超越基础知识,在 Kubernetes 内存指标方面深入探讨。
译自 From RSS to WSS: Navigating the Depths of Kubernetes Memory Metrics。作者 Yuval 。
无论您是 DevOps 工程师、系统管理员还是刚入门 Kubernetes 的人,了解内存指标可能会改变游戏规则。
如果您发现自己观察容器内存利用率,想知道依赖哪个度量标准,并质疑基于内存的决策的准确性,您来对地方了。
本文深入探讨了内存指标的复杂性,并揭示了 Kubernetes 和 Linux 对内存的截然不同的观点。
我的主要目标是为您提供更深入的理解和洞察,而不是提供实用的一刀切指导。
- 背景
- 测量节点内存使用情况
- 测量容器内存使用情况
- 了解内核文件缓存机制
- 探索 Cadvisor 指标:RSS 和 WSS
- 计算节点内存使用情况:最终分解
- 缓存内存视角:Kubernetes vs. Linux
- 评估内存指标:何时担忧 8.1 可观测性 8.2 Kubelet 驱逐
- 最后的思考
我们对内存指标的探索始于一个简单的任务:了解节点的内存利用情况,而不考虑“Kubernetes 层”,即所有 pod 容器的内存使用情况。
起初,这似乎很简单:测量节点的内存使用情况并减去所有 pod 容器内存使用情况。然而,事实证明这个任务比看起来更复杂。
首先,让我们计算节点的内存使用情况。节点指标是使用 node exporter 生成的。
常用于计算总节点内存使用情况的“传统”方法,通常在像 kube-prometheus-stack 这样的仪表板上常用的方法是:
node_memory_MemTotal_bytes - node_memory_MemFree_bytes - (node_memory_Buffers_bytes + node_memory_Cached_bytes)
这里是查询中使用的指标的快速解释:
- MemTotal:节点上可用的内存量
- MemFree:节点上未使用的内存量
- Cached:用于缓存文件的内存量
- Buffers:用于文件系统缓冲区的物理内存量
这个计算给我们提供了没有缓存和缓冲区的内存使用情况,提供了更准确的视图,即应用程序和系统主动使用的内存,不容易被轻松回收。
容器指标来自 cadvisor。对于容器内存使用情况,有三个常用的 cadvisor 指标:
- container_memory_wss(在 Grafana 中最常被监视和观察的指标)
- container_memory_rss
- container_memory_usage_bytes
这些指标是至关重要的,我们将稍后深入讨论。现在,让我们专注于计算没有 Kubernetes 层的节点内存使用情况之前的事项。
在我们开始计算之前,这里有一些建议事项:
- 单节点假设:为了简单起见,我们的计算基于一个集群中只有一个节点的假设。
- 术语:我们将先前执行的节点内存使用计算称为“node_memory_without_cache”。
- 演示说明:出于演示目的,我使查询结果显然错误,但以下查询可以产生合理的结果(尽管不是有价值的结果)。
node_memory_without_cache — sum(container_memory_wss)
结果:-214032569(约 0.2GiB)
注:不可能(负内存使用)。
node_memory_without_cache — sum(container_memory_rss)
结果:7475889870(约 6.9GiB)
注:可能,但对于常规节点使用来说似乎过高。
node_memory_without_cache — sum(container_memory_usage_bytes)
结果:-1475889870(约 -1.37GiB)
注:不可能(负内存使用)。
这些查询都没有产生令人满意的结果。让我们让事情变得有趣起来,深入研究这些指标。理解它们将为我们揭示 Kubernetes 和 Linux 对内存的不同视角带来一些有趣的收获,所以请继续关注。
在我们深入研究 container_memory_wss 和 container_memory_rss 之间的差异之前,了解一下与文件缓存相关的内核机制是很重要的。
未使用的内存是浪费的内存。内核会缓存用户空间触及的所有内容,直到 RAM 几乎满了,必须回收一些内存以允许写入新数据。
内核将文件缓存分为两个列表:Active(活动)和 Inactive(非活动)。这些列表帮助内核决定在需要内存用于其他目的时保留哪些页面,以及在内存需要时要驱逐哪些页面。您可以在文件 /sys/fs/cgroup/<cgroup_path>/memory.stat 中看到特定 cgroup 的 active_file 和 inactive_file 大小。
Inactive_file — 可能需要再次使用但目前未活跃使用的页面缓存内存。在需要驱逐时,首先从此列表中选择文件进行驱逐。
Active_file — 较近期使用过的页面缓存内存,通常在需要之前不回收。
是什么决定文件是“活动”还是“非活动”?仅访问一页两次就足以将其放在活动列表上。
活动文件是否可回收?是的!尽管内核首先会从非活动列表中回收文件,但活动文件仍然有很大可能是可回收的。
container_memory_usage_bytes — 表示总内存使用量。
container_memory_rss(Resident Set Size) — 表示进程在主内存中具有的不对应于磁盘上任何内容的物理内存量。通常包括堆栈、堆和匿名内存映射。Cadvisor 从文件 /sys/fs/cgroup/<cgroup_path>/memory.stat 中的特定容器 cgroup 的“anon”参数中获取 rss 值。代码引用:
ret.Memory.RSS = s.MemoryStats.Stats["anon"]根据 cgroup-v2 文档所述,"anon"表示在匿名映射(如 brk()、sbrk() 和 mmap(MAP_ANONYMOUS))中使用的内存量。
container_memory_wss(Working Set Size) — 表示进程在一段时间内保持工作所需的内存量。
与操作系统中具有特定值的固定指标(如 'cache' 或 'buffer')不同,工作集是通过各种方式计算的值。
Cadvisor 以非常简单的方式计算工作集:总内存使用量减去非活动文件。代码引用:
workingSet := ret.Memory.Usage
if v, ok := s.MemoryStats.Stats[inactiveFileKeyName]; ok {
if workingSet < v {
workingSet = 0
} else {
workingSet -= v
}
}
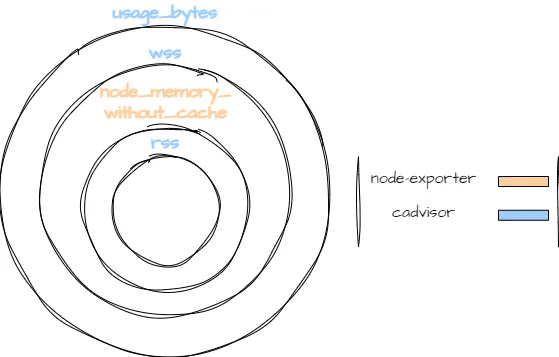
ret.Memory.WorkingSet = workingSet以下插图清晰地说明了这些指标之间的关系:

我们可以看到为什么先前的计算(没有 Kubernetes 层的节点内存使用)导致错误的结果。没有一个 cadvisor 指标代表与 node exporter 指标相同的内存使用情况。
- rss < node_memory_without_cache:node_memory_without_cache 包含不由文件支持但仍未计入 rss 的内存,例如内核内存。
- node_memory_without_cache < wss:wss 包含活动文件缓存。
- node_memory_without_cache < usage_bytes:usage_bytes 包含缓存。
Cadvisor 有一个名为 “container_memory_cache”的指标。通过执行以下计算,我们可以获得所需的结果:
node_memory_without_cache - sum(container_memory_usage_bytes - container_memory_cache)
我们首先计算不带缓存的容器内存使用情况。然后,从节点的内存使用情况中减去它的缓存。此计算提供了节点在 Kubernetes 层外主动使用的内存的精确测量,这部分内存不能轻松回收。
从计算中省略缓存与我的具体要求相关。
值得注意的是,本文的重点不是主要集中在这个计算上;我呈现它是为了说明内存的不同层次。中心话题是与 Kubernetes 有关的内存。
Kubernetes 的操作基于这样的假设:内核识别内存工作集并将其保留在活动列表中。不在工作集中的任何内容都会放入非活动列表,并被视为可回收。
从文档中看:
memory.available 的值是从 cgroupfs 而不是从 free -m 这样的工具派生出来的。这很重要,因为 free -m 在容器中不起作用,如果用户使用节点可分配特性,则在端用户 Pod 部分的 cgroup 层次结构以及根节点中都会做出资源不足的决策。该脚本重复 kubelet 执行以计算 memory.available 的相同步骤。kubelet 从其计算中排除 inactive_file(即在非活动 LRU 列表上的文件支持内存字节数),因为它认为在压力下内存是可回收的。
与 Linux 内核中的 mm/workingset.c 的注释进行比较:
有关活动列表的所有已知信息都是过去曾经访问过的这些页面。这意味着在任何给定时间,活动列表上的页面实际上很有可能不再处于活动使用状态。
虽然 Kubernetes 和 Linux 都同意工作集应该驻留在活动列表中,但 Kubernetes 对可回收内存以及活动列表中的多少可以在不将系统推入抖动状态的情况下回收有着悲观的启发法。
根据我们最近探讨的内存视角,有几种情况需要考虑。我们将深入研究两种主要情况。
监控容器内存使用至关重要。
当观察到内存使用接近其限制时,有关容器可能因内存不足而被 OOMKilled(内存耗尽)的担忧可能会产生。但是,您是否总是应该担心呢?并非一定如此。这在很大程度上取决于您应用程序的行为。
何时应该担心?
- 高 RSS,接近内存限制:RSS 内存不容易被回收,使容器有很高的机会被 OOMKilled。
- 低 RSS,高 WSS,难以回收文件缓存:如果 RSS 低,但工作集大小(WSS)高,而活动文件缓存不容易被回收,容器面临着很高的被 OOMKilled 的风险。
- 低 RSS,高 WSS,易于回收但会影响性能的文件缓存:即使文件缓存可以轻松被回收,这样做可能会影响应用程序的性能。
何时不那么令人担忧?
- 低 RSS,高 WSS,回收不影响性能:如果 RSS 低,而 WSS 高,活动文件缓存可以被回收而不影响应用程序的性能,那就没有太多理由担忧。我们应始终记住,未使用的内存是浪费的内存,将文件标记为活动只需要访问两次。
调查文件缓存回收:
确定您的文件缓存是否可以回收,以及这样做是否会对应用程序的性能产生负面影响可能会有些棘手。一些调查的方法包括:
- 增加容器的内存资源,然后观察其性能是否提高。
- 使用命令
echo 1 > /proc/sys/vm/drop_caches来清除页面缓存。随后,监视从活动列表中回收了多少页面,并测量对应用程序性能的影响。需要注意的是,尤其是在生产环境中,清除缓存可能会降低性能,所以请小心操作。
还有其他更深入研究的策略,可能会在未来的讨论或论文中探讨。
关于 Kubelet 驱逐的简要说明:
在 Kubernetes 环境中,kubelet 不断跟踪每个节点的内存消耗。如果内存使用超过指定的驱逐阈值,kubelet 将决定驱逐一个或多个容器。这样做是为了确保节点的稳定性和功能。与 oomkill 的突然性质不同,kubelet 的驱逐机制允许更为优雅地终止 pod。然而,默认情况下未定义此阈值。
当内存限制未设置或定义得比请求高时,驱逐阈值可能导致意外的行为(在大多数情况下是不推荐的)。
为什么这可能导致意外的行为?
正如先前在 Kubernetes 文档中指出的那样:"kubelet 将非活动文件(即在非活动 LRU 列表上的文件支持内存字节数)从其计算中排除",这表明 kubelet 在其内存使用计算中包括所有活动文件页缓存,有时可能呈现出误导性的情况。
实际场景:
考虑一个读取 10GiB 文件两次的应用程序。Linux 内核将其缓存,将 10GiB 添加到 'active' 内存。虽然这个内存对于 kubelet 来说似乎很关键,但实际上它只是缓存的数据,可能不会经常访问,并且在某些条件下可能意外导致驱逐。
设置启用驱逐的内存限制的重要性:
没有设置内存限制的容器可能会消耗过多且不受控制的页面缓存。这会增加工作集大小(WSS),并可能触发不希望的驱逐。
通过设置适当的内存限制,可以将容器内存使用限制在一定范围内。当容器接近其内存阈值时,内核开始从活动列表中回收可回收的页面。这不仅有助于防止过度的缓存内存使用,还减小了 kubelet 解释内存消耗的风险。

在容器化系统中,准确监控内存是至关重要的。正如我们所见,Kubernetes 和 Linux 对缓存内存有一些不同的观点。这些不同的观点可能会混淆我们对内存使用的理解。了解这些差异有助于理解真正的内存需求,并预见潜在问题,从而帮助预防挑战。通过仔细分析这些指标,我们可以确保强大的性能和增强系统的韧性。