
一个关于存活、就绪和深度健康检查陷阱的故事。
译自 Distributed Systems Horror Stories: Kubernetes Deep Health Checks。作者 MATT BOYLE 。
分布式系统通常被描述为一把双刃剑。网上有许多优秀的文章阐述分布式系统糟糕和伟大的方面。这篇文章并非如此。我通常倾向于相信分布式系统在适当的地方,但这篇博客文章(以及后续的两篇文章)的目标是与您分享一些我在分布式系统中出错导致广泛影响的故事。
在这篇第一篇文章中,我将分享一个错误,我已经在多个公司看到过这个错误,可能导致连锁故障。我称之为 Kubernetes 深度健康检查。
Kubernetes 是一个容器编排平台。它是一个受欢迎的选择,用于构建分布式系统,原因充分;它在基础设施之上提供了明智和云原生的抽象,使开发人员能够配置和运行他们的应用程序,而不必成为网络专家。
Kubernetes 允许并鼓励您配置几种不同类型的探针;存活、就绪和启动探针。概念上,这些探针很简单,描述如下:
- 存活探针用于告诉 Kubernetes 重启一个容器。如果存活探测失败,应用程序将重启。这可以用来捕捉死锁等问题,使应用程序更可用。我在 Cloudflare 的同事曾撰文阐述我们如何使用它来重启“卡住的” Kafka 消费者,文章链接在此。
- 就绪探针仅用于基于 HTTP 的应用程序,用于指示容器已准备好开始接收流量。当 Pod 中所有的容器就绪时,Pod 被认为已准备好接收流量。如果 Pod 中的任何容器就绪探测失败,它将从服务负载均衡器中删除,不会接收任何 HTTP 请求。就绪探测失败不会像活跃性探测失败那样导致 Pod 重启。
- 启动探针通常建议用于需要花一段时间启动的遗留应用程序。在应用程序通过启动探测之前,活跃性和就绪探测不予考虑。
本文的其余部分,我们将着重探讨基于 HTTP 的应用程序的就绪探针。
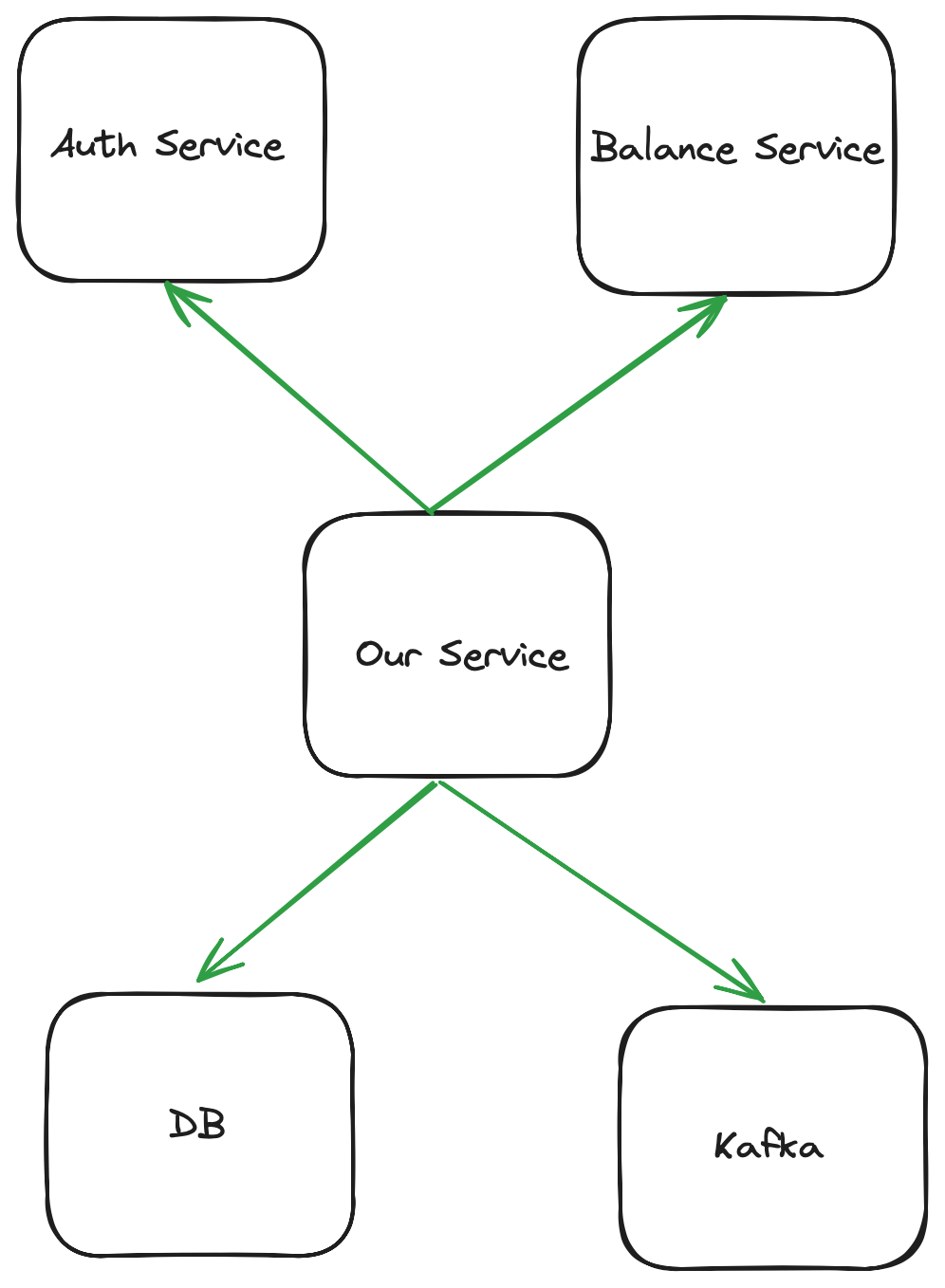
这看起来像一个相当简单的问题,对吧?“当我的应用程序能够响应用户的请求时,它就是准备就绪的”,您可能会回答。让我们考虑一个支付公司的应用程序,它允许您在应用程序中检查余额。当用户打开移动应用程序时,它会向后端的许多服务之一发出调用。接收请求的服务负责:
- 通过检查身份验证服务来验证用户的令牌。
- 调用持有余额的服务。
- 向 Kafka 发出 balance_viewed 事件。
- (通过不同的端点)允许用户锁定其账户,这将更新服务自己数据库中的一行。
因此,为了成功为客户提供服务,您可以认为我们的应用程序依赖于:
- 身份验证服务的可用性。
- 余额服务的可用性。
- Kafka 的可用性。
- 我们的数据库可用。
其依赖关系图看起来像这样:
因此,我们可以编写一个就绪端点,在所有以下内容可用时返回 JSON 和 200:
{
"available":{
"auth":true,
"balance":true,
"kafka":true,
"database":true
}
}
在这种情况下,available 可以意味着不同的事情:
- 对于 auth 和 balance,我们检查它们的就绪端点是否返回
200。 - 对于 Kafka,我们检查是否可以向名为 healthcheck 的主题发出事件。
- 对于数据库,我们执行
SELECT 1;
如果任何一个失败,我们会为 JSON 键返回 false,并返回 HTTP 500 错误。这被视为就绪探测失败,并会导致 Kubernetes 将该 Pod 从服务负载均衡器中移除。乍一看这似乎是合理的,但这可能导致连锁故障,可以说这损害了微服务最大的优点之一(隔离故障)。
想象以下情景,身份验证服务已经关闭,我们公司的所有服务都将其列为深度就绪检查:
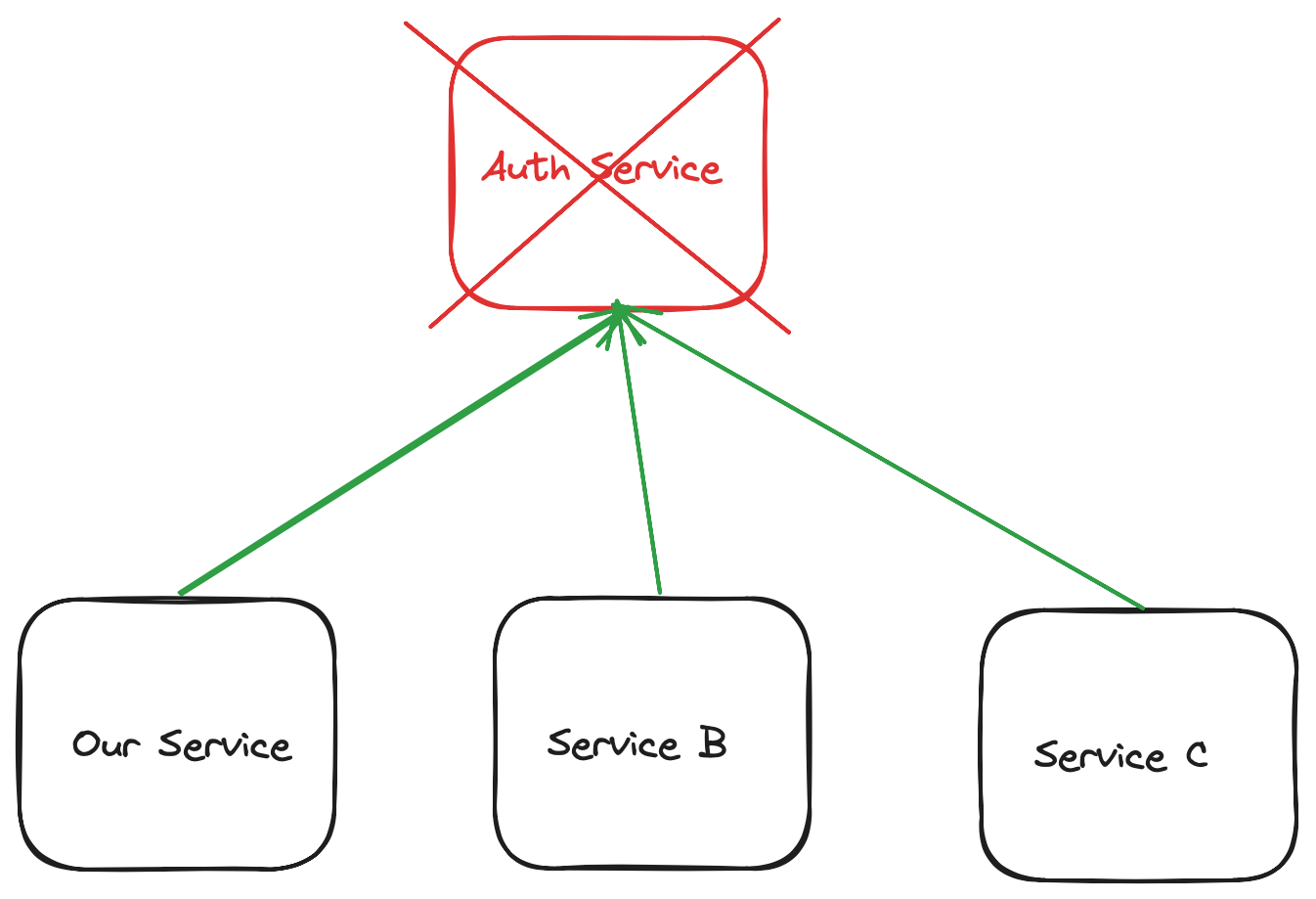
身份验证服务失败导致我们服务的所有 Pod 都从负载均衡器中删除;我们遭受完全中断:
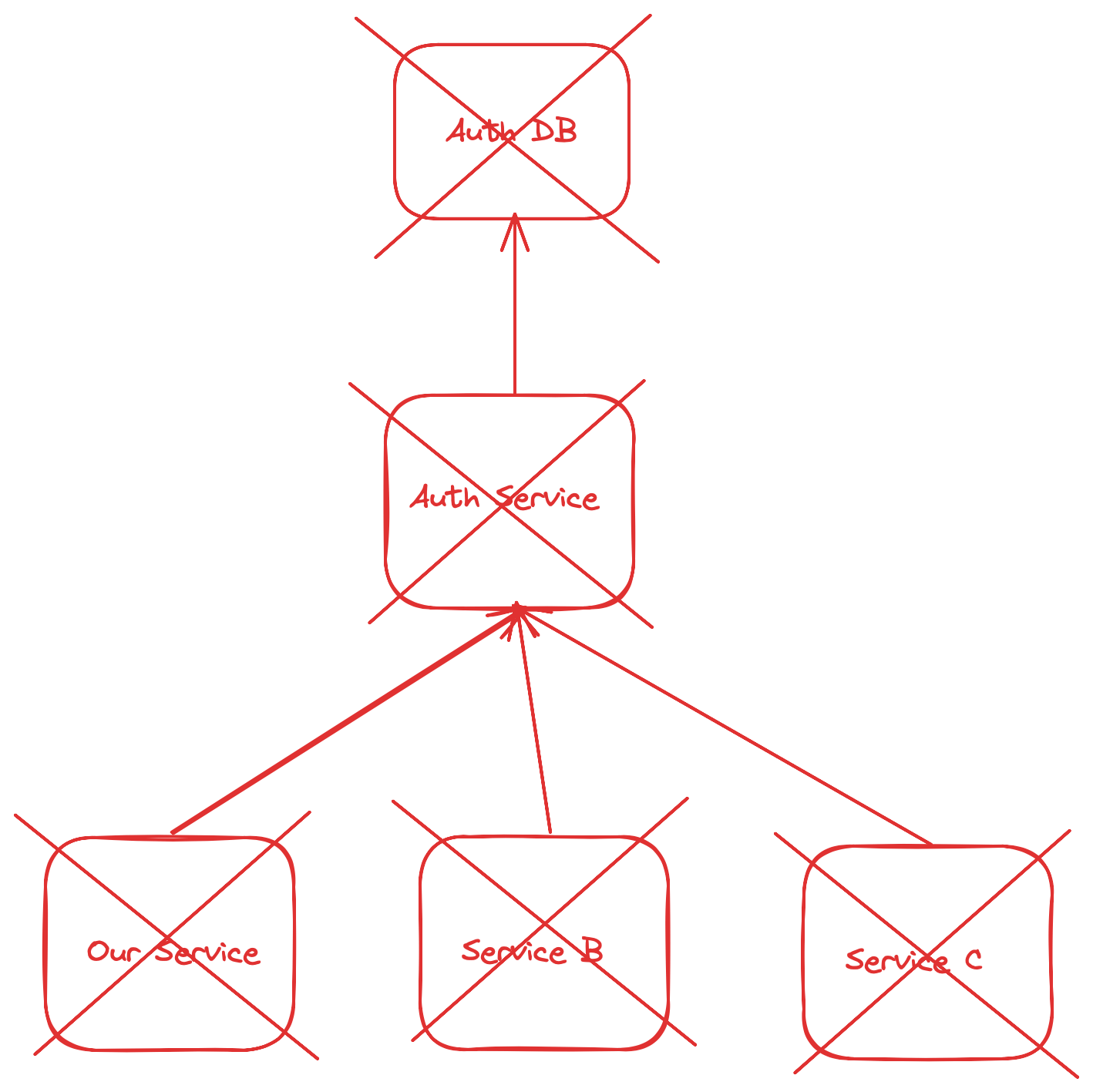
更糟糕的是,我们可能几乎没有关于此失败原因的指标。由于请求没有到达我们的 Pod,我们无法增加代码中精心设置的 Prometheus 指标,而是需要查看集群中标记为未就绪的所有 Pod。
然后,我们必须调用它们的就绪端点来确定是哪个依赖导致的,并跟踪树;身份验证服务可能由于其自己的依赖之一关闭而关闭。
类似这样:
与此同时,我们的用户会看到这个:
upstream connect error or disconnect/reset before headers. reset reason: connection failure
不是一个很友好的错误信息,对吧?我们可以而且必须做得更好。
如果您的应用程序可以服务响应,则它就是准备就绪的。它提供的响应可能是失败响应,但这仍在执行业务逻辑。例如,如果身份验证服务关闭,我们可以(并且应该)先以指数退避重试,同时增加失败的计数器。如果我们仍然无法获取成功响应,我们应该向用户返回 5xx 错误代码并增加另一个计数器。如果任一计数器达到您认为不可接受的阈值(由 SLO 定义),则可以声明一个范围明确的事件。
与此同时,您的业务中应该会有部分(希望如此)可以继续运行,因为并非所有内容都依赖于关闭的服务。
一旦事件得到解决,我们应该考虑我们的服务是否需要该依赖,以及我们可以做些什么工作来清除它。我们可以转向更无状态的身份验证模型吗?我们应该使用缓存吗?我们可以在一些用户流中断路由吗?我们应该将一些不需要如此多依赖的工作流程剥离到另一个服务中,以进一步隔离未来的故障吗?
根据我的对话,我预计这篇博文会产生极大分歧。有些人会认为我是一个白痴,因为我曾经实现过深度运行状况检查,因为这肯定会导致连锁故障。其他人会在他们的 Slack 频道中分享这篇文章,并询问“我们的就绪检查做错了吗?”,然后一位高级工程师会出现并争辩他们的情况特殊,适合他们(也许确实如此,如果是这样,我很乐意听听您的使用案例)。
当我们使事物分布式时,我们增加了复杂性。在处理分布式系统时,总是值得保持悲观并以失败优先的思维方式思考。这种方法不是期望失败,而是对失败做好准备。这是关于理解我们系统的互联性质以及单点故障可能产生的连锁反应。
我的 Kubernetes 故事的重要启示不是要避免深度健康检查,而是要小心使用它们。平衡至关重要;我们需要权衡彻底的健康检查的好处与潜在的广泛系统影响。从我们自己和他人的错误中学习使我们成为更好的开发人员,并能在系统复杂性面前更具弹性。我分享我的故事,希望您也分享您的故事。
我期待从您这里学习。
— Matt