在 Kubernetes 中运行 Go 应用的 CPU 和内存优化配置指南。
译自 Kubernetes CPU Limits and Go,作者 William Kennedy 。
我正在开发一个将要部署在 GCP 上的 Kubernetes(K8s)托管环境中的 Go 服务。有一天,我想要查看测试环境中的日志,于是获取了 ArgoCD 平台的访问权限。在尝试找到日志的过程中,我无意中看到了描述我的服务部署配置的 YAML。让我震惊的是,CPU 限制被设置为 250m。我对它意味着我的服务将被限制到 25% 的 CPU 有一个粗略的理解,但我真的不清楚它的真正含义。
我决定联系运维团队,问他们为什么设置这个 250m 的数字,它意味着什么?他们告诉我,这是一个谷歌的默认值,他们没有修改它,而且根据他们的经验,这个设置似乎不会引起问题。然而,他们并不比我更理解这个设置。这对我来说还不够,我想要了解这个设置将如何影响我的 Go 服务在 Kubernetes 中运行。这启动了为期 2 天的深入探索,我发现的东西非常有趣。
我相信有许多 Go 服务在 Kubernetes 中运行着 CPU 限制,无法达到本该有的运行效率。在这篇文章中,我将解释我学到的东西,并展示当 CPU 限制被使用且你的 Go 服务没有被配置来适应该设置范围时会发生什么。
以下是启动了我的服务这个旅程的部署 YAML 中我看到的内容。
清单 1
containers:
- name: my-service
resources:
requests:
cpu: "250m"
limits:
cpu: "250m"你可以看到一个 250m 的 CPU 限制被设置。CPU 限制和请求的值以毫核为单位进行配置。毫核允许你描述 CPU 时间的分数。例如,如果你想配置一个服务使用单个 CPU 100% 的时间,你会使用 1000m 的毫核值。250m 的毫核值意味着该服务被限制到单个 CPU 25% 的时间。
将一定百分比的时间分配给服务在不同架构和操作系统上的具体机制可能有所不同,所以我不会深入探讨这个兔子洞。我将关注语义,因为它将模拟你将体验到的行为。
为了开始简单,想象一个只有 1 个 CPU 的 K8s 集群中的单个节点。
图 1
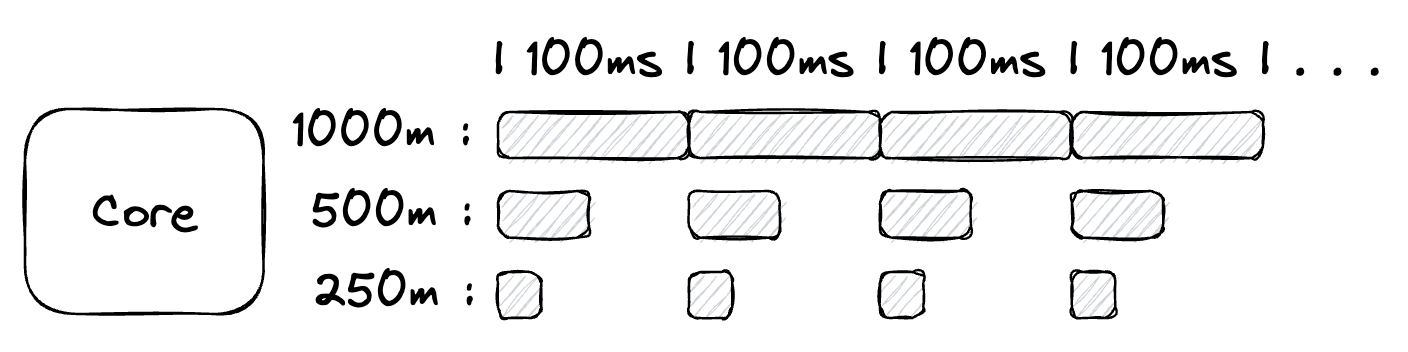
图 1 表示一个只有单个 CPU 的节点。对于这个单个 CPU,Kubernetes 开始一个每 100 毫秒重复的周期。在每个周期中,Kubernetes 根据 CPU 限制设置中的分配按比例在所有运行在节点上的服务之间共享 100 毫秒的时间。
如果节点上只运行一个服务,那么你可以为每个周期分配所有 100ms 的时间给那个服务。为了配置这一点,你需要将限制设置为 1000m。如果有两个服务运行在节点上,你可能希望这两个服务平分 CPU 时间。在这种情况下,你会为每个服务分配 500m,这为每个服务在每个 100ms 周期中提供 50ms 的时间。如果有四个服务运行在节点上,你可以为每个服务分配 250m,这为每个服务在每个 100ms 周期中提供 25ms 的时间。
你不必平分 CPU 时间。一个服务可以被分配 500m(50ms),第二个服务可以被分配 100m(10ms),最后两个服务可以被分配 200m(20ms),总共为 1000m(100ms)。
考虑只有一个 CPU 的节点是合理的,但它不现实。如果节点有两个 CPU 会发生什么变化?
图2
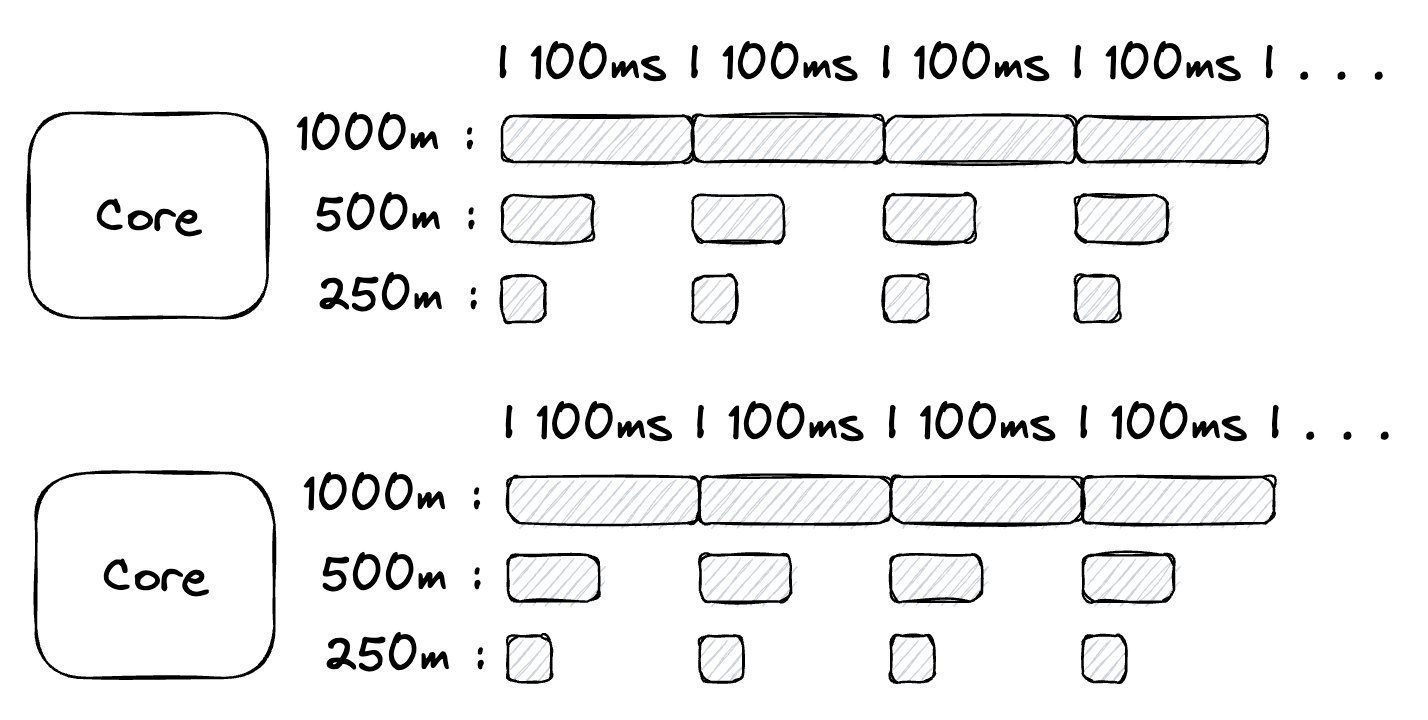
现在节点上的每个周期中有 2000m(200ms)的时间可以分配给不同运行在节点上的服务。如果有 4 个服务运行在节点上,CPU 时间可以这样分配:
清单 2
Service1 : Limit 1250m : Time 125ms : Total 1250m (125ms)
Service2 : Limit 250m : Time 25ms : Total 1500m (150ms)
Service3 : Limit 250m : Time 25ms : Total 1750m (175ms)
Service4 : Limit 250m : Time 25ms : Total 2000m (200ms)在清单 2 中,我为 Service1 分配了节点上的 1250m(125ms)时间。这意味着 Service1 将完全获得一个 100ms 周期的时间,并会从第二个可用的 100ms 周期中分享 25ms 的时间。其它三个服务被分配 250m(25ms),所以它们将在第二个 100ms 周期中共享时间。当你加起所有的时间,节点上可用的全部 2000m(200ms)时间就被分配出去了。
图3
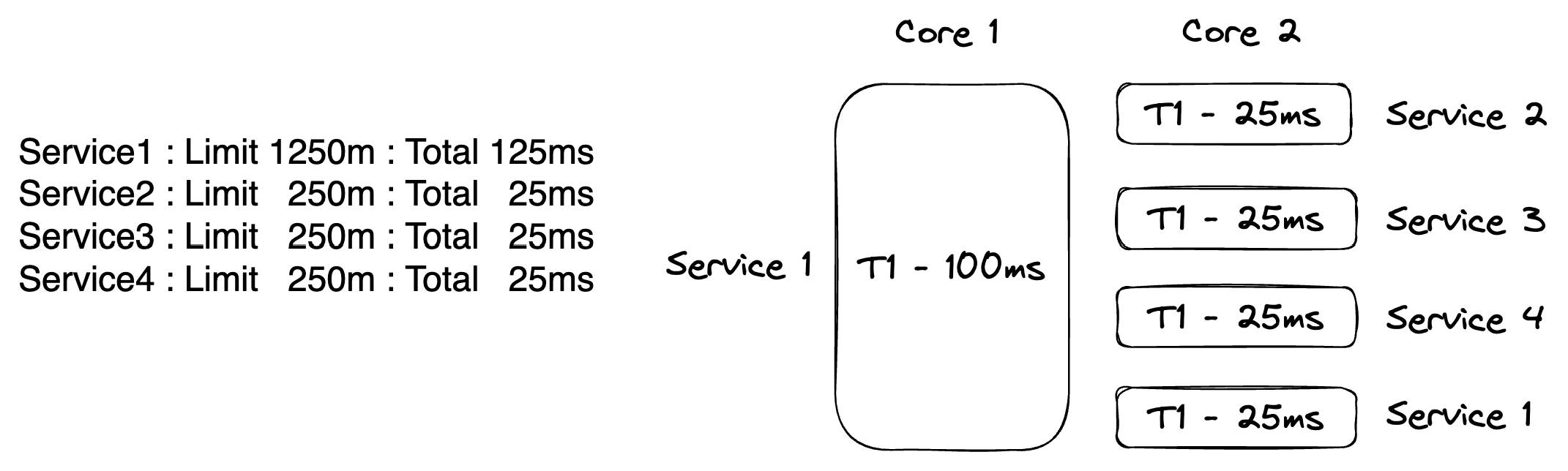
图 3 试图可视化之前在一个双 CPU 节点上描述的时间分配。这个图片假设每个服务以单个 OS 线程程序运行,其中每个 OS 线程被分配到一个 CPU,并为每个服务运行完全配置的时间。在这种配置中,使用最少数量的 OS 线程来运行四个服务,最大限度地减少上下文切换开销。
然而,实际上没有 CPU 亲和性,OS 线程受制于操作系统典型的 10ms 时间片。这意味着任何给定时间哪个 OS 线程在哪个 CPU 上执行是未定义的。这里的关键是 Kubernetes 将与操作系统合作,允许 Service1 在每 200ms 周期中在需要时总是拥有 125ms 的节点时间。
事实上,当服务以多 OS 线程运行时,情况会更复杂,因为所有 OS 线程都将被调度到可用的 CPU 上运行,每个服务的运行 OS 线程总和将被调节到分配的限制值。
图4
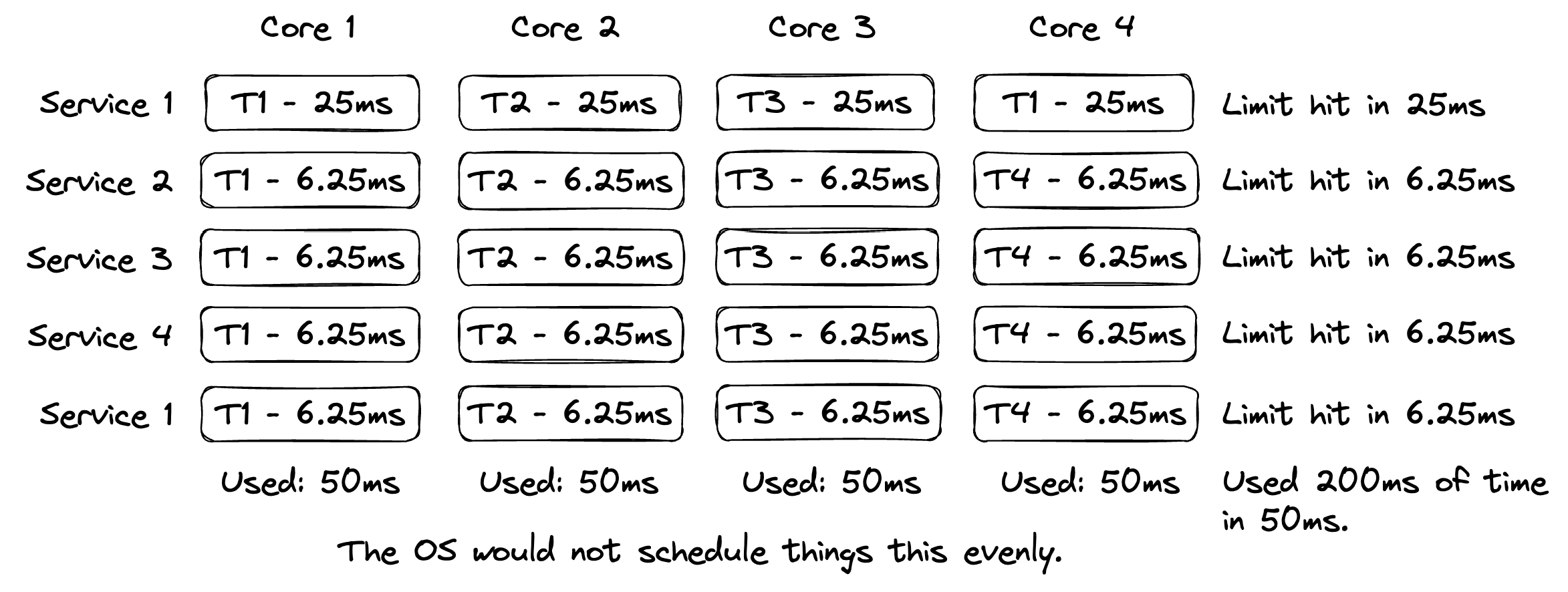
图4试图捕获一个周期中每个服务运行4个OS线程的情况,在一个4CPU节点上,与最后一个例子相同的限制。你可以看到限制是4倍更快达到的,带有额外的上下文切换(超过10ms OS线程时间片),导致随时间完成的工作更少。
归根结底,这是一切的关键。
一个在1000m(100ms)或更低的限制意味着该服务在每个周期中只会使用一个CPU的时间。
对于用Go编写的服务来说,理解这一点非常重要,因为Go程序作为CPU绑定程序运行。当你有一个CPU绑定程序时,你永远不想要比内核数更多的OS线程。
要理解Go程序如何作为CPU绑定程序运行,你需要理解Go调度程序的语义。
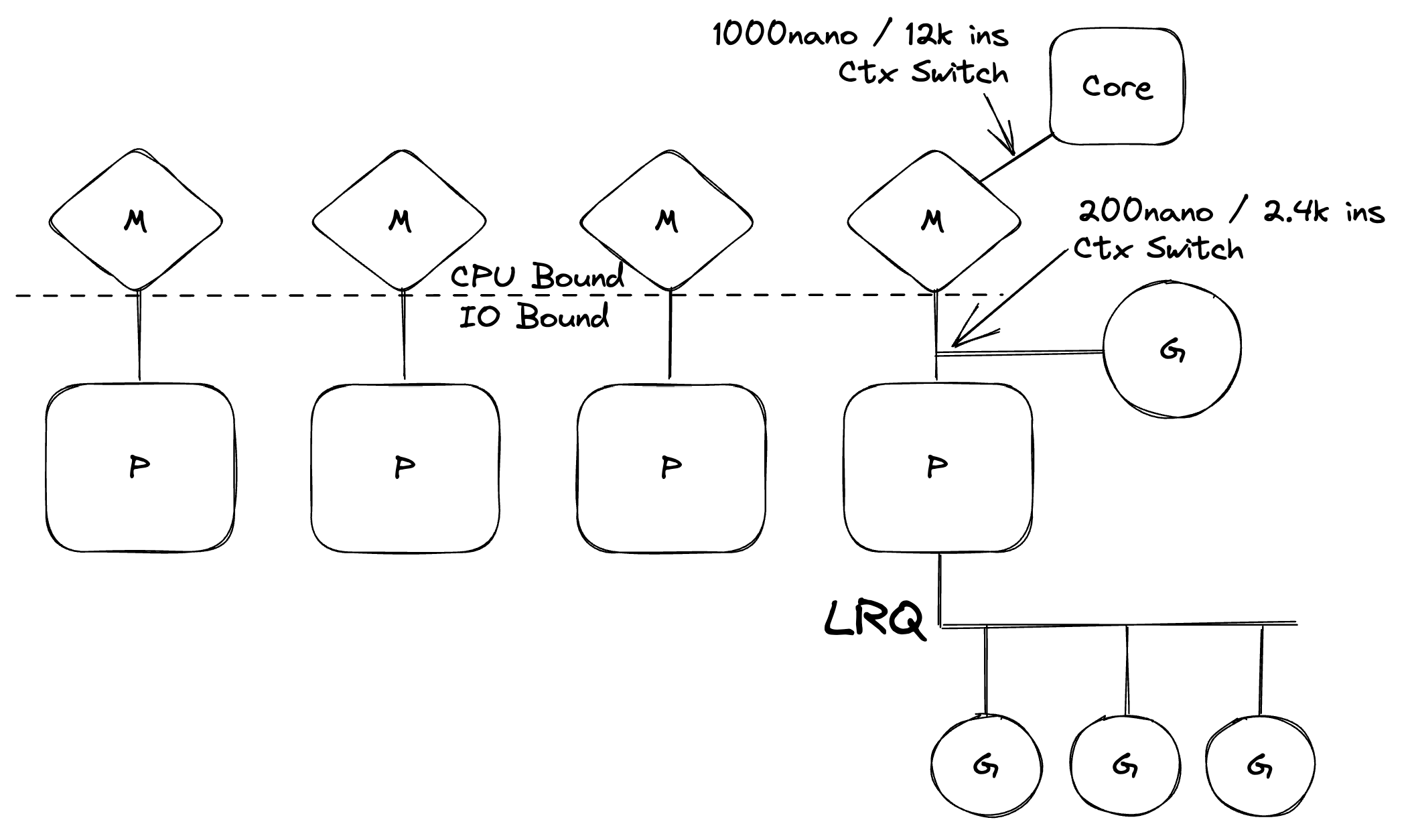
图5
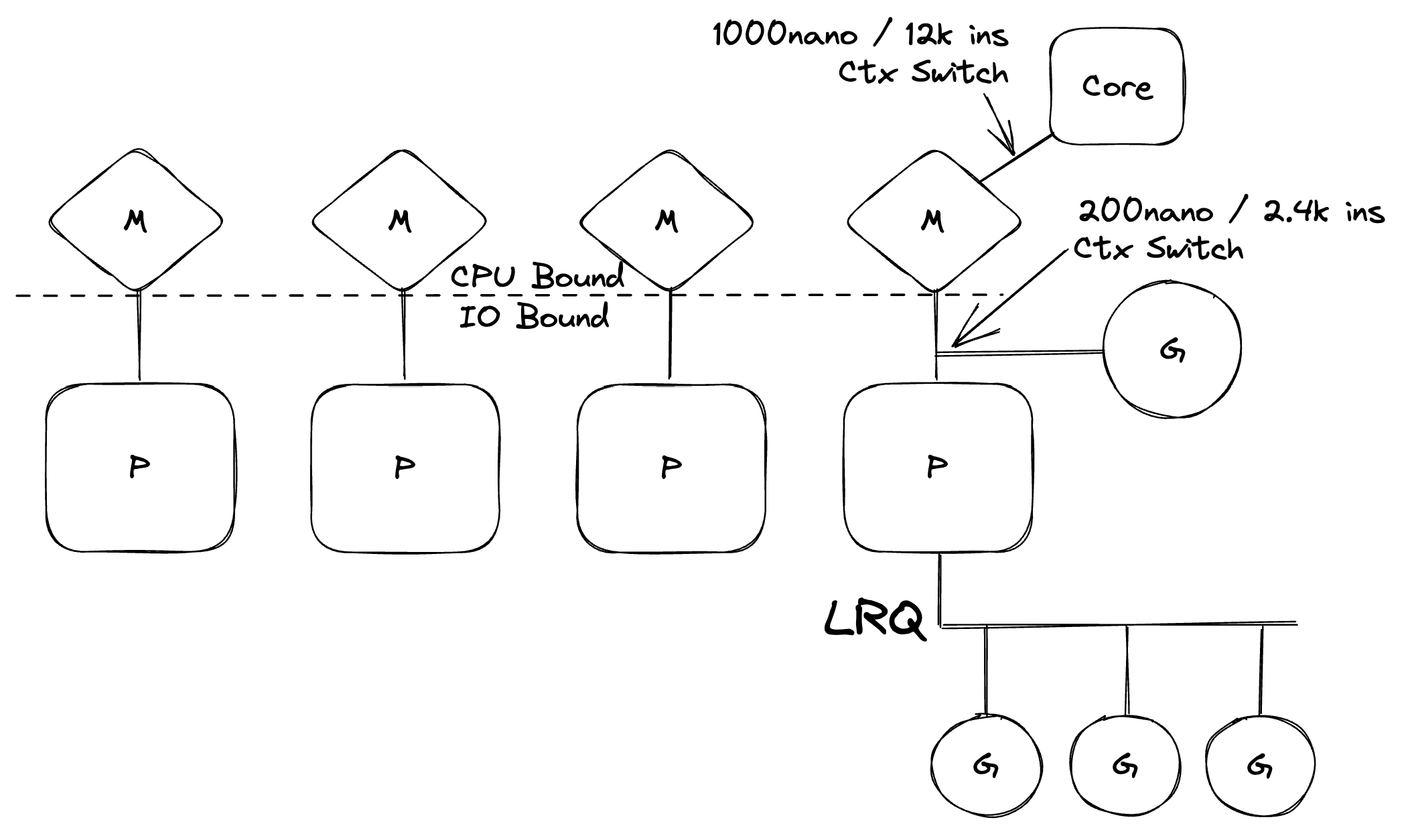
图5中有很多事情在发生,但它为你提供了调度程序的高级语义视图。在图中,P是一个逻辑处理器,M代表机器并表示一个OS线程,G是一个Goroutine。我会要求你阅读我在2018年写的这个系列来深入研究这个主题。
https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part1.html
我希望你能花时间阅读那个系列,但如果你现在没有时间也没关系。我将跳到结论,你需要相信我。
重要的是,Go调度程序将IO绑定的工作负载(由M上的G执行)转换为CPU绑定的工作负载(由内核上的M执行)。这意味着你的Go程序是CPU绑定的,这就是为什么Go运行时会在其运行的机器上创建与内核数相同的OS线程。
如果你阅读了该系列,你就会明白当运行CPU绑定的工作负载时,永远不要有比内核更多的OS线程。拥有比内核更多的OS线程将导致额外的上下文切换,这会减慢程序完成应用程序工作的速度。
我如何证明所有这些呢?
幸运的是,我可以使用服务仓库,并通过在Kubernetes集群中运行的Go服务加载。我将使用KIND(Docker中的K8S)运行集群,并配置我的Docker环境有4个CPU。这将允许我以4个OS线程的Go程序和单个OS线程的Go程序运行Go服务,同时被分配250m(25ms)的限制。
如果你想要跟随,请克隆服务仓库并按照makefile中的说明安装所有需要的东西。
首先,我将启动集群。在克隆仓库的根目录内,我将运行make dev-up命令。
清单3
$ make dev-up
Creating cluster "ardan-starter-cluster" ... ✓
Ensuring node image (kindest/node:v1.29.1) 🖼 ✓
Preparing nodes 📦 ✓
Writing configuration 📜 ✓
Starting control-plane 🕹️ ✓
Installing CNI 🔌 ✓
Installing StorageClass 💾
Set kubectl context to "kind-ardan-starter-cluster"make dev-up命令使用KIND启动Kubernetes集群,然后将所有需要的容器加载到本地KIND镜像仓库中。
清单4
$ make dev-update-apply接下来我将运行make dev-update-apply命令来构建Go服务镜像,将它们加载到本地仓库中,然后将所有YAML应用到集群中以运行所有POD。
当系统运行后,make dev-status命令将向我显示这个。
图6
此时,配置使得sales服务以单个OS线程Go程序运行,限制为250m(25ms)。
清单5
Limits:
cpu: 250m
Requests:
cpu: 250m
Environment:
GOMAXPROCS: 1 (limits.cpu)当我运行make dev-describe-sales命令时,我可以看到设置了250m(25ms)的限制,并且GOMAXPROCS环境变量被设置为1。这将强制sales服务以单个OS线程Go程序运行。当Go服务的限制设置为1000m或更少时,这就是我想要的运行方式。
现在我可以对系统进行一些负载测试。首先我需要一个token。
清单6
$ make token
{"token":"eyJhbGciOiJSUzI1NiIsImtpZCI6IjU0YmIyMTY1LTcxZTEtNDFhNi1hZjNlLTdkYTRhM..."}一旦我有了一个token,我需要将它放到一个环境变量中。
清单7
$ export TOKEN=<Copy Token From Above>有了TOKEN变量,我现在可以运行一个小的负载测试。我将对系统运行1000个请求,使用100个并发连接。
清单8
$ make load
Summary:
Total: 10.5782 secs
Slowest: 2.7859 secs
Fastest: 0.0070 secs
Average: 0.9515 secs
Requests/sec: 94.5341一旦负载完成,我看到在这个集群上的最佳配置下,Go服务处理了大约94.5个请求每秒。
现在我将从部署YAML中注释掉GOMAXPROCS环境设置。
清单9
env:
# - name: GOMAXPROCS
# valueFrom:
# resourceFieldRef:
# resource: limits.cpu这是我找到的将GOMAXPROCS变量设置为匹配服务的CPU限制的最佳方法。Uber也有一个模块可以做到这一点,但我发现它有时会失败。
此更改将导致Go服务使用尽可能多的OS线程(M),与内核数量一样,这是默认行为。在我的例子中,由于我将Docker环境配置为使用4个CPU,将是4个线程。在对YAML的这部分添加注释之后,我需要重新应用部署。
清单10
$ make dev-apply一旦更改被应用,我可以检查Go服务是否在使用新的设置运行。
清单11
Limits:
cpu: 250m
Requests:
cpu: 250m
Environment:当我再次运行 make dev-describe-sales 命令时,我注意到GOMAXPROCS设置不再显示。这意味着Go服务正在使用默认数量的OS线程运行。
现在我可以再次运行负载测试。
清单12
$ make load
Summary:
Total: 38.0378 secs
Slowest: 19.8904 secs
Fastest: 0.0011 secs
Average: 3.4813 secs
Requests/sec: 26.2896这次我看到吞吐量处理请求大大下降。我从每秒约94.5个请求下降到每秒约26.3个请求。考虑到我使用的负载规模很小,这下降是巨大的。
Go运行时不知道它在Kubernetes中运行,默认情况下将为节点上的每个CPU创建一个OS线程。如果你为服务设置了CPU限制,则需要你设置GOMAXPROCS的值来匹配限制。清单10展示了如何在部署YAML中直接设置GOMAXPROCS。
我想知道在Kubernetes中运行的许多Go服务在限制下是否没有设置GOMAXPROCS环境变量来匹配限制。我想知道由于节点没有以最高效方式运行,这些系统正在经历多少过度供给。这些东西很复杂,任何管理Kubernetes集群的人都需要考虑这些问题。
我不知道其它编程语言中的服务是否会遇到同样的低效问题。Go程序在操作系统/硬件级别上运行为CPU绑定是这种低效的根本原因。所以对其他语言来说可能不是问题。
我没有花时间查看内存限制,但我确定类似的问题存在。如果配置了任何内存限制,你可能需要查看使用GOMEMLIMIT来匹配Kubernetes内存限制。这可能是我下一个帖子要关注的内容。