
可观测性通常在三个支柱的背景下定义 - 日志,指标和跟踪。现代云原生应用程序复杂而动态。为了避免意外和性能问题,您需要一个强大的可观测性堆栈。但是,可观测性是否仅限于收集日志,指标和跟踪呢?
译自 SigNoz 博客的 Three Pillars of Observability [And Beyond]。作者 Leigh Finch。
监控工具在过去 25 年一直是任何企业的关键组成部分,提供对基础设施和应用程序问题的高级警报,以防止它们影响客户。随着时光的推移,我们在监控系统中增加了指标的数量,以更好地了解正在监控的系统。
然而,随着软件系统的复杂化,仅仅依赖指标进行监控存在其局限性。它通常无法识别可能导致数字体验问题、影响最终用户的未知变量。
最近,'可观测性'的概念在行业中崭露头角,标志着从传统监控的转变。与后者专注于预定义的指标不同,可观测性强调理解系统在任何给定时间的状态,包括前导和后续的服务水平指标。这种方法允许实时了解性能问题或错误,而不受特定指标的限制。例如,使用像 SigNoz 这样的可观测性工具来跟踪 Web 请求会展示请求的整个过程和内部操作,提供比仅测量服务器响应时间更全面的视角。它包括在特定请求的上下文中正在完成的工作的详细信息(方法、类、数据库查询)。
可观测性的三大支柱通常是指标、跟踪和日志。
在检查指标时,它们通常代表在给定时刻的特定指标的状态。这对于理解随时间变化的情况至关重要,如在时间序列图中所见,例如 CPU 利用率。
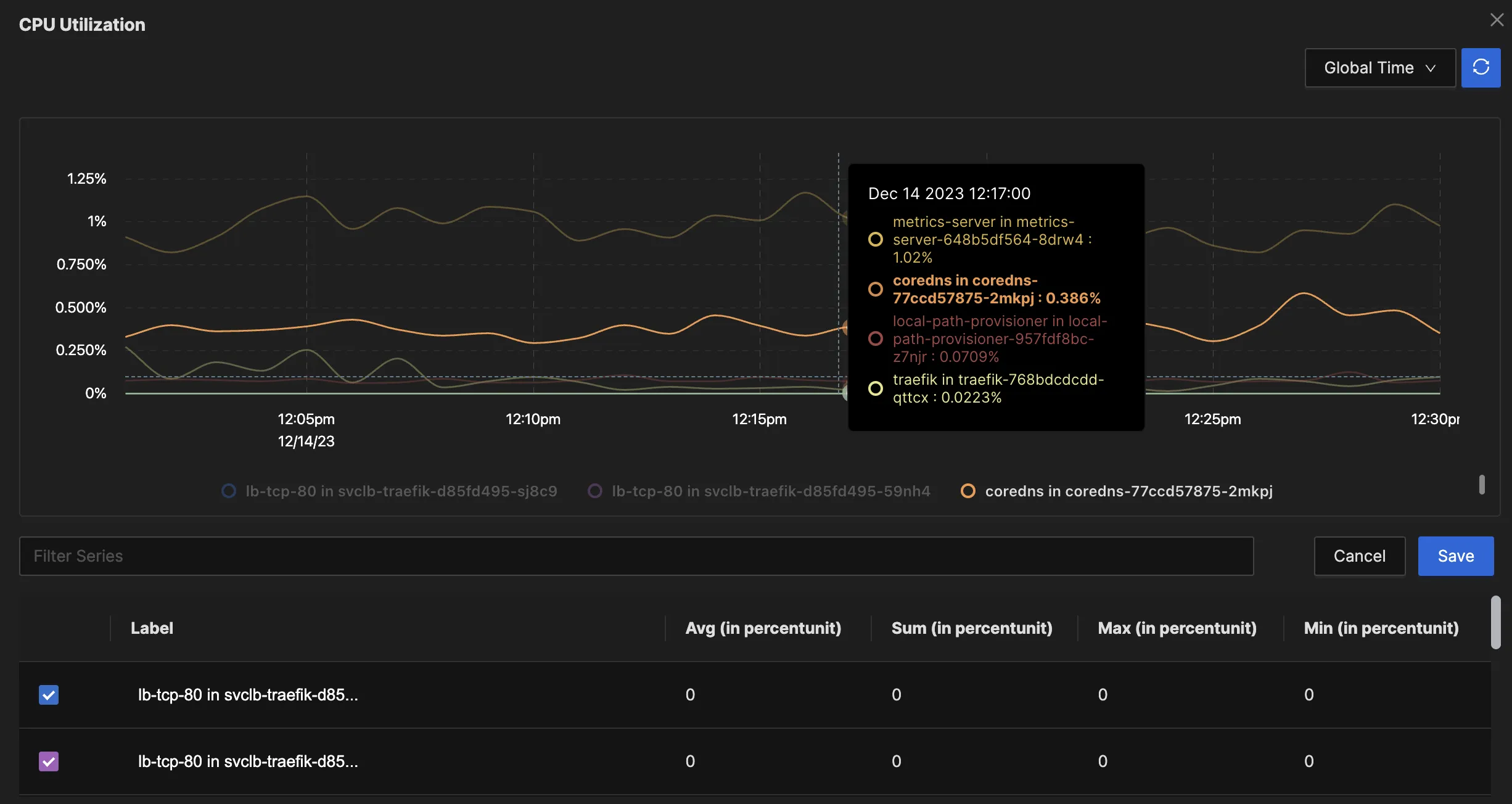
SigNoz 仪表板显示的 K8s Pod CPU 利用率
时间序列图起源于最古老的监控工具之一,名为 MRTG(Multi-Router Traffic Grapher)。MRTG 通常每 5 分钟使用 SNMP(Simple Network Monitoring Protocol)收集数据,以图形方式显示路由器接口的利用率。随后,SNMP 在 Linux(甚至是 MS Windows)上变得流行,以在定期轮询间隔内收集各种指标。尽管 SNMP 仍然流行,但相较于新方法(包括 OTEL 收集器的基于代理的监控、REST API 和流式遥测),它不再是首选。
两种常见的指标类型与利用率和饱和度相关。利用率指标指示资源使用的百分比,例如 CPU 和内存利用率,或应用服务器工作线程的使用情况。与此同时,饱和度指标反映了对资源争用的程度。例如,磁盘队列长度指示在给定间隔内超出磁盘处理能力的过多工作量。在这里,虽然利用率可能显示为 100%,但饱和度揭示了超出系统处理能力的待处理工作负荷。
跟踪提供了随时间发生事件的洞察。在 APM 和 OpenTelemetry 的背景下,这通常涉及将库嵌入代码中,或使用分析器/代理对应用程序和运行时进行分析。关于如何将 Spring Boot 与 OpenTelemetry 和 SigNoz 集成以实现可观测性的三大支柱,请参考我的《Spring Boot 监控》文章。
典型的跟踪示例是对 Web 前端的 HTTP 请求,涉及多个任务以完成并返回响应。考虑一个 HTTP POST 请求,用于向所有者的个人资料中添加新宠物。这个请求包含 25 个工作单元(Spans),每个单元包含有关工作单元的详细属性、SQL 语句、线程 ID 和服务详细信息。
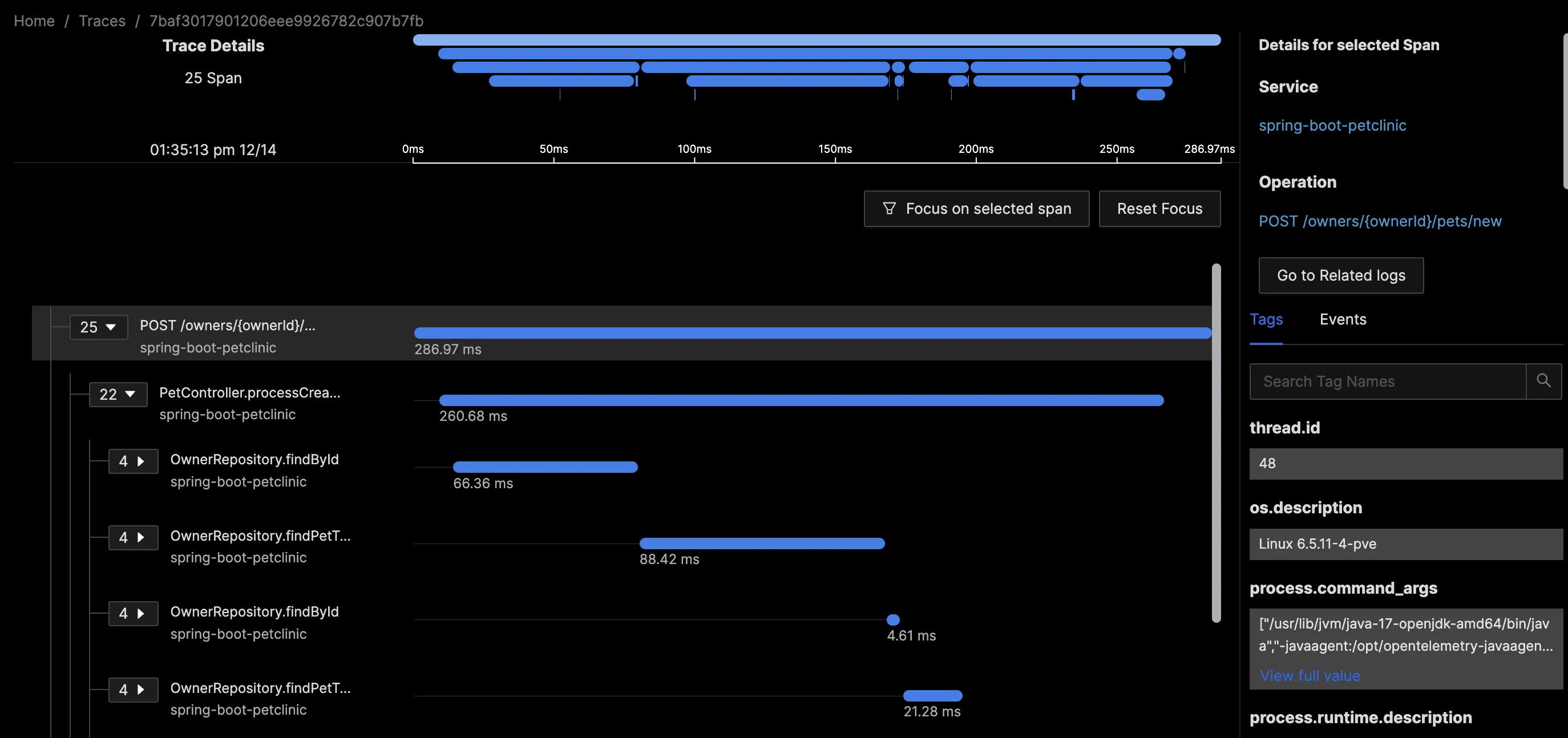
示例 HTTP 跟踪
尽管可以从日志中推导出其中一些信息,但跟踪以一种上下文和标准化的格式呈现这些工作单元。类似 Flamegraphs 和 Gantt 图的跟踪可轻松可视化整个请求,因为它在复杂的分布式设置中穿越不同组件。这种方法消除了需要搜索多个服务器、容器和日志文件以跟踪单个请求的需求,从而节省大量工作时间。
作为三大可观测性支柱中最古老的一支,日志已从基本的 'print' 语句演变为复杂的结构化格式。尽管它们固有的灵活性和非结构化的性质最初使分析变得具有挑战性,但现代日志库、框架和标准显著提高了它们的可用性。像 SigNoz 这样的工具提供了日志流水线,以转换日志以适应您的查询和聚合需求。
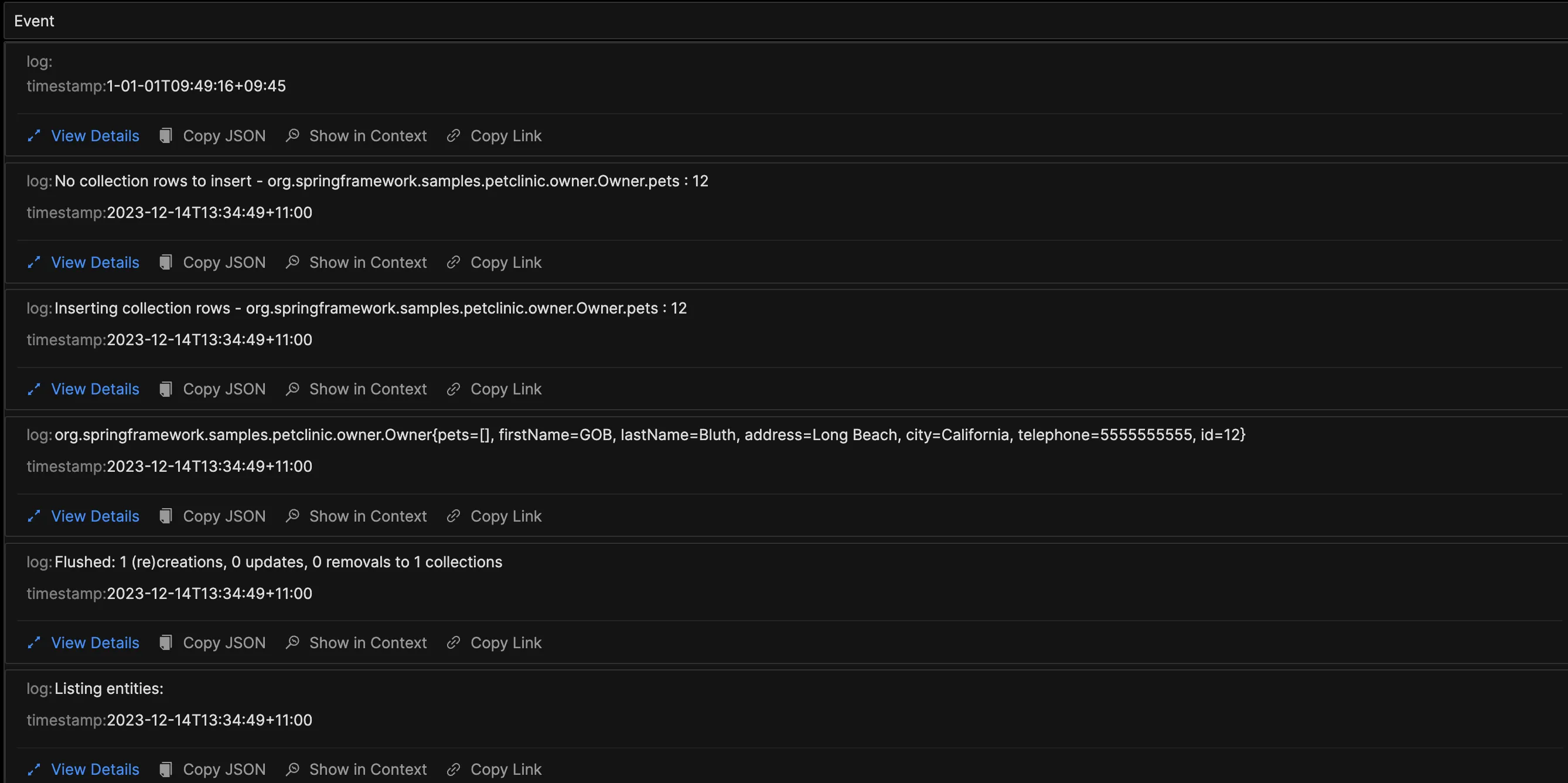
按跟踪 ID 聚合的示例日志
类似 Logback 和 Log4J 这样的框架已经简化了日志的修改,以便 OpenTelemetry 和 SigNoz 轻松消费,消除了需要单独的日志流水线。例如,Logback 的结构化字段、属性和值可以由 SigNoz 查询,以过滤不相关的数据或隔离与特定跟踪或跨度 ID 相关的日志。
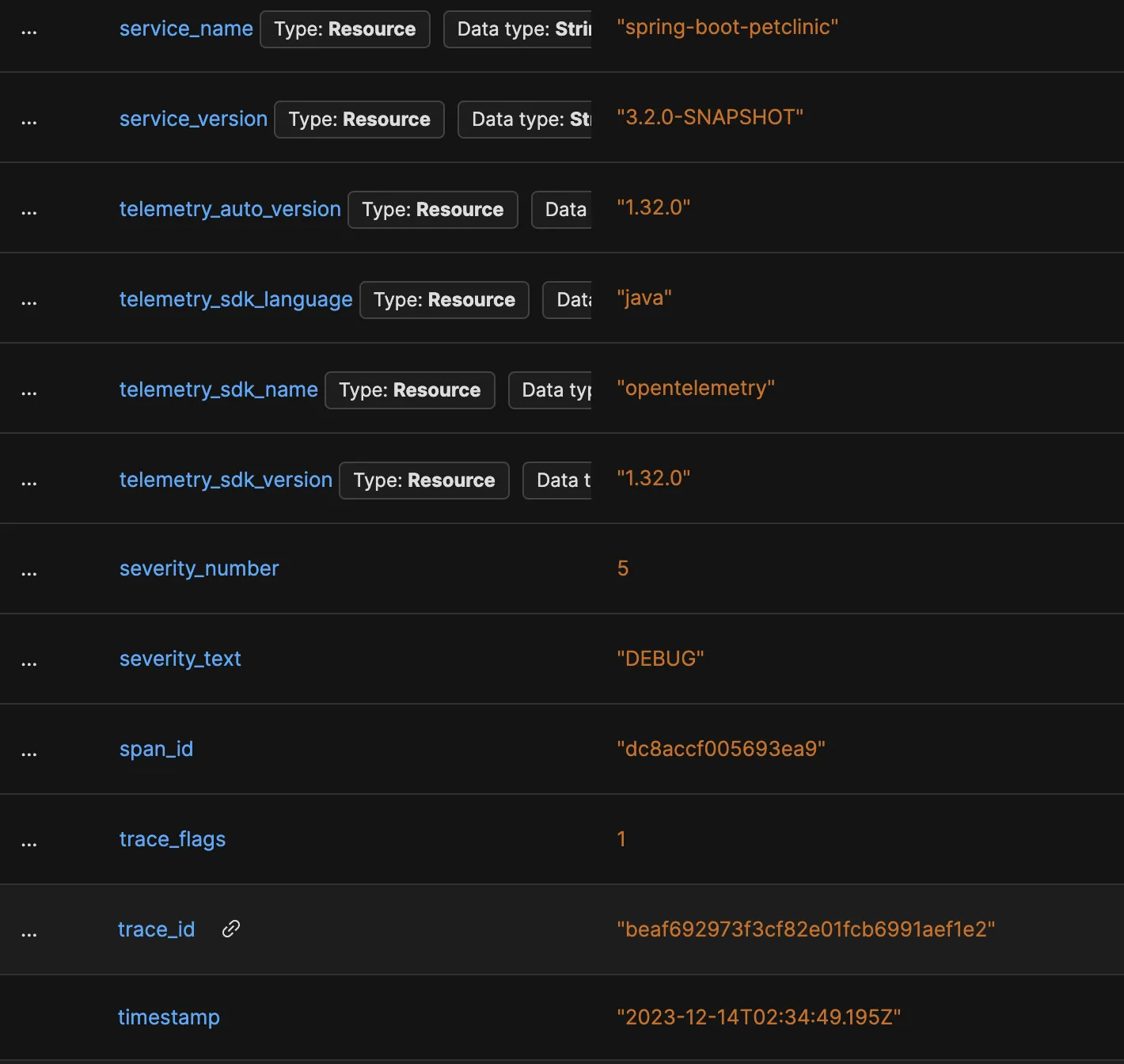
示例日志显示跟踪和跨度 ID
可观测性已经从仅仅收集和分析三大支柱(日志、指标和跟踪)发展出来。"上下文(Context)" 被越来越认识为在调试复杂的分布式系统中的关键组成部分,它补充了传统的三大支柱:指标、日志和跟踪。
上下文可以被称为可观测性的第四支柱 - 关联不同的信号,并为可观测性的三大支柱提供更多信息。
在故障排除中,上下文至关重要。它连接了指标、日志和跟踪中的不同信息片段。这种相互关联有助于快速定位问题、理解它们的影响并制定更有效的解决方案。
将上下文与可观测性的三大支柱集成:
- 关联的日志和跟踪:通过注入跟踪和跨度标识符,可以将日志和跟踪相关联。使用跟踪了解有问题请求的流程,并确定问题发生在旅程的哪个阶段。然后,深入了解这些特定跨度或服务的日志,以获取详细的错误信息。
- 具有上下文的指标:与仅有数量数据相比,指标在与上下文相结合时变得更有意义。例如,当您知道哪个部署或更改触发了资源使用率的激增时,资源使用率的激增就更具信息性。
可观测性的未来趋势是利用人工智能进行基于学习模式的快速数据解释,以优先处理关键信息,站点可靠性工程(SRE)和可观测性团队,同时过滤掉不太重要的数据。这种方法简化了对最具影响力问题的关注。此外,人工智能的作用还包括自动化对标准事件的例行响应,例如收集相关的调试信息和重新启动服务。这种自动化减少了在恢复服务方面人为干预的需求,使团队能够集中精力进行根本原因分析(RCA)和预防性策略。
在可观测性中,可视化是关键,它将数据转化为对各种受众都易于理解的故事。仪表板应该向各个技术水平和主题专业知识的用户传达关键信息,而不仅仅是专家。
组织面临的最大挑战之一是创建能够在单个视图中显示所有可能信息的仪表板。如果需要阅读仪表板才能理解它,那么它不是仪表板,而是报告。
有效的仪表板需要对目标受众有同理心。例如,高管可能只想知道服务是否可用和性能良好,因此可能只需要一个交通灯。相比之下,服务所有者可能从更详细的指标中受益,例如用户数量、平均性能以及 p95 和 p99 值,以识别异常值。
“有效仪表板的关键:简单、可读性强、以用户为中心的设计。”
SigNoz 中的简单 CPU 和线程仪表板
成熟度指数是一种有效的基准我们应用和服务的方式,了解可以采取哪些措施来降低数字体验的风险。为了评估成熟度,我们必须评估与服务相关的人员、流程和技术。
首先从人员方面着手,评估团队的可观测性技能以及组织嵌入可观测性实践的承诺。
流程应该减少对特定个体的依赖,增强业务或服务的弹性。例如,服务降级计划可能会概述在瞬态事件期间从三大支柱收集信息的步骤。
技术不仅涉及工具;它涉及充分利用这些工具来充分仪表化服务。以 Spring Boot 监控为例,该文章讨论了使用三大支柱进行仪表化的情况。
对于这些要素的每一个,我们将使用成熟度指数应用当前状态与期望状态的对比,以帮助我们集中精力投资于哪些服务。
我们呈现了现代云原生应用中可观测性不断发展的全面视图。它超越了传统监控的范围,突显了可观测性如何变得更加动态,并通过将上下文作为第四支柱的一部分而更加相互连接。可观测性的未来被视为越来越依赖人工智能和有效的数据可视化,以使复杂的数据变得可理解且可操作。
对于希望增强数字体验和系统可靠性的组织来说,拥抱可观测性的这些不断发展的方面至关重要。关键是将这些实践融入其运营文化,确保一个强大、响应迅速且具有弹性的技术生态系统。