
译自 Detect Slow SQL Queries on Kubernetes Before Your Customers Do。作者 Aral Yekta Yarimca 。
在今天快速发展的技术领域中,SQL 数据库与 Kubernetes 集群的集成变得越来越普遍。这种融合在释放可扩展性和效率的新视野的同时,也引入了在监视和管理 SQL 查询方面的独特挑战。
在本博客中,我们深入研究使用 Ddosify 在 Kubernetes 集群中监视 SQL 查询的复杂性。
我们将:
- 部署一个依赖于 Postgres 的示例 Django 应用程序
- 在该应用程序上执行查询,并通过延迟监视执行的查询
注意:本博客文章是关于在 Kubernetes 集群中监视 SQL 查询,但相同的原则也可以扩展到其他协议,如 HTTP、HTTP/2、gRPC 和 RabbitMQ。在这里检查支持的协议。
注意:我假设您已经拥有一个 Kubernetes 集群并在 Ddosify 中使用 Alaz 进行设置。如果您需要更多帮助,请按照这里的说明操作。
现在我们在 Ddosify 中有了我们的集群,请部署我们的示例应用程序以开始监视。本文引用的所有源代码都在这里可用。
执行以下命令:
kubectl apply -f https://raw.githubusercontent.com/ddosify/blog_examples/main/008_slow_sql_queries/sample_apps.yaml这将部署以下两个应用程序:
- Postgres 服务器(postgres)
- 一个示例 Django 应用程序(testserver)
- 这个应用程序是一个简单的 Django 服务器,操作包含 5 个数据库模型和 2 个端点的足球联赛数据:
- 模型
- League(联赛)
- Team(球队)
- Match(比赛)
- Player(球员)
- Spectator(观众)
- 模型的详细信息可以看这里。
- 端点:
- http://localhost:8200/football/join
- GET: 连接 Spectator、Match、Team、League、Player 表,并返回这些行的总计数。
-
http://localhost:8200/football/data
- GET: 返回表 Player、Spectator、Match、Team、League 的总行数。
- POST: 生成以下模拟数据:10 个 League 对象、10 个 Team 对象、100 个 Player 对象、100 个 Match 对象、10000 个 Spectator 对象。
- DELETE: 清除 League、Team、Player、Match、Spectator 表中的对象。
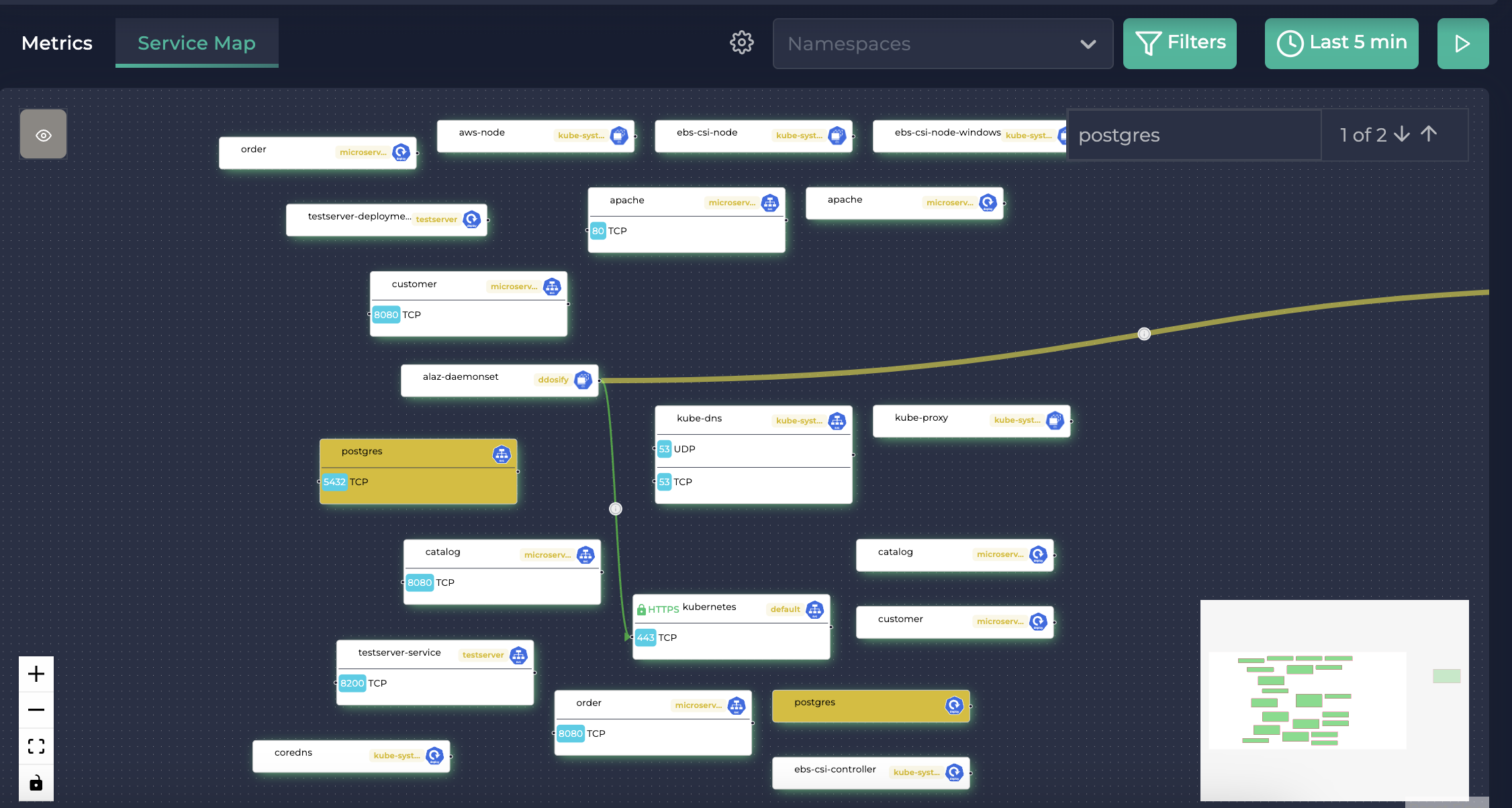
安装完成后,您应该能够在服务地图中找到 postgres 和 testserver。查看 Ddosify 文档以获取安装说明,并参阅此博客文章以获取有关使用 Ddosify 进行 Kubernetes 监控的更多信息。
当搜索 Postgres 时的服务地图
当搜索 Testserver 时的服务地图
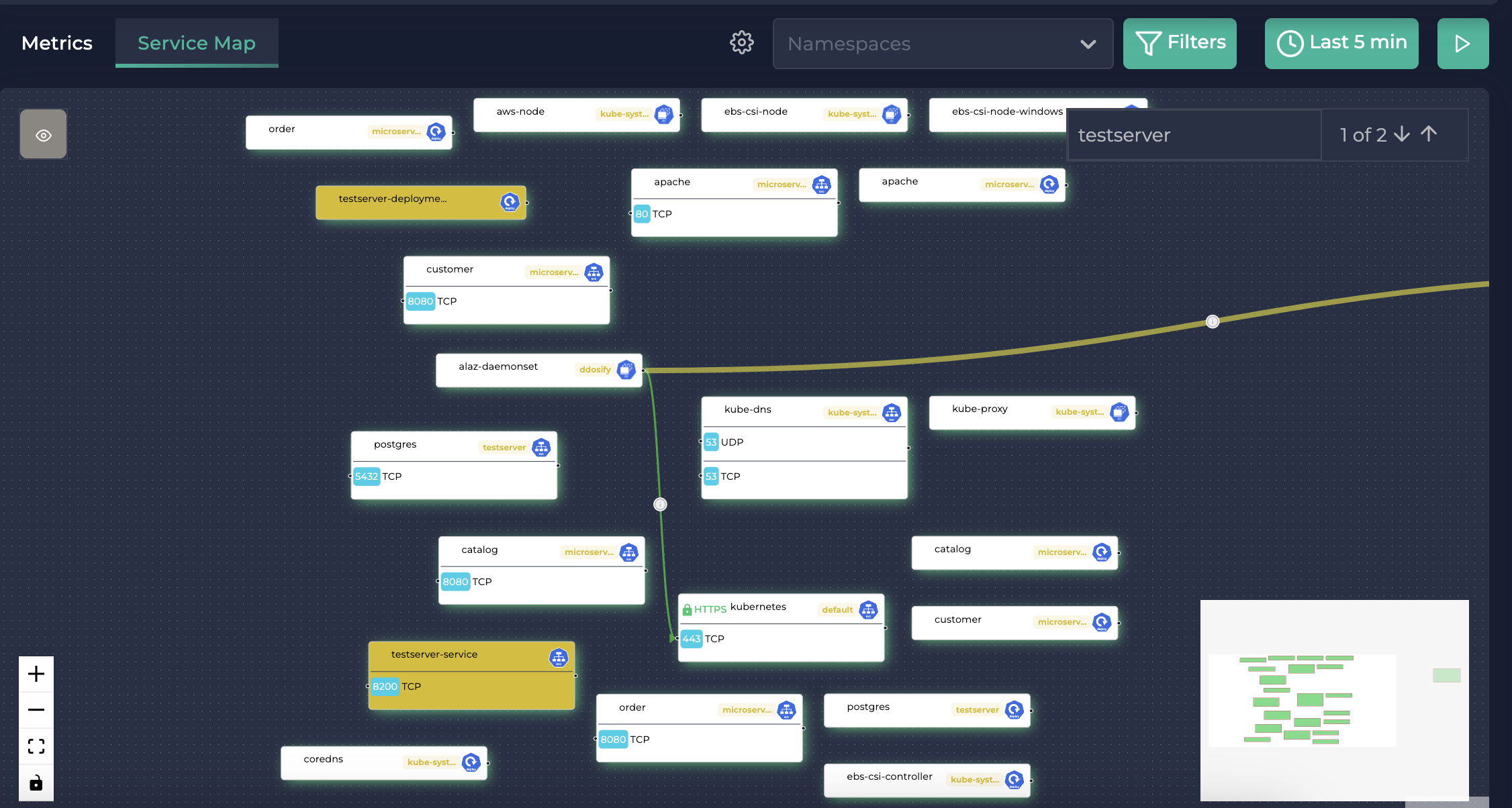
现在,让我们检查是否可以查看它们之间的流量。
端口转发到 testservice:
kubectl port-forward --namespace testserver service/testserver-service 8200:8200运行以下命令以生成模拟数据:
curl -X POST http://localhost:8200/football/data这将花费一些时间,因为它生成数千行数据。可能需要长达 30 秒的时间。
然后,您将看到此连接在服务地图中创建(请注意边缘是红色的,表示延迟很高):
生成的流量
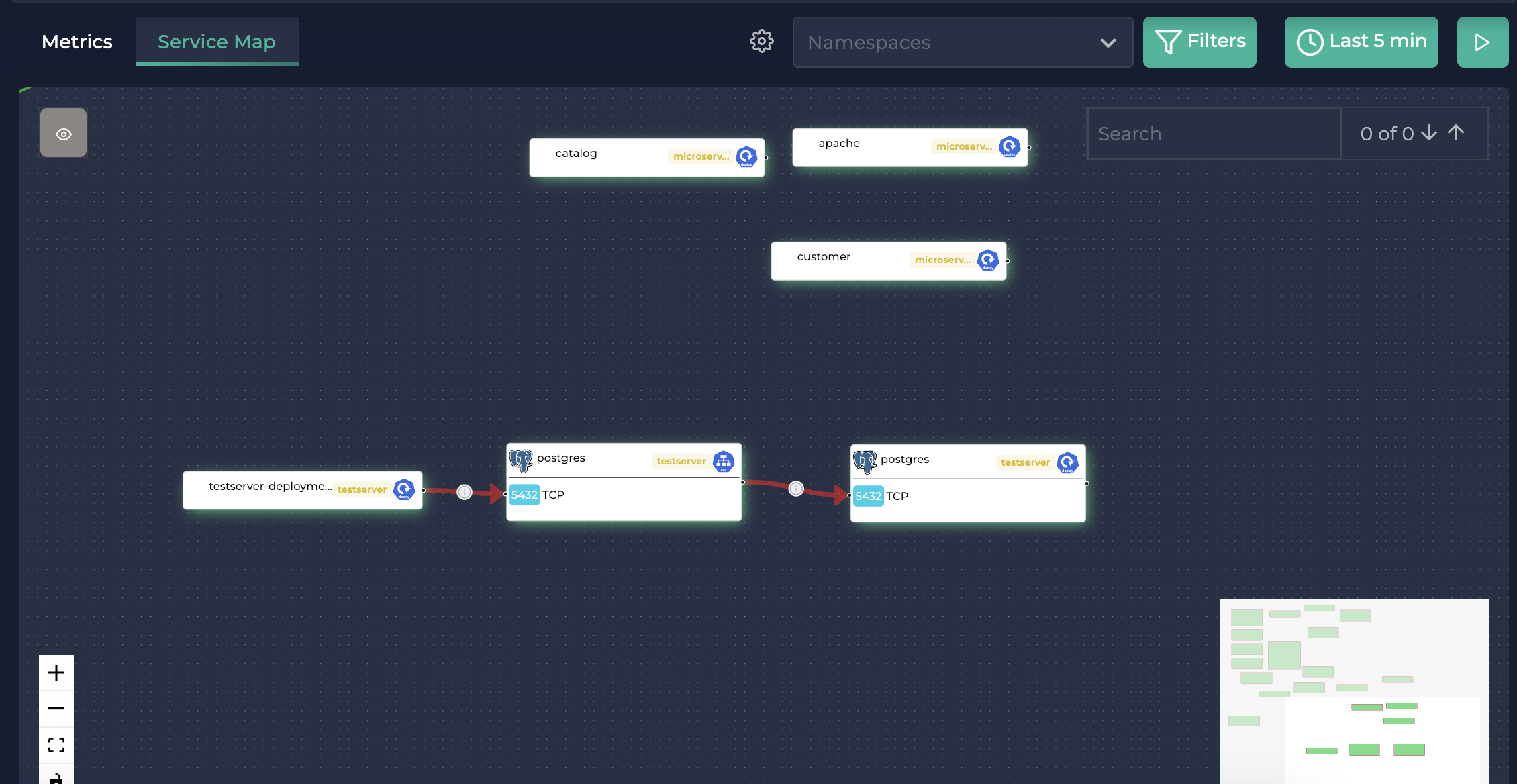
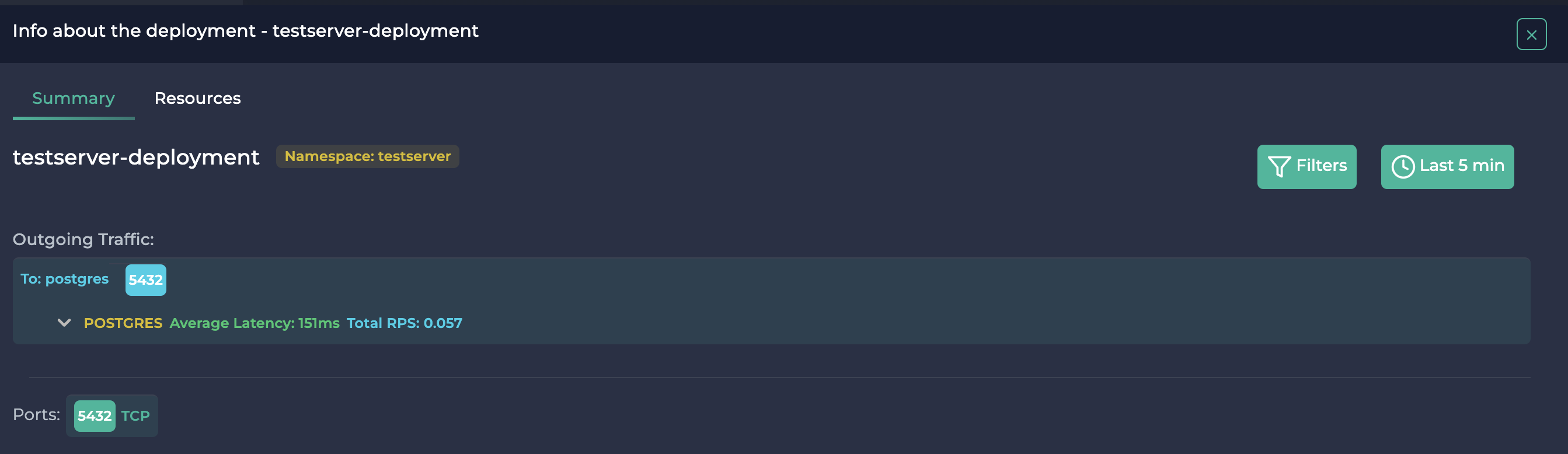
点击 testserver-deployment(相同的流量也可以在 postgres 服务和 postgres 部署上查看)
Testserver deployment
然后点击 POSTGRES
Postgres 流量
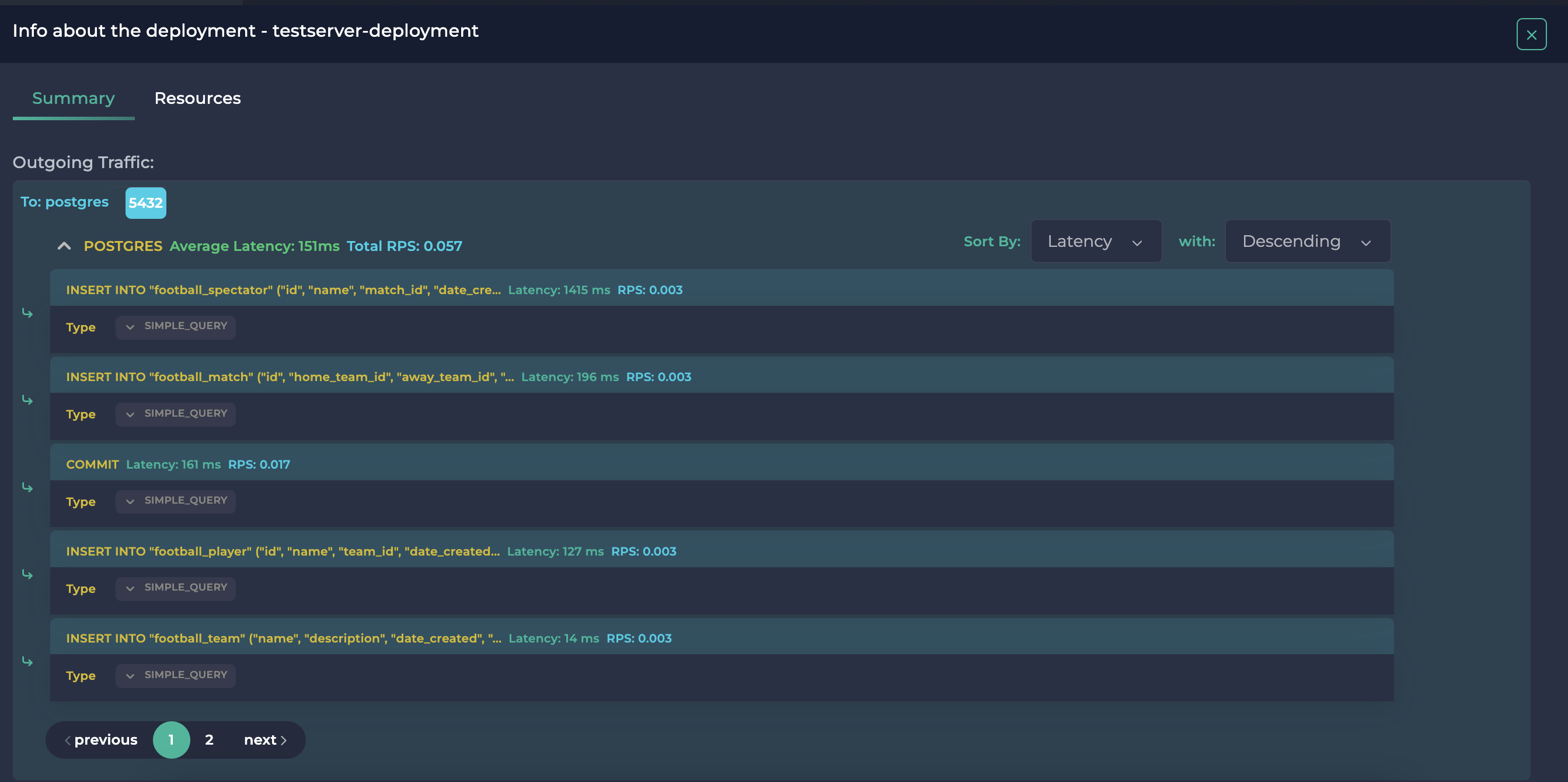
在这里,您将看到执行的插入查询。您还可以通过点击它们查看实际查询及其延迟以及它们的 RPS。
详细的 Postgres 流量
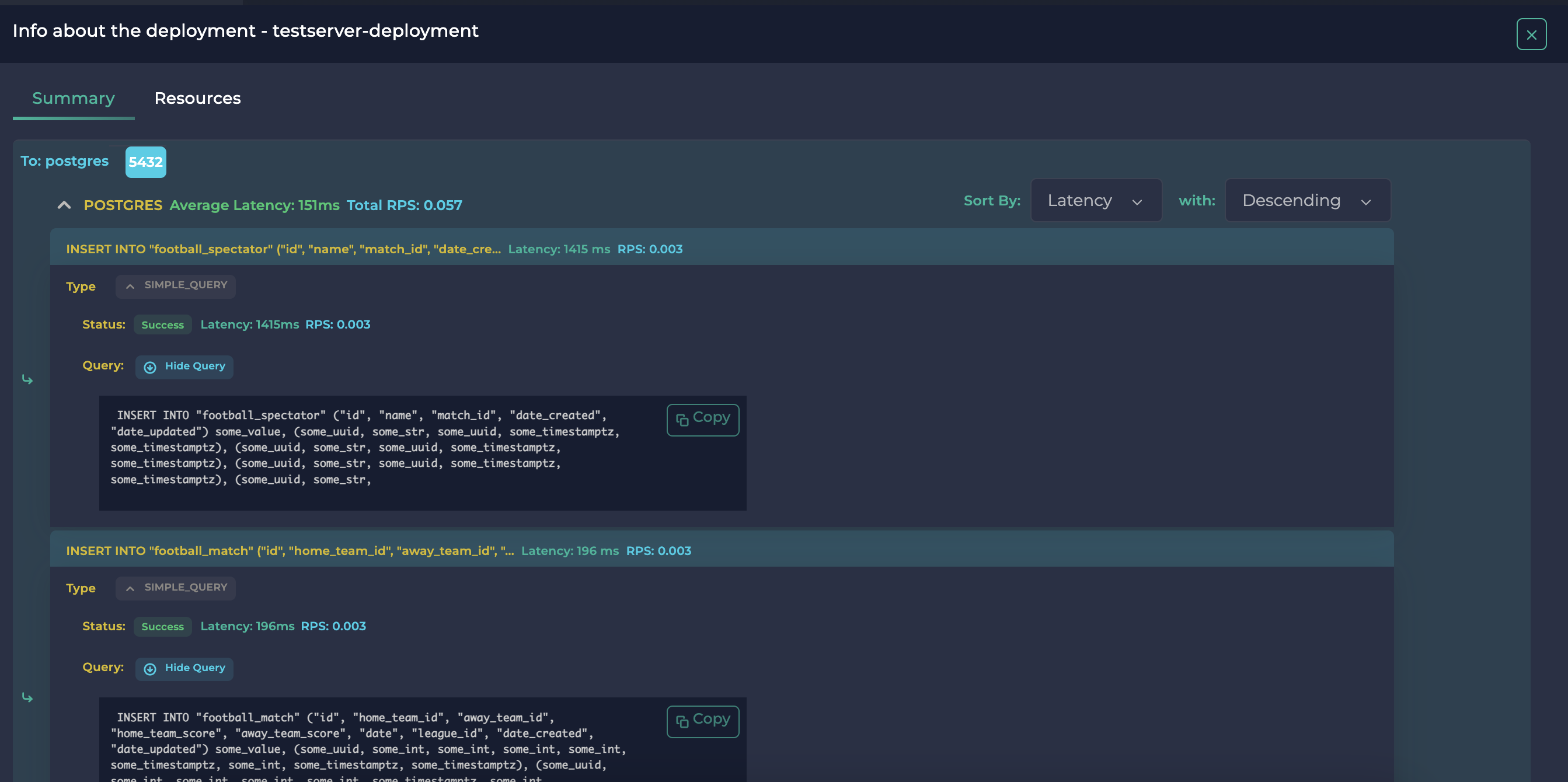
默认排序是最大延迟优先。如果您愿意,您还可以使用右上角的排序选择器查看最大 RPS 或最小延迟/ RPS。
在这里,我们可以看到,虽然将新数据插入到 Match 中花费了 196 毫秒,但将新数据插入到 Spectator 中几乎慢了 7 倍,达到了 1415 毫秒。
如果您想查看当前数据的计数,可以使用相同的 GET 端点:
curl -X GET http://localhost:8200/football/data这将返回:
{
"leagues": 100,
"teams": 1000,
"players": 10000,
"matches": 10000,
"spectators": 100000
}然后,您将在资源详细信息中开始看到 Select 查询:
包括 Select 查询的 Postgres 流量
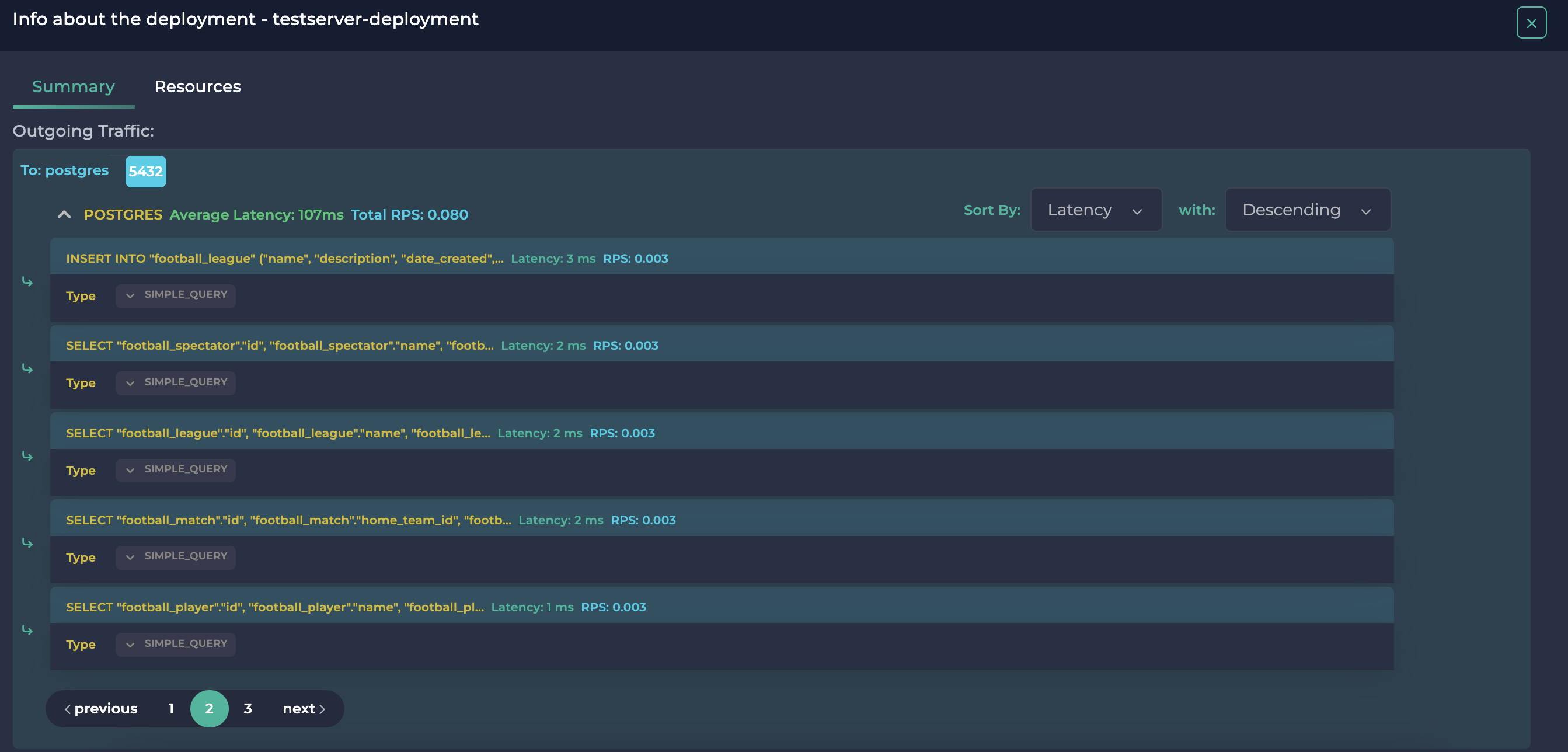
您可以看到 Select 查询所花费的时间没有插入查询多。
让我们也看一个昂贵的查询。使用以下端点:
curl -X GET http://localhost:8200/football/join/此端点连接了所有 5 个表并对它们进行分组。其实际查询如下:
SELECT
League.name AS league_name,
HomeTeam.name AS team_name,
Player.name AS player_name,
Match.home_team_score,
Match.away_team_score,
COUNT(DISTINCT Spectator.id) AS spectator_count
FROM
football_match as Match
JOIN
football_league as League ON Match.league_id = League.id
JOIN
football_team AS HomeTeam ON Match.home_team_id = HomeTeam.id
JOIN
football_team AS AwayTeam ON Match.away_team_id = AwayTeam.id
JOIN
football_player as Player ON Player.team_id = HomeTeam.id OR Player.team_id = AwayTeam.id
JOIN
football_spectator as Spectator ON Spectator.match_id = Match.id
GROUP BY
Match.id, League.name, HomeTeam.name, AwayTeam.name, Player.name
ORDER BY
League.name, HomeTeam.name, COUNT(DISTINCT Spectator.id) DESC访问此端点后,可能需要一些时间(约 6 秒)来计算结果。然后,您可以在 Ddosify 中查看此查询:
连接查询
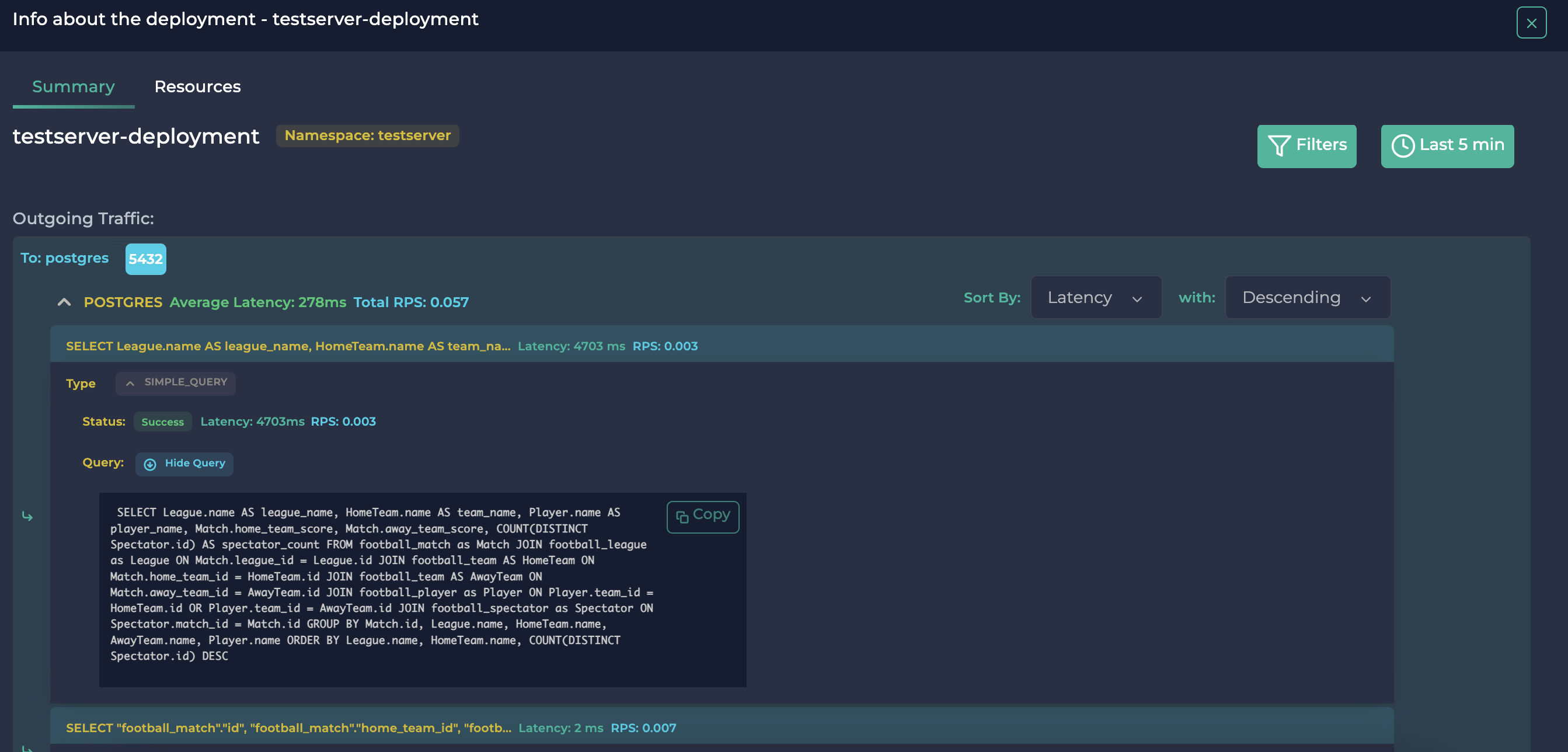
正如您所见,完成该查询花费了 4703 毫秒。详细部分的查询也与在 Django 服务器上运行的实际查询相匹配(如果查询包含文字,它们将被占位符替换)。
如果我们想要查看最快的查询,我们可以在协议右上角的“排序方式”选项更改为“升序”。将显示如下内容:
按升序延迟排序的 SQL 查询,第 1 页
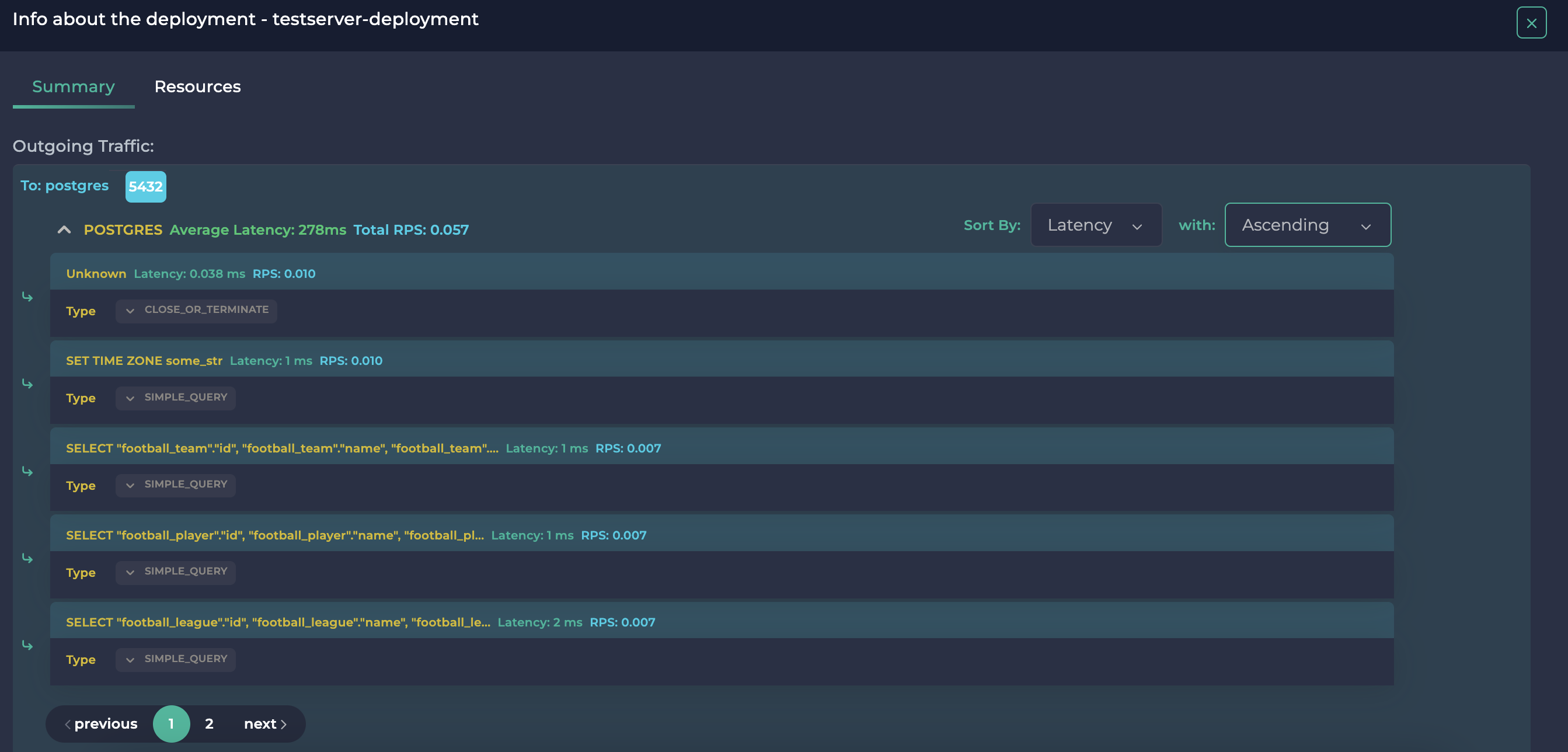
按升序延迟排序的 SQL 查询,第 2 页
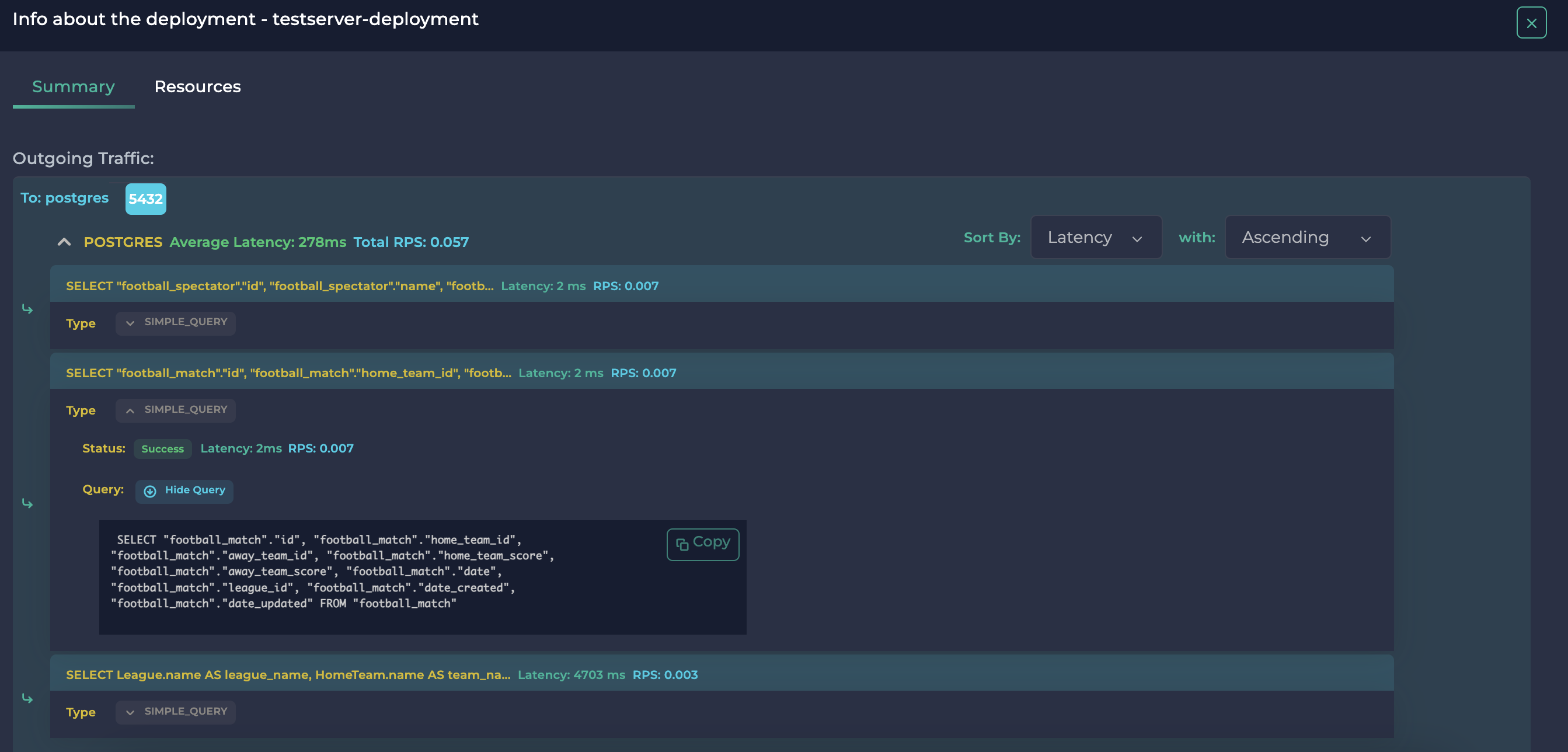
在这里,我们可以看到在 http://localhost:8200/football/data/ 的 GET 方法中执行的选择查询非常快,最多只需 2 毫秒。然而,在 http://localhost:8200/football/join/ 中的连接查询大约花了 5 秒钟。如果这是一个实际的应用程序,延迟高达 2500 倍意味着存在瓶颈或低效的查询。因此,我们能够利用 Ddosify 监控我们 Kubernetes 集群中的 SQL 查询,以确保其健康。
总的来说,在系统中使用 Ddosify 监控 SQL 查询的性能,无论是快速的还是慢速的,都是确保数据库健康和整体应用程序性能的重要步骤。通过了解如何有效地利用 Ddosify,您可以
- 识别瓶颈,
- 调整 SQL 语句,
- 并最终提供更平稳、更可靠的用户体验。
请记住,持续监控和分析 SQL 查询不仅仅是为了解决即时问题;它是为了积极塑造一个经受住时间和用户需求考验的强大、高效的系统。如果您想了解如何使用 Ddosify 使您的 Kubernetes 集群在各种情况下都能经受住考验,可以查阅我们的文档。
如果您发现 Ddosify 平台有用,请给予我们的 GitHub 存储库点赞。