pipelines:
traces:
receivers: [jaeger, otlp]
processors: [signozspanmetrics/prometheus, batch]
exporters: [clickhousetraces]
metrics:
receivers: [otlp]
processors: [batch]
exporters: [clickhousemetricswrite]一个示例的 OpenTelemetry Collector 配置文件。(来源:SigNoz)
receivers:
filelog/dockercontainers:
include: [ "/var/lib/docker/containers/*/*.log" ]
start_at: end
include_file_path: true
include_file_name: false
operators:
- type: json_parser
id: parser-docker
output: extract_metadata_from_filepath
timestamp:
parse_from: attributes.time
layout: '%Y-%m-%dT%H:%M:%S.%LZ'
- type: regex_parser
id: extract_metadata_from_filepath
regex: '^.*containers/(?P<container_id>[^_]+)/.*log$'
parse_from: attributes["log.file.path"]
output: parse_body
- type: move
id: parse_body
from: attributes.log
to: body
output: time
- type: remove
id: time
field: attributes.time
opencensus:
endpoint: 0.0.0.0:55678
otlp/spanmetrics:
protocols:
grpc:
endpoint: localhost:12345
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
jaeger:
protocols:
grpc:
endpoint: 0.0.0.0:14250
thrift_http:
endpoint: 0.0.0.0:14268
# thrift_compact:
# endpoint: 0.0.0.0:6831
# thrift_binary:
# endpoint: 0.0.0.0:6832
hostmetrics:
collection_interval: 60s
scrapers:
cpu: {}
load: {}
memory: {}
disk: {}
filesystem: {}
network: {}
processors:
batch:
send_batch_size: 10000
send_batch_max_size: 11000
timeout: 10s
signozspanmetrics/prometheus:
metrics_exporter: prometheus
latency_histogram_buckets: [100us, 1ms, 2ms, 6ms, 10ms, 50ms, 100ms, 250ms, 500ms, 1000ms, 1400ms, 2000ms, 5s, 10s, 20s, 40s, 60s ]
dimensions_cache_size: 10000
dimensions:
- name: service.namespace
default: default
- name: deployment.environment
default: default
resourcedetection:
# Using OTEL_RESOURCE_ATTRIBUTES envvar, env detector adds custom labels.
detectors: [env, system] # include ec2 for AWS, gce for GCP and azure for Azure.
timeout: 2s
override: false
extensions:
health_check:
endpoint: 0.0.0.0:13133
zpages:
endpoint: 0.0.0.0:55679
pprof:
endpoint: 0.0.0.0:1777
exporters:
clickhousetraces:
datasource: tcp://clickhouse:9000/?database=signoz_traces
clickhousemetricswrite:
endpoint: tcp://clickhouse:9000/?database=signoz_metrics
resource_to_telemetry_conversion:
enabled: true
prometheus:
endpoint: 0.0.0.0:8889
# logging: {}
clickhouselogsexporter:
dsn: tcp://clickhouse:9000/
timeout: 5s
sending_queue:
queue_size: 100
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
max_elapsed_time: 300s
service:
telemetry:
metrics:
address: 0.0.0.0:8888
extensions:
- health_check
- zpages
- pprof
pipelines:
traces:
receivers: [jaeger, otlp]
processors: [signozspanmetrics/prometheus, batch]
exporters: [clickhousetraces]
metrics:
receivers: [otlp]
processors: [batch]
exporters: [clickhousemetricswrite]
metrics/hostmetrics:
receivers: [hostmetrics]
processors: [resourcedetection, batch]
exporters: [clickhousemetricswrite]
metrics/spanmetrics:
receivers: [otlp/spanmetrics]
exporters: [prometheus]
logs:
receivers: [otlp, filelog/dockercontainers]
processors: [batch]
exporters: [clickhouselogsexporter]OpenTelemetry 提供了一种供应商无关的方法来收集和管理遥测数据。下一步是选择一个后端分析工具,以帮助您理解收集到的数据。SigNoz 是一个专为 OpenTelemetry 本地构建的全栈开源应用性能监控和可观测性平台。
您可以使用终端中的三个命令来开始使用 SigNoz。
git clone -b main https://github.com/SigNoz/signoz.git
cd signoz/deploy/
./install.sh有关详细说明,请访问我们的文档。
{kind=link}
SigNoz 可用于使用图表可视化指标和追踪数据,从而为您的团队提供快速洞察。
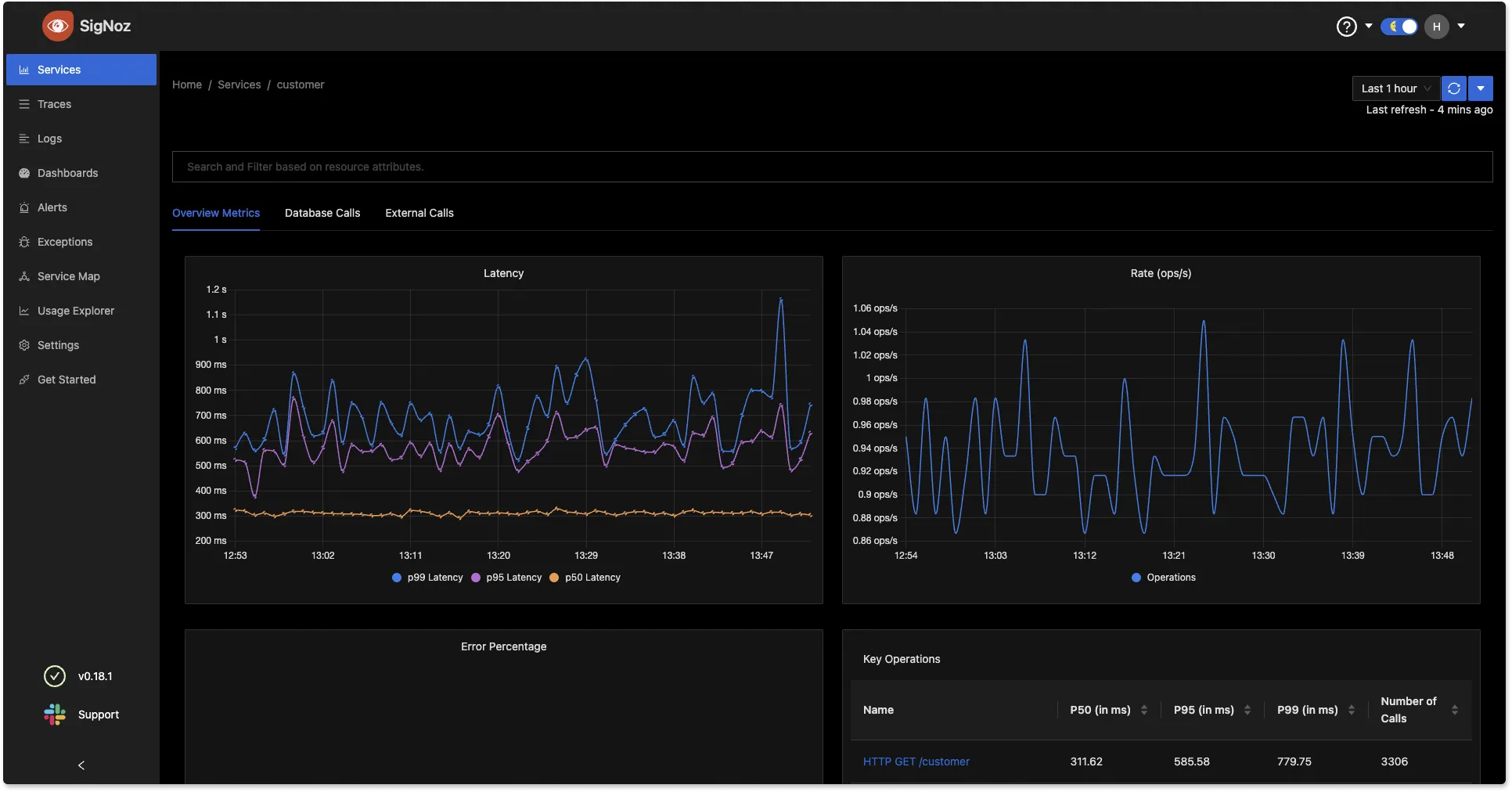
您可以通过访问其 GitHub 存储库来尝试 SigNoz。