翻译自 SigNoz 博客的 Parsing logs with the OpenTelemetry Collector 。
这份指南适用于那些刚开始使用 OpenTelemetry 监控他们的应用程序并生成非结构化日志的人。正如大家所了解的,结构化日志在事后事件分析和对数据的广泛范围查询方面是理想的。然而,在代码层面实现高度结构化的日志记录并不总是可行的。
通过 SigNoz,您可以自动进行一些解析,以识别诸如时间戳、容器 ID、容器名称和可选正文等细节。但是通过相对简单的配置,您可以进一步深入。此外,还应该检查可能包含个人身份信息 (PII) 的属性,并使用过滤器将其删除。由于 SigNoz collector 是 OpenTelemetry collector 的一个分支,因此本教程也适用于配置基线 OpenTelemetry collector。

如果您尚未上报数据,请查看我们关于如何从演示 Node.js 应用程序发送数据的指南,然后回到这里!
为了本教程的目的,我们将在本地以 Docker 容器的方式运行 SigNoz collector 和其他组件,但您也可以在 Kubernetes 上或者使用 Docker Swarm 运行。
目前,OpenTelemetry sdk 在几种语言中并不原生支持日志记录。这意味着您需要利用现有的日志流水线将日志发送到 SigNoz(或 OpenTelemetry) collector。有几种方法可以将日志发送到 OpenTelemetry:
- 桥接 API 用于将现有的日志记录与 OpenTelemetry 连接起来。它可以与现有的日志记录库一起使用,自动在发出的日志中注入跟踪上下文,并通过 OTLP 提供一种简便的方式来发送日志。
- 文件或标准输出导出 - 如果您可以定期读取日志文件或尾随日志,您可以解析裸文件或 .csv 或 json 格式,并将它们发送到收集器。如果您无法自行解析日志,另一个日志收集代理(例如 FluentBit)可以收集日志,然后将日志发送到 OpenTelemetry collector 。
在 Java 中,您还可以选择使用自动 instrumentation 来收集日志。
对于我的示例,我直接通过网络调用使用 OTLP 发送了日志,但是这种方法不推荐用于生产环境。这是有道理的:您不希望从代码内部维护数十个网络调用,也不希望为网络开销付费!
如果您查看 SigNoz 存储库,您将在 /deploy/docker/clickhouse-setup/otel-collector-config.yaml 中找到 collector 的配置(在安装过程中可能已经获取了该项目)。您可以编辑此文件,以在 collector 接收到日志后过滤要存储的日志。
编辑此文件后,您需要重新启动 collector 。如果使用 Docker,命令将是 docker restart signoz-otel-collector。
有一些未经编辑的配置块值得检查(由于将来可能会更改,我不会在此提到行号,只是指出相关部分)。再次说明,SigNoz collector 是 OpenTelemetry collector 的一个分支,所有这些配置对于 collector 一般都适用。
batch:
send_batch_size: 10000
send_batch_max_size: 11000
timeout: 10s在收集器内部包含一些批处理配置是至关重要的,因为如果您每收到一个跨度、度量数据点或日志记录就发送数据,您可能会迅速过度使用资源。
-
send_batch_size:在超时之前将发送的跨度、度量数据点或日志记录数量。send_batch_size充当触发器,不影响批次的大小。 -
send_batch_max_size:批次大小的上限。0 表示没有批次大小的上限。 -
timeout:超时后,将发送批次,无论其大小如何。请注意,在测试时,您可能希望减少此值,因为测试数据不太可能填满批次大小,这将导致您有 10 秒以上的延迟。我将此值设置为 1 秒。
在 receivers 部分,您将找到以下相当大的表达式:
- type: filter
id: signoz_logs_filter
expr: 'attributes.container_name matches "^signoz-(logspout|frontend|alertmanager|query-service|otel-collector|otel-collector-metrics|clickhouse|zookeeper)"'过滤器处理器允许用户基于包含或排除规则筛选遥测数据。包含规则用于定义“允许列表”,其中不匹配包含规则的任何内容都将从收集器中删除。排除规则用于定义“拒绝列表”,其中与规则匹配的遥测数据将从收集器中删除。
在这种情况下,我们不希望我们的 SigNoz 进程变得“太元”,因此我们正在消除由我们自己的容器及其附加服务生成的日志,以便不会混淆您的应用程序数据。
值得注意的是,除非在 pipelines 部分引用了它,否则此处定义的过滤不会生效。
在我的情况下,我的日志由于我在使用另一个名为 Testkube 的 Kubernetes 工具进行
探索而变得混乱不堪,因此我更新了模式,以排除任何具有 testkube 名称的内容:
- type: filter
id: signoz_logs_filter
expr: 'attributes.container_name matches "^(signoz-(logspout|frontend|alertmanager|query-service|otel-collector|otel-collector-metrics|clickhouse|zookeeper)|.*testkube.*)"'对于 testkube 容器日志,我无法找到如此优雅的方法,因为“testkube”并不出现在开头。
现在是时候执行此配置了。如果您与我类似,应该先在 yamllint 上进行快速检查,以确保您的 YAML 没有格式问题(甚至可以查看漂亮的 UTF-8 格式化输出,以确保您的正则表达式中没有智能引号或其他垃圾问题)。最后,使用 docker restart signoz-otel-collector 命令重新启动收集器,并发送一些日志以查看更新。
为了在此 collector 记录的所有日志行中添加属性,可以在 processors 中添加一个部分来添加属性。以下示例有些牵强,但假设此 collector 仅为单个客户组织收集数据:
attributes/clientid:
actions:
- key: client_id
value: 1123
action: insert这里可以使用更复杂的逻辑来重新使用其他属性值和连接,但在这种情况下,我们只想为每个日志行添加相同的 client_id 属性,值为 1123。
但是,仅添加这个映射还不足以添加属性,我们还没有将此 processors 添加到我们的 pipeline 中,请查看用于日志的 pipelines 映射:
logs:
receivers: [otlp, tcplog/docker]
processors: [logstransform/internal, batch]
exporters: [clickhouselogsexporter]'为了实际影响我们的数据,我们必须将其添加到 pipeline 中。修改后的版本如下:
logs:
receivers: [otlp, tcplog/docker]
processors: [logstransform/internal, attributes/clientid, batch]
exporters: [clickhouselogsexporter]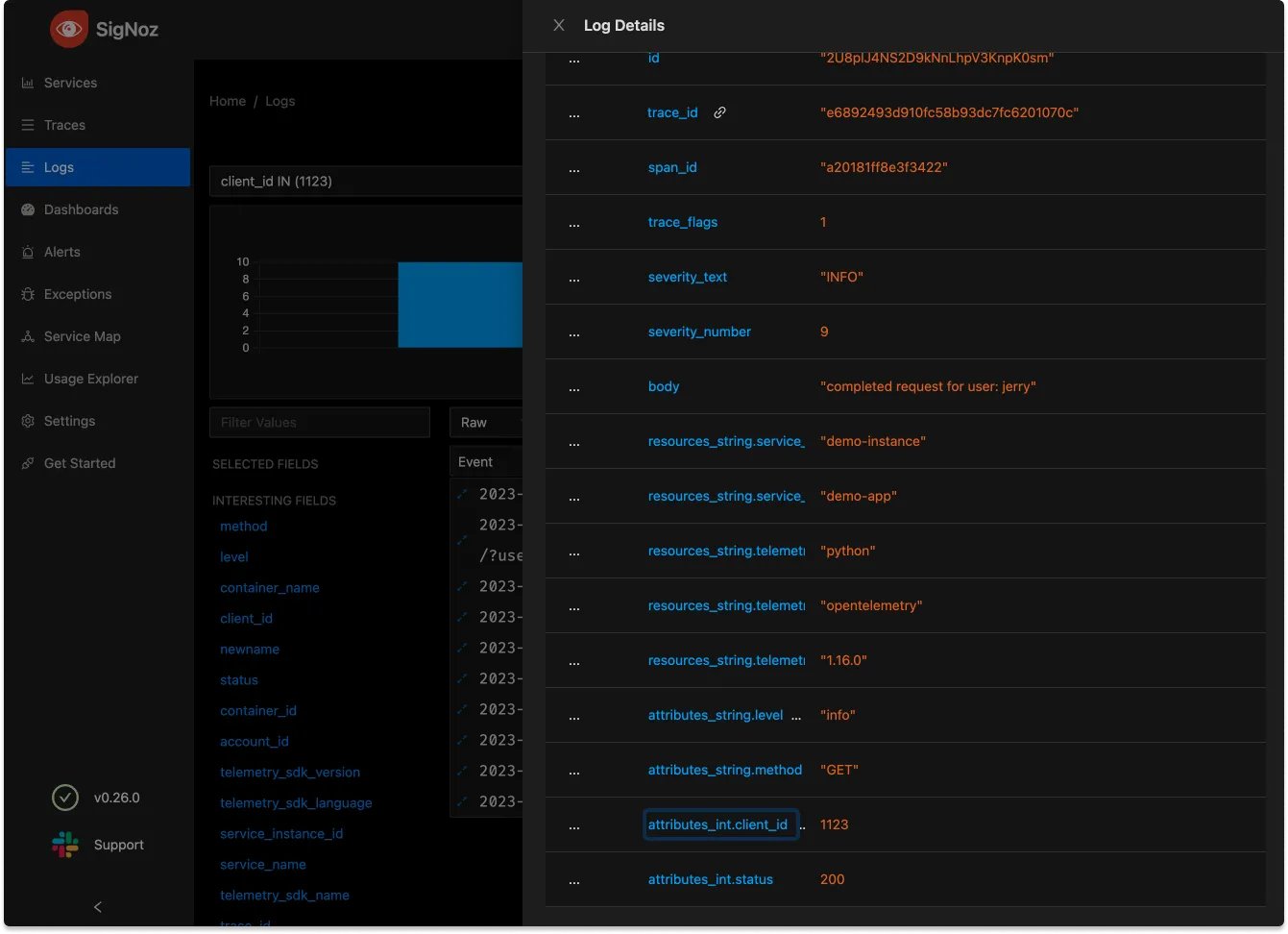
处理器按顺序执行,因此我们希望在批处理 processors 之前添加此 processor。如果其中一个 processor 删除了相关数据,则此项非常重要。
现在我们可以添加属性,是时候为我们解析的数据提供更通用的编辑工具了。这可以通过使用 OpenTelemetry 转换语言(OTTL)来实现。并不需要或实际上无法了解此语言的所有细节,但让我们从一个简单的处理开始,以添加一些有用的属性。
在处理器部分内,我们将添加一个转换:
transform:
log_statements:
- context: log
statements:
- set(severity_text, "FAIL") where body == "request failed"这个配置相当易读,目标是在存在特定请求正文时添加一个明显可读的属性。请注意,这里可能可以进行更复杂的匹配,但对于此情况,使用 == 即可。
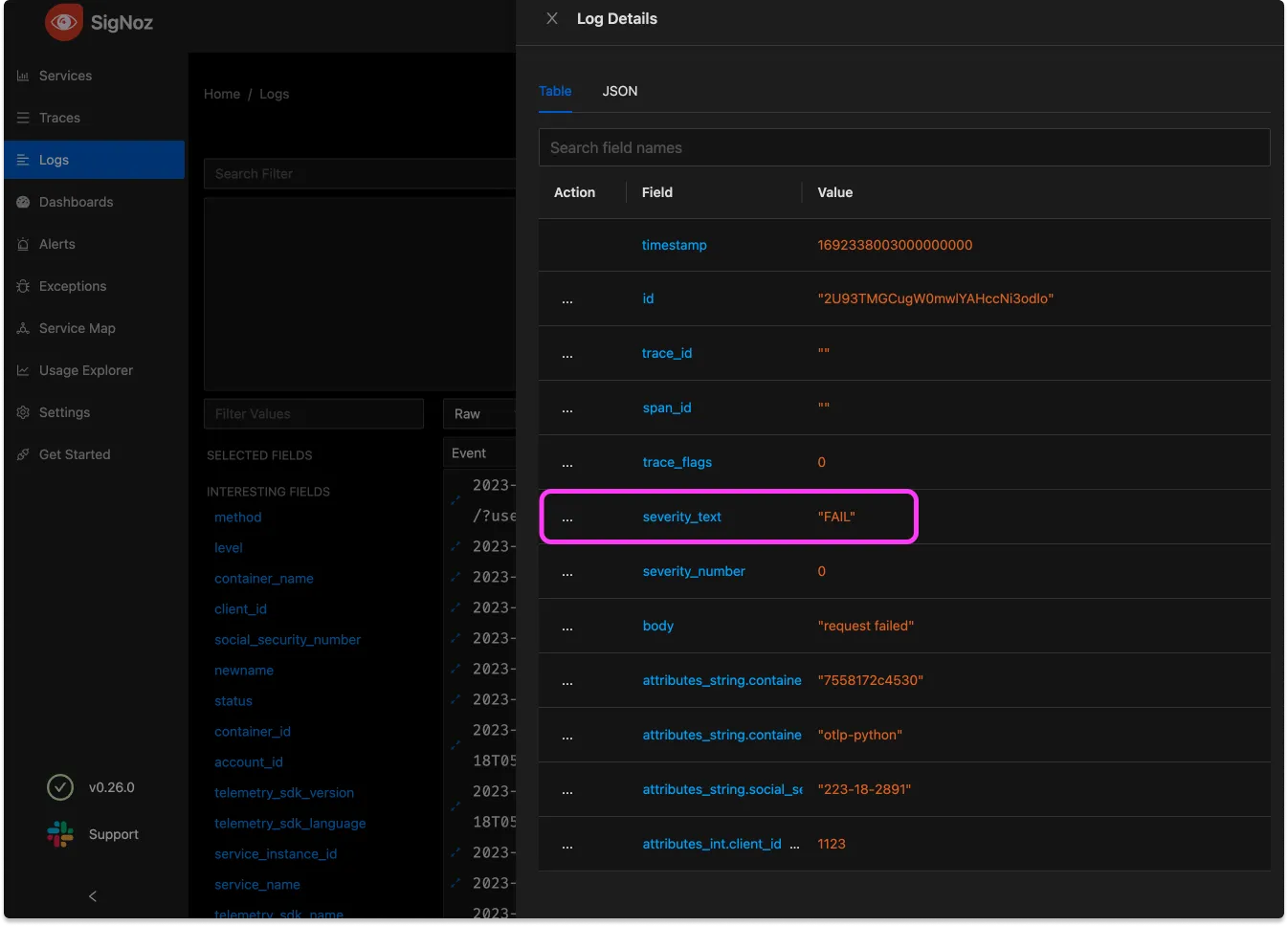
接下来,让我们将此工具应用于一个非常严重的情况:我们的数据中存在 PII。细心的读者可能已经在上一个截图中注意到一个属性,其值看起来非常像用户的社会安全号码(在美国,与法定姓名相关联的这个号码构成了最严重的数据泄露形式)。
在我们的可观测性工具传输个人可识别信息(PII)是我们绝不想忽视的问题。在可观测性数据中无意中包含 PII 可能违反法律和监管合规框架,如 GDPR、HIPAA 等,这些框架规定了个人信息的处理。违反这些规定可能会导致财务处罚、法律诉讼和声誉损害。
transform:
log_statements:
- context: log
statements:
- set(severity_text, "FAIL") where body == "request failed"
- replace_match(attributes["social_security_number"], "*", "{userSocial}")由于在这种情况下,PII 被很好地标记,因此可以轻松地用通用的值替换任何可能的值。
请注意,在实际情况下,如果可能的话,尽量在 instrumentation 层面过滤掉此类关键信息可能是值得的。但是,总是对 PII 进行两次过滤是一种好习惯!

在这个相当人为的例子中,PII 是由一个名为 attributes/userinfo 的处理器添加的。这使得管道的顺序变得重要,例如这个收集器配置:
logs:
receivers: [otlp, tcplog/docker]
processors: [logstransform/internal, attributes/userinfo, transform, batch]
exporters: [clickhouselogsexporter]这样会使得 transform 步骤能够移除 attributes/userinfo 添加的 PII,但如果我们交换它们的位置 [logstransform/internal, transform, attributes/userinfo, batch],则可能会覆盖 PII!
虽然我们始终希望我们的日志数据非常具体,但有时候通过引入高基数数据反而使事情变得更加困难。请参阅我之前关于高基数数据的工作。下面是一个示例,在以后的工作中进行一些指标聚合将使我们的生活更加轻松:
logs:
replace_match(attributes["http.target"], "/user/*/list/*", "/user/{userId}/list/{listId}")值得注意的是,我们可能会希望这个日志有一个 userID,但如果有的话,我们应该在下一节将其解析为自己的属性。将 ID 放在 [http.target] 属性中将使得任何数据关联变得不可能。转换可以是规范化我们数据的关键步骤。
在任何 processor 看到我们的日志之前,它们首先会到达配置的 receivers 。在 SigNoz OpenTelemetry Receiver 的基线配置顶部,您会找到以下表达式:
receivers:
tcplog/docker:
listen_address: "0.0.0.0:2255"
operators:
- type: regex_parser
regex: '^<([0-9]+)>[0-9]+ (?P<timestamp>[0-9]{4}-[0-9]{2}-[0-9]{2}T[0-9]{2}:[0-9]{2}:[0-9]{2}(\.[0-9]+)?([zZ]|([\+-])([01]\d|2[0-3]):?([
0-5]\d)?)?) (?P<container_id>\S+) (?P<container_name>\S+) [0-9]+ - -( (?P<body>.*))?'如果将其添加到 pipeline 中,此 receiver 仅会在发送到指定端口的日志上运行。
在此处,传入的日志由 regex_parser 操作符解析,该操作符检查传入的字符串并设置属性。这在 opentelemetry-collector-contrib 存储库中有记录。请注意,更改 tcplog/docker receiver 可能会导致丢失数据。该操作符使用 Go 正则表达式。在编写正则表达式时,可以考虑使用诸如 regex101 等工具。
以下是处理时间戳的示例解析器:
- type: regex_parser
regex: '^Time=(?P<timestamp_field>\d{4}-\d{2}-\d{2}), Host=(?P<host>[^,]+), Type=(?P<type>.*)$'
timestamp:
parse_from: body.timestamp_field
layout_type: strptime
layout: '%Y-%m-%d'regex_parser 还可以包含 if 语句,如果您正在接收多种类型的消息,则可以使用它,例如:
- type: regex_parser
regex: '^Host=(?<host>)$'
parse_from: body.message
if: 'body.type == "hostname"'在此示例中,不是每条消息都会有 "type": "hostname" 键/值对,因此不会由此模式解析。
有关日志接收器和操作符的更多信息,请查阅我们关于解析 CSV 和 JSON 格式、syslog 原生解析以及数学和其他函数的文档。
在我们的文档中,您可以查阅有关日志 recievers 和 operators 的更多详细信息,包括解析 CSV 和 JSON 格式、syslog 原生解析以及数学和其他函数等内容。
使用 OpenTelemetry Collector,日志处理非常灵活且功能强大,receivers 和 processors 的组合使得将原始日志转换为高度结构化的数据成为可能。
如果您想了解此日志解析的强大之处,在重新配置收集器之前,请查看我们的新日志浏览器,深入了解日志数据。您经常会发现有趣的见解,并且可以通过更深入地解析数据来概括它们以备下次使用。