
监控 Docker 容器指标对于理解容器的性能和健康情况至关重要。OpenTelemetry Collector 可以收集 Docker 容器指标,并将其发送到您选择的后端。在本教程中,您将安装一个 OpenTelemetry Collector 来收集 Docker 容器指标,并将其发送到 SigNoz,这是一个用于监控和可视化的 OpenTelemetry 原生 APM。
译自 Monitoring Docker Containers Using OpenTelemetry [Full Tutorial]。作者 Abhishek Kothari 。
如果您想直接跳入实现,请从本节的前提条件开始。
Docker 容器化已经变得非常流行,可以使应用程序工作负载具有可移植性。它们帮助开发人员摆脱服务器级依赖,并简化应用程序本身的测试和部署。随着云原生技术的采用,Docker 的采用也自然增长。这带来了对在各种计算环境上运行的基于 Docker 的容器进行监控的需求。
在各种场景下监控 Docker 容器指标非常关键,可以避免性能问题并帮助开发人员进行故障排除。容器可能会开始消耗过量的资源(CPU 或内存),影响其他容器或主机系统。
通过监控 CPU 和内存使用情况,您可以及早检测到资源饱和。这使您可以在用户体验到明显的性能下降或宕机之前,调整资源分配、优化应用程序或扩展环境。
监控 Docker 容器的一些关键原因如下:
- 资源优化: 它有助于高效分配资源并根据需求扩缩容器。
- 性能管理: 通过了解资源利用和需求,您可以优化容器内运行的应用程序性能。
- 故障排除: 它可以快速识别和解决问题,减少宕机时间并提高可靠性。
- 成本管理: 在云环境中,高效利用资源可以显著节省成本。
我们可以使用 OpenTelemetry 和支持基于 OpenTelemetry 数据的后端来有效监控 Docker 容器。OpenTelemetry 正在悄悄成为生成和收集遥测数据的开源标准。
OpenTelemetry 是一套 API、SDK、库和集成,旨在标准化遥测数据(日志、指标和追踪)的生成、收集和管理。它由云原生计算基金会支持,是可观察性领域领先的开源项目。
您使用 OpenTelemetry 收集的数据与供应商无关,并且可以以多种格式导出。我们将使用 OpenTelemetry 提供的名为 OpenTelemetry Collector 的工具来收集 Docker 容器指标。
OpenTelemetry Collector 是 OpenTelemetry 提供的独立服务。它可以用作具有大量灵活配置的遥测处理系统,用于收集和管理遥测数据。
它可以理解不同的数据格式,并将数据发送到不同的后端,这使其成为构建可观察性解决方案的通用工具。
阅读我们的 OpenTelemetry Collector 完整指南
receiver是数据进入 OpenTelemetry Collector 的方式。receiver 通过顶级 receivers 标记进行 YAML 配置。配置需要至少一个启用的receiver才能被认为是有效的。
这是一个 otlp receiver 的示例:
receivers:
otlp:
protocols:
grpc:
http:一个 OTLP receiver可以通过 gRPC 或 HTTP 使用 OTLP 格式接收数据。您可以通过 YAML 文件启用高级配置。
下面是 otlp receiver 的一个示例配置:
receivers:
otlp:
protocols:
http:
endpoint: "localhost:4318"
cors:
allowed_origins:
- http://test.com
# Origins can have wildcards with *, use * by itself to match any origin.
- https://*.example.com
allowed_headers:
- Example-Header
max_age: 7200您可以在这里找到有关高级配置的更多详细信息。
配置receiver后,必须启用它。receiver通过服务部分中的pipeline启用。pipeline由一组receiver、processor和exporter组成。
下面是一个pipeline配置示例:
service:
pipelines:
metrics:
receivers: [otlp, prometheus]
exporters: [otlp, prometheus]
traces:
receivers: [otlp, jaeger]
processors: [batch]
exporters: [otlp, zipkin]为了从 Docker 容器中收集指标,我们首先需要安装 Docker 客户端。安装完成后,我们可以运行一些简单的容器,并尝试收集与它们相关的指标。本节指导您通过 Docker 和 Docker Compose 快速设置数据库。如果您的系统上已经运行了 Docker 并启动了几个容器,则可以跳过设置。
下面的链接可以帮助您安装 Docker:
安装 Docker 后,使用以下命令启动一些容器:
docker run nginx:latest -p 8080:80 -d
docker run httpd:latest -p 8081:80 -d
docker run mysql:latest -e MYSQL_ROOT_PASSWORD=mysecretpassword -p 3306:3306 -d以上命令将在您的系统上启动 3 个容器,以便在启动 OpenTelemetry Collector 时收集一些指标。接下来,让我们开始设置 OpenTelemetry Collector。假设您正在同一台运行 Docker 容器的机器上设置 OpenTelemetry Collector。
OpenTelemetry Collector 提供了各种部署选项,以适应不同的环境和偏好。它可以使用 Docker、Kubernetes、Nomad 或者直接在 Linux 系统上进行部署。您可以在此找到所有安装选项。
我们将在这里讨论手动安装,并解决出现的任何问题。
从 OpenTelemetry Collector 发布页面为您的 Linux 或 macOS 发行版下载适当的二进制包。我们使用的是在编写本教程时可用的最新版本。
对于 MACOS (arm64):
curl --proto '=https' --tlsv1.2 -fOL https://github.com/open-telemetry/opentelemetry-collector-releases/releases/download/v0.88.0/otelcol-contrib_0.88.0_darwin_arm64.tar.gz使用以下命令在新创建的 otelcol-contrib 目录中提取 otelcol-contrib_0.88.0_darwin_arm64.tar.gz 归档文件的内容:
mkdir otelcol-contrib && tar xvzf otelcol-contrib_0.88.0_darwin_arm64.tar.gz -C otelcol-contrib在 otelcol-contrib 文件夹中创建一个 config.yaml 文件。该配置文件将允许 collector 连接 Docker socket,并有其他设置,如您想以什么频率监控容器。docker stats receiver直接与提供指标和其他相关监控详细信息的 docker socket 通信。
注意: 配置文件应该创建在解包 otel-collector-contrib 二进制文件的同一目录中。如果您全局安装了二进制文件,在任何路径上创建都可以。
receivers:
otlp:
protocols:
grpc:
http:
docker_stats:
endpoint: unix:///var/run/docker.sock
collection_interval: 30s
timeout: 10s
api_version: 1.24
metrics:
container.uptime:
enabled: true
container.restarts:
enabled: true
container.network.io.usage.rx_errors:
enabled: true
container.network.io.usage.tx_errors:
enabled: true
container.network.io.usage.rx_packets:
enabled: true
container.network.io.usage.tx_packets:
enabled: true
processors:
batch:
send_batch_size: 1000
timeout: 10s
resourcedetection:
detectors: [env, system]
timeout: 2s
system:
hostname_sources: [os]
exporters:
otlp:
endpoint: "ingest.{region}.signoz.cloud:443"
tls:
insecure: false
headers:
signoz-access-token: "{signoz-token}"
logging:
verbosity: normal
service:
pipelines:
metrics:
receivers: [otlp, docker_stats]
processors: [resourcedetection, batch]
exporters: [otlp]您需要在上述文件中将 region`` 和 signoz-token 替换为您选择的区域(针对 Signoz Cloud)和从 Signoz Cloud → Settings → Ingestion 设置获得的令牌。
在 SigNoz 仪表板中查找 ingestion 设置
上述配置还包含一个resource detection过程,可更好地识别主机属性。docker socket 路径对于基于 UNIX 的系统保持不变;但是,对于任何其他系统,您可以参考此文档以了解更多信息。
每个 Collector 版本都包含一个可运行的 otelcol 可执行文件。既然我们已经完成了配置,我们现在可以使用以下命令运行 collector 服务。
从 otelcol-contrib 中,运行以下命令:
./otelcol-contrib --config ./config.yaml如果要在后台运行它:
./otelcol-contrib --config ./config.yaml &> otelcol-output.log & echo "$\!" > otel-pid如果您想查看日志输出,我们刚刚为后台进程设置了它。您可以使用以下命令查看:
tail -f -n 50 otelcol-output.logtail 50 将从文件 otelcol-output.log 中获取最后 50 行
您可以使用以下命令停止 collector 服务:
kill "$(< otel-pid)"您应该会在大约 30 秒内在 Signoz Cloud UI 上看到指标。您可以轻松地将此仪表板 JSON 导入 Signoz 环境中,以监控 MongoDB 数据库。
完成上述设置后,您将能够在 SigNoz 仪表板中访问指标。您可以转到“仪表板”选项卡,并尝试添加新面板。您可以在此了解如何在 SigNoz 中创建仪表板。
OpenTelemetry collector 收集的 Docker 容器指标
您可以在 SigNoz 中轻松使用查询构建器创建图表。以下是将新面板添加到仪表板的步骤。
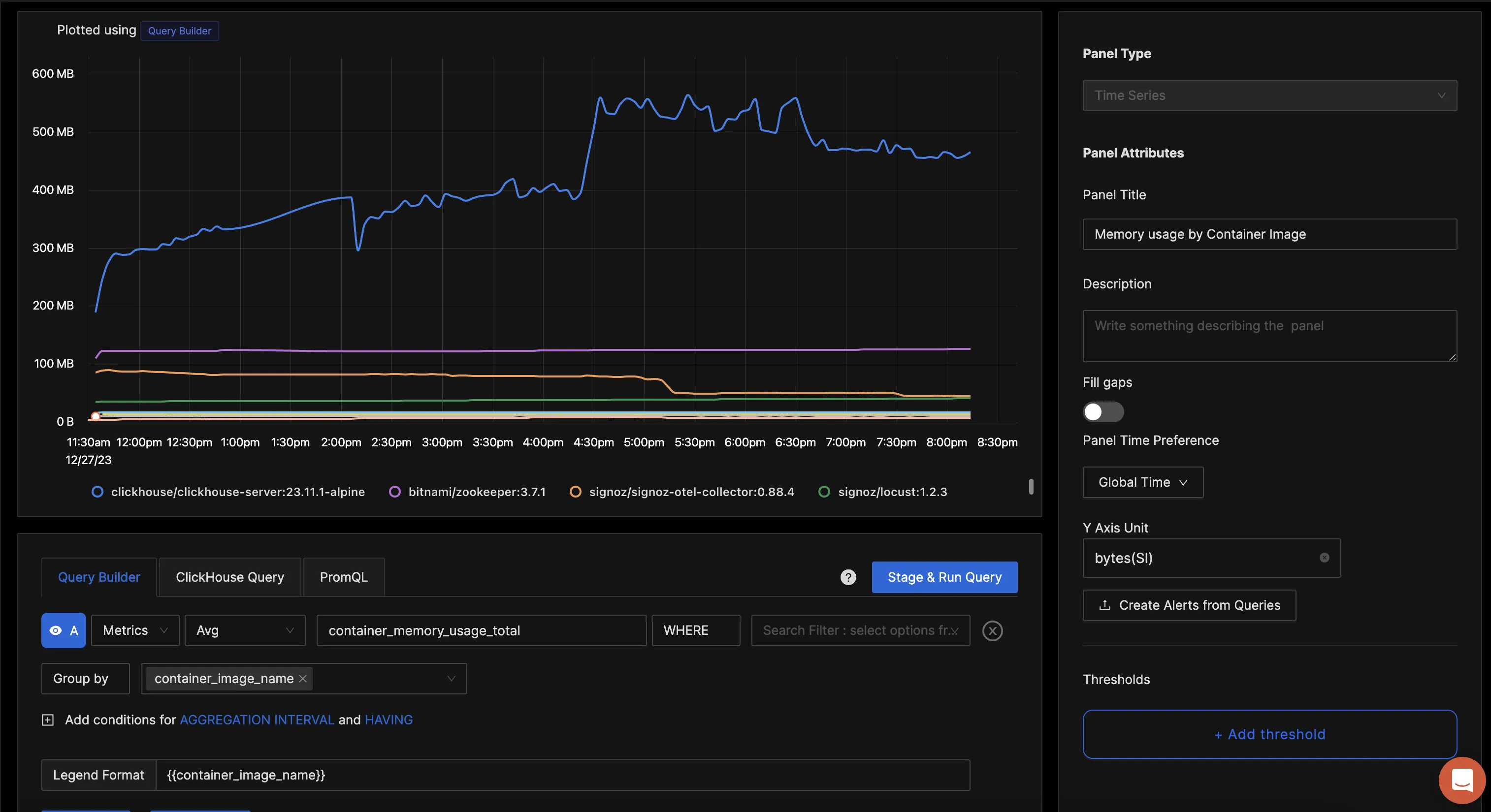
为每个容器的平均内存使用情况创建仪表板面板
您可以围绕各种指标构建完整的仪表板。这是使用收集的指标构建的示例仪表板的外观。您可以使用此 JSON 快速开始使用此仪表板。
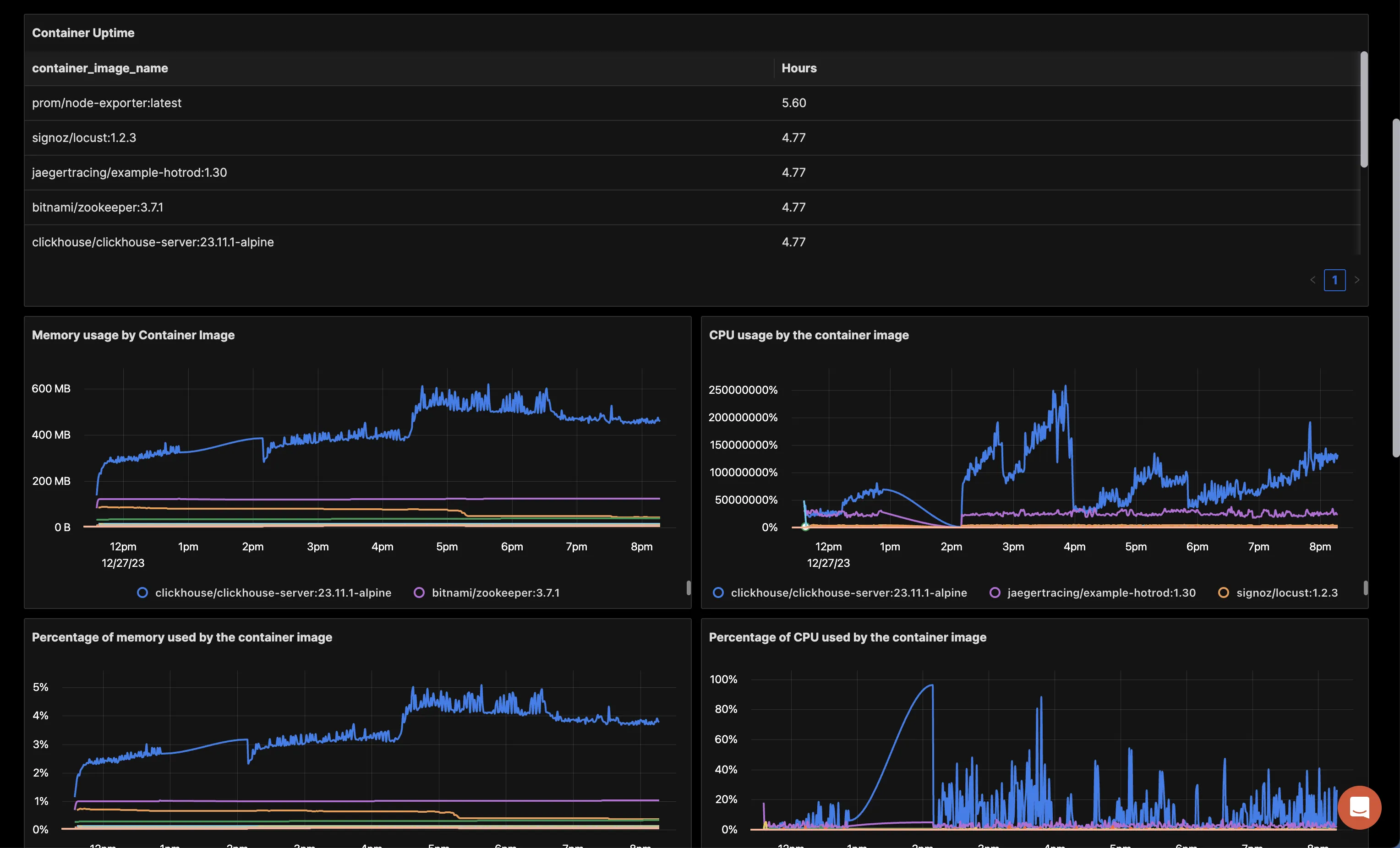
在 SigNoz 中监控 Docker 容器指标的仪表板
您也可以对任何指标创建警报。学习如何创建警报。
对任何指标创建警报并在您选择的通知渠道中收到通知
| 名称 | 描述 | 可用性(cgroup v1/v2) | 类型 |
|---|---|---|---|
| container.blockio.io_service_bytes_recursive | 传输到/从磁盘的组及其后代组的字节数 | 两者 | 总和 |
| container.cpu.usage.kernelmode | cgroup 中任务在内核模式下花费的时间(Linux)。所有容器进程在内核模式下花费的时间(Windows)。 | 两者 | 总和 |
| container.cpu.usage.total | 总消耗的 CPU 时间 | 两者 | 总和 |
| container.cpu.usage.usermode | cgroup 中任务在用户模式下花费的时间(Linux)。所有容器进程在用户模式下花费的时间(Windows)。 | 两者 | 总和 |
| container.cpu.utilization | CPU 使用百分比 | 两者 | 仪表 |
| container.memory.file | 已使用的总内存 | cgroup v2 | 总和 |
| container.memory.percent | 已使用内存百分比 | cgroup v1 | 仪表 |
| container.memory.total_cache | cgroup 进程使用的总缓存内存 | 两者 | 总和 |
| container.memory.usage.limit | 容器的内存限制(如果指定) | 两者 | 总和 |
| container.memory.usage.total | 不包括缓存的容器内存使用情况 | 两者 | 总和 |
| container.network.io.usage.rx_bytes | 容器接收的字节数 | 两者 | 总和 |
| container.network.io.usage.rx_dropped | 容器丢弃的传入数据包 | 两者 | 总和 |
| container.network.io.usage.tx_bytes | 容器传输的字节数 | 两者 | 总和 |
| container.network.io.usage.tx_dropped | 被丢弃的传出数据包 | 两者 | 总和 |
默认情况下不发出以下指标。可以通过应用以下配置启用每个指标:
metrics:
<metric_name>:
enabled: true| 名称 | 描述 | 可用性(cgroup v1/v2) | 类型 |
|---|---|---|---|
| container.blockio.io_merged_recursive | 合并到此 cgroup 及其子 cgroup 请求中的 bios/请求数 | cgroup v1 | 总和 |
| container.blockio.io_queued_recursive | 此 cgroup 及其子 cgroup 的排队请求数 | cgroup v1 | 总和 |
| container.blockio.io_service_time_recursive | 此 cgroup 和子 cgroup 完成的 IO 的请求调度和请求完成之间的纳秒总数 | cgroup v1 | 总和 |
| container.blockio.io_serviced_recursive | 发出到磁盘的 IO(bio)数量,由组及其子组完成 | cgroup v1 | 总和 |
| container.blockio.io_time_recursive | 按设备划分的磁盘时间(以毫秒为单位),分配给 cgroup(及其子 cgroup) | cgroup v1 | 总和 |
| container.blockio.io_wait_time_recursive | 此 cgroup(及其子 cgroup)的 IO 在调度程序队列中等待服务的总时间 | cgroup v1 | 总和 |
| container.blockio.sectors_recursive | 组及其子组传输到/从磁盘的扇区数 | cgroup v1 | 总和 |
| container.cpu.limit | 为容器设置的 CPU 限制。 | 两者 | 总和 |
| container.cpu.shares | 为容器设置的 CPU 份额。 | 两者 | 总和 |
| container.cpu.throttling_data.periods | 启用节流的周期数 | 两者 | 总和 |
| container.cpu.throttling_data.throttled_periods | 容器达到节流限制的周期数。 | 两者 | 总和 |
| container.cpu.throttling_data.throttled_time | 容器被节流的累计时间 | 两者 | 总和 |
| container.cpu.usage.percpu | 容器的每个核心 CPU 使用率 | cgroup v1 | 总和 |
| container.cpu.usage.system | 系统报告的系统 CPU 使用率 | 两者 | 总和 |
| container.memory.active_anon | 内核识别为活动的匿名内存量。 | 两者 | 总和 |
| container.memory.active_file | 内核识别为活动的缓存内存。 | 两者 | 总和 |
| container.memory.anon | 在匿名映射中使用的内存量,例如 brk()、sbrk() 和 mmap(MAP_ANONYMOUS)(仅在 cgroups v2 中可用) | cgroup v2 | 总和 |
| container.memory.cache | container.memory.total_active_anon | cgroup v1 | 总和 |
| container.memory.total_active_anon | 内核识别为活动的匿名内存量。包括子 cgroup | cgroup v1 | 总和 |
| container.memory.total_active_file | 内核识别为活动的缓存内存。包括子 cgroup | cgroup v1 | 总和 |
| container.memory.total_dirty | 等待写入磁盘的字节数,来自此 cgroup 和子组 | cgroup v1 | 总和 |
| container.memory.total_inactive_anon | 内核识别为非活动的匿名内存量。包括子 cgroup | cgroup v1 | 总和 |
| container.memory.total_inactive_file | 内核识别为非活动的缓存内存。包括子 cgroup | cgroup v1 | 总和 |
| container.memory.total_mapped_file | 表示控制组及其子组中的进程映射的内存量 | cgroup v1 | 总和 |
| container.memory.total_pgfault | 指示 cgroup(或子 cgroup)进程触发页面错误的次数 | cgroup v1 | 总和 |
| container.memory.total_pgmajfault | 指示 cgroup(或子 cgroup)进程触发主要故障的次数 | cgroup v1 | 总和 |
| container.memory.total_pgpgin | cgroup 和子组从磁盘读取的页面数 | cgroup v1 | 总和 |
| container.memory.total_pgpgout | cgroup 和子组写入磁盘的页面数 | cgroup v1 | 总和 |
| container.memory.total_rss | 不对应磁盘上任何内容的内存量:堆栈、堆和匿名内存映射。包括子 cgroup | cgroup v1 | 总和 |
| container.memory.total_rss_huge | 此 cgroup 和子 cgroup 中的匿名透明大页字节数 | cgroup v1 | 总和 |
| container.memory.total_unevictable | 不能回收的内存量。包括子 cgroup | cgroup v1 | 总和 |
| container.memory.total_writeback | 此 cgroup 和后代中队列同步到磁盘的文件/anon 缓存的字节数 | cgroup v1 | 总和 |
| container.memory.unevictable | 不能回收的内存量。 | 两者 | 总和 |
| container.memory.usage.max | 最大内存使用量。 | 两者 | 总和 |
| container.memory.writeback | 此 cgroup 中队列同步到磁盘的文件/anon 缓存的字节数 | cgroup v1 | 总和 |
| container.network.io.usage.rx_errors | 已接收网络错误 | 两者 | 总和 |
| container.network.io.usage.rx_packets | 已接收数据包中的错误 | 两者 | 总和 |
为所有指标收集的属性如下:
| 名称 | 描述 | 值 | 启用 |
|---|---|---|---|
| container.command_line | 容器执行的完整命令。 | 任意字符串 | 否 |
| container.hostname | 容器的主机名。 | 任意字符串 | 是 |
| container.id | 容器的 ID。 | 任意字符串 | 是 |
| container.image.id | 容器镜像的 ID。 | 任意字符串 | 否 |
| container.image.name | 容器中使用的 docker 镜像的名称。 | 任意字符串 | 是 |
| container.name | 容器的名称。 | 任意字符串 | 是 |
| container.runtime | 容器的运行时。对于此receiver,将始终为“docker”。 | 任意字符串 | 是 |
在本教程中,您安装了一个 OpenTelemetry Collector 来收集 Docker 容器指标,并将收集的数据发送到 SigNoz 进行监控和可视化。
访问我们的 OpenTelemetry Collector 完整指南以了解更多信息。OpenTelemetry 正在悄悄成为开源可观察性的世界标准,使用它可以获得诸如所有遥测信号的单一标准、无供应商锁定等优势。
SigNoz 是一个开源的 OpenTelemetry 原生 APM,可以用作您所有可观察性需求的单一后端。