译自 MapReduce from Scratch,作者 Michal Pitr。
在过去的几周里,我一直在从头开始构建 MapReduce。
这将是一篇很长的文章:我们将了解分布式计算的必要性,重新发现为什么 MapReduce 是对许多问题进行建模的自然方式,构建我们自己的版本,了解各个部分如何组合在一起,并用它解决一个实际问题!
假设我们想计算海量数据集中的词频。我们尝试在单台机器上处理它,但发现需要一个月以上的时间。我们能做什么?
第一个想法应该是获得一台更快的机器,但它可能不存在或太昂贵。相反,让我们看看如何将问题分布到 N 台商品机器上。我们希望有一种简单的方法来使用简单的查询查找任何单词的频率,即 grep over a file。
让我们首先将数据集拆分为 N 个分区,并使用不同的机器计算每个子集的词频。这已经给了我们 Nx 的加速,减去了一些固定的开销。为了合并结果,我们可以添加一台最终机器,它获取这 N 个部分结果文件并对相应单词的频率求和。
这与 MapReduce 背后的核心思想相差不远。上述过程有两个主要步骤:首先,我们将单词映射到输入数据子集中的频率,然后减少中间结果以获得最终答案。
请注意,这是非常通用的,想象一下我们有一个大型照片数据集,我们希望对其进行分类:我们可以将图像分类任务作为映射操作,然后在归约阶段将具有相同类别的图像分组。
另一个观察结果是,映射部分通常是两个部分中更昂贵的阶段,因此,通常映射器比归约器多。
希望已经让你相信 MapReduce 是一个合理的想法,让我们看看 MapReduce 论文如何解决词频问题。
下面,我从 论文中复制粘贴了 WordCounter MapReduce 程序。让我们看看它是如何工作的。稍后,当我们实现我们的版本时,我们的目标是保持使用语义相同。
#include "mapreduce/mapreduce.h"
// User’s map function
class WordCounter : public Mapper
{
public:
virtual void Map(const MapInput &input)
{
const string &text = input.value();
const int n = text.size();
for (int i = 0; i < n;)
{
// Skip past leading whitespace
while ((i < n) && isspace(text[i]))
i++;
// Find word end
int start = i;
while ((i < n) && !isspace(text[i]))
i++;
if (start < i)
Emit(text.substr(start, i - start), "1");
}
}
};
REGISTER_MAPPER(WordCounter);
// User’s reduce function
class Adder : public Reducer
{
virtual void Reduce(ReduceInput *input)
{
// Iterate over all entries with the
// same key and add the values
int64 value = 0;
while (!input->done())
{
value += StringToInt(input->value());
input->NextValue();
}
// Emit sum for input->key()
Emit(IntToString(value));
}
};
REGISTER_REDUCER(Adder);
int main(int argc, char **argv)
{
ParseCommandLineFlags(argc, argv);
MapReduceSpecification spec;
// Store list of input files into "spec"
for (int i = 1; i < argc; i++)
{
MapReduceInput *input = spec.add_input();
input->set_format("text");
input->set_filepattern(argv[i]);
input->set_mapper_class("WordCounter");
}
MapReduceOutput *out = spec.output();
out->set_filebase("/gfs/test/freq");
out->set_num_tasks(100);
out->set_format("text");
out->set_reducer_class("Adder");
// Tuning parameters: use at most 2000
// machines and 100 MB of memory per task
spec.set_machines(2000);
spec.set_map_megabytes(100);
spec.set_reduce_megabytes(100);
// Now run it
MapReduceResult result;
if (!MapReduce(spec, &result))
abort();
// Done: ’result’ structure contains info
// about counters, time taken, number of
// machines used, etc.
return 0;
}用户程序有 3 部分:map 函数、reduce 函数和配置。大部分繁重的工作由导入的 mapreduce 库处理。
map 函数将输入文本拆分为单词并发出键值对。例如,“the quick brown fox jumps over the lazy dog” 映射到以下键值对:[“the”:1, “quick”:1, “brown”:1, “fox”:1, “jumps”: 1, “over”:1, “the”:1, “lazy”:1, “dog”:1]。请注意,对 (“the”: 1) 发射了两次。
reduce 函数按键操作。例如,给定输入 [“the”:1, “the”:1”, “the”:1],它将发出 (“the”:3)。
配置处理输入输出、格式以及可用于 MapReduce 作业的资源数量。
在不到 100 行代码中,我们可以通过利用 1000 台机器来解决单词计数问题!这非常简洁,展示了 MapReduce 作为一种抽象的强大功能。
本文将成为我们的灵感,让我们开始勾画实施要求:
- 用户导入我们的 MAPREDUCE 库,执行 MAP 和 REDUCE 函数,并提供配置。
- 当用户执行二进制文件时,它将被复制到多台机器上,在这些机器上以 Mapper 或 Reducer 的模式执行。
- 这些机器必须有权访问输入数据。
- Mapper 的输出必须对 Reducer 可用。
- 用户可以访问最终结果。
当我开始研究这项工作时,这些需求提出了两个主要未知:如何将二进制文件分发给其他计算机以及如何向它们提供输入数据。
经过一番研究,我决定在我的输入数据上托管一个网络存储服务器——我选择 NFS。我们可以将网络目录挂载到每台计算机,并允许计算机对该目录进行读写。它可能不像 Google 文件系统或 HDFS 那样具有高性能或高可扩展性,但它可以满足我们的目的。
为了将二进制文件分发到多台计算机,执行并监控其状态,我们可能会通过 SCP 复制二进制文件、通过 SSH 登录到计算机、执行二进制文件,然后等待其完成。我们甚至可以实施运行状况 ping 和进度报告。
不过,在我闲置一段时间后,我意识到这听起来非常像集群编排,并决定利用 Kubernetes 让我的生活更轻松。我们可以将二进制文件构建为 docker 镜像,并将其作为 Kubernetes 任务执行。通过持久卷和持久卷声明,可以轻松地将 NFS 与 Kubernetes 集成。不用担心,您不必理解这些概念,但我提到它们是为了完整起见。
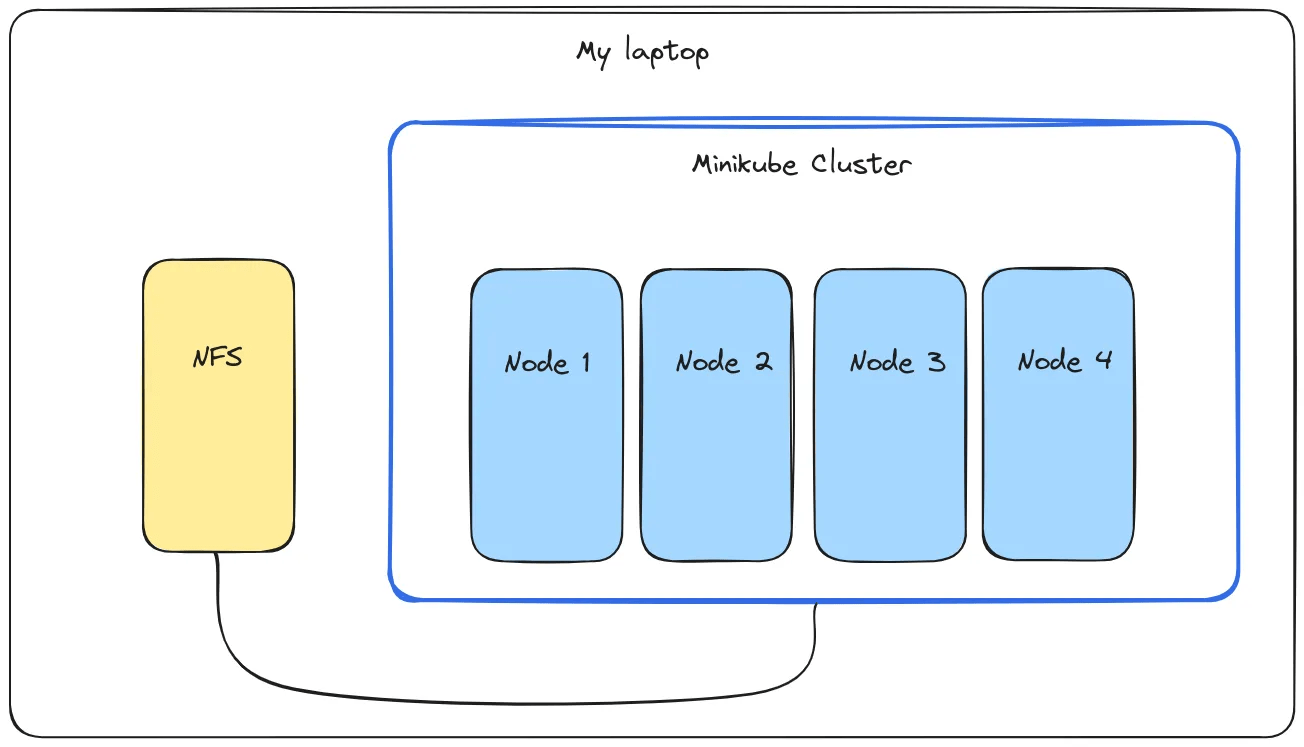
由于我是出于教育目的开发这个概念,所以我使用 minikube 在我的笔记本电脑上启动一个本地虚拟集群。我在集群外将我的 NFS 服务器作为一个 docker 容器运行,并通过 docker 网络将其连接到该集群。此设置的优点是它可以轻松迁移到多个物理或虚拟机。

在基础架构到位的情况下,让我们开始编写我们的MapReduce框架!
首先,我们将探讨如何使用我的 MapReduce 实现解决字数统计问题。然后,我们将深入研究该实现,以了解各个组件的功能。
正如我承诺的,我试图保持与原始论文相似的用法语义。使用我的 Go 实现比较此 MapReduce 程序和我们之前看到的 C++ 示例!
// main.go
import (
…
"github.com/MichalPitr/map_reduce/pkg/config"
"github.com/MichalPitr/map_reduce/pkg/interfaces"
"github.com/MichalPitr/map_reduce/pkg/mapreduce"
)
type WordCounter struct {
wordRegex *regexp.Regexp
}
func (wc *WordCounter) Map(input interfaces.MapInput, emit func(key, value string)) {
text := input.Value()
text = strings.ToLower(text)
words := wc.wordRegex.FindAllString(text, -1)
for _, word := range words {
emit(word, "1")
}
}
type Adder struct{}
func (a *Adder) Reduce(input interfaces.ReducerInput, emit func(value string)) {
val := 0
for !input.Done() {
num, err := strconv.Atoi(input.Value())
if err != nil {
log.Printf("Failed converting input to integer, skipping: %q", input.Value())
input.NextValue()
continue
}
val += num
input.NextValue()
}
emit(strconv.Itoa(val))
}
func main() {
cfg := config.SetupJobConfig()
log.Printf("cfg: %+v", cfg)
cfg.NumReducers = 2
cfg.NumMappers = 4
cfg.Mapper = &WordCounter{wordRegex: regexp.MustCompile(`\b\w+\b`)}
cfg.Reducer = &Adder{}
mapreduce.Execute(cfg)
}让我们花点时间理解一下我的解决方案是如何在幕后工作的。我们可以参考该论文中一张方便的图表来说明这一点。
用户的程序在三个模式下执行,分别是 Master、Mapper 和 Reducer,在不同的机器上执行。在高层次上,master 处理整个作业编排,mappers 对输入文件执行昂贵的 map 操作,reducers 联合来自 mappers 的中间结果。在我的解决方案中,模式由 CLI 标志决定,例如 --mode=master 代表 master 模式。

主模式将输入文件分割成子集、准备 NFS 目录、启动带有已分配文件的映射器作业,并等待它们完成。然后,针对还原器重复此过程。主函数非常简单,我可以将其列出如下:
// /pkg/master/master.go
func Run(cfg *config.Config) {
clientset := createKubernetesClient()
numNodes := getNumberOfNodes(clientset)
mustValidateConfig(cfg, numNodes)
jobId := fmt.Sprintf("job-%s", time.Now().Format("2006-01-02-15-04-05"))
log.Printf("Running master: %s", jobId)
mustCreateJobDir(cfg.NfsPath, jobId)
fileRanges := partitionInputFiles(cfg.InputDir, cfg.NumMappers)
t0 := time.Now()
launchMappers(cfg, clientset, jobId, fileRanges)
waitForJobsToComplete(clientset, jobId, "mapper")
log.Printf("Mappers took %v to finish", time.Since(t0))
t1 := time.Now()
launchReducers(cfg, clientset, jobId)
waitForJobsToComplete(clientset, jobId, "reducer")
log.Printf("Reducers took %v to finish", time.Since(t1))
log.Printf("Total runtime: %v", time.Since(t0))
}让我们来理解 launchMappers 函数。它为每个映射器创建 Kubernetes 作业。作业规范指定:
- 包含我们的二进制文件的 Docker 映像。
- mapper 必需的 CLI 参数:mapper 模式、输入/输出目录和要处理的文件。
- 如何装载 NFS 存储。
等等……Docker镜像?我们从未创建过!当我们最终运行我们的解决方案时我会更详细地展示这一点,但 Kubernetes 围绕容器,所以我们对我们的二进制文件进行 docker 化,以便 Kubernetes pod 可以下载该二进制文件。
在 launchMappers 创建 Mappers 作业后,Kubernetes会将作业分配给群集内的节点,启动容器,并监视其状态。现在我们可以运行 Mappers 了,是时候了解它们的工作原理了!
在 map 模式中,二进制文件逐行扫描输入文件,并将该行传递给用户的 map 函数。Map 处理文本,并使用注入的 emit 函数发出键值对。
在我的实现中,emit 函数非常简单 - 它将键值对存储在一个动态列表的 map 中。更完整的实现将进行一些缓冲,然后将缓冲区刷新到磁盘。
当 mapper 完成所有输入的处理后,它将已排序的键值对保存到 NFS 存储中的中间文件中,reducer 将从该中间文件中读取这些键值对进行最终处理。让我们在这里缩小视野,看看从中间文件到 reducer 的这种映射如何工作。

我们希望按照键为中间文件分区,这样所有相同的键都由一个 reduce 任务处理。例如,”brown“和“the”出现在 Mapper 1 和 Mapper 2 中间文件。我们希望确保每个最终由同一个 reduce 任务处理。我们来看看一个例子。

为了实现这一点,当保存 mappers 中的中间结果时,我们根据 reducers R 的数量使用公式对键进行分区

例如,使用 FNV 哈希和 R = 2,我们得到

(数学笔记:这可以解释为“1 与 FNV(brown) mod 2 同余”)。
基于该内容,我们将“brown”分配到第二个中间文件,该文件将由 reducer 2 处理。请注意在上面的示例中,所有“the”都落入蓝色文件中,而所有“brown”都落入红色文件中!
这总结了关于 mappers 的讨论——接下来,让我们看看 reducer 如何工作。
如下先前所突出显示,还原程序的工作是从分配的中介文件中读取键值对,然后使用用户定义的还原函数来处理它们。
有两件事我们可以确信:中介文件中的键按键排序,如果某中介文件中存在键 A,则我们可以保证键 A 不会出现在分配给其他 reducers 程序的任何文件中。
我尝试以更聪明的方式实现我的 reducers 程序,并避免将所有中介文件加载到内存中。这会带来一个有趣的算法问题:
假设我们要处理 3 个中介文件,一次处理一个键值对,而无需将所有内容加载到内存中。

我们可以借助最小堆即时合并键值对!我们将来自每个文件的第一个键值对加载到堆中。每当我们从堆中弹出数据时,我们从对应文件中读取下一行并将其推入堆中。这为我们提供了一种高效内存读取键值对流的方式!你可以在此处找到实现。
处理完所有中间文件后,Reducer 将结果保存在 NFS 存储中。
例如,上述示例将产生: [“abby”: 1, “alice”: 3, “bob”: 2, “car”:2, “dog”:1, …]。
MapReduce 论文提出了我已经在我的实现中跳过的几个额外的优化。聪明的读者可能已经能够提出一些优化 - 例如,我们可以在 mapper 中选择性地进行一些缩减,不是吗?
恭喜你,你现在对 MapReduce 有一个非常透彻的了解!最困难的部分已经结束了!让我们将它们组合在一起,并使用我们的 MapReduce 来统计 Project Gutenberg 上最流行的 100 本图书中的单词频率!
我下载了 Project Gutenberg 上最流行的 100 本书到 /mnt/nfs/input/,使用的是这个脚本。书本的文件被标记为 book-0 到 book-99。我还创建了一个可以访问我的 NFS 存储的 4 节点 minikube 集群。
michal@michal-ThinkPad-T490s:/mnt/nfs$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
multinode Ready control-plane 27d v1.28.3
multinode-m02 Ready <none> 7d2h v1.28.3
multinode-m04 Ready <none> 7d1h v1.28.3
multinode-m05 Ready <none> 7d1h v1.28.3
我将重用前面展示的 Word-Frequencies Go 主文件。我们必须使用此 Dockerfile 准备 Docker 镜像,并将其推送到我的注册表。mapper 和 reducer 节点将提取此镜像来运行我们的工作负载。
docker build -t michalpitr/mapreduce:latest .
docker push michalpitr/mapreduce:latest
现在我们只需要在本地运行 master!
go build .
./map_reduce --mode=master --image=michalpitr/mapreduce:latest --input-dir /mnt/input/ --nfs-path /mnt/nfs/
让我们检查执行日志。
michal@michal-ThinkPad-T490s:~/code/map_reduce$ ./map_reduce --mode=ma
ster --image=michalpitr/mapreduce:latest --input-dir /mnt/nfs/input/ -
-nfs-path /mnt/nfs/
2024/04/28 17:13:53 Running master job-2024-04-28-17-13-53
2024/04/28 17:13:53 Creating mapper-0 for book-0-30
2024/04/28 17:13:53 Creating mapper-1 for book-31-53
2024/04/28 17:13:53 Creating mapper-2 for book-54-76
2024/04/28 17:13:53 Creating mapper-3 for book-77-99
2024/04/28 17:13:53 Waiting for jobs to finish.
2024/04/28 17:14:03 Waiting for jobs to finish.
2024/04/28 17:14:13 Waiting for jobs to finish.
2024/04/28 17:14:23 All jobs completed.
2024/04/28 17:14:23 Mappers took 30.1843218s to finish
2024/04/28 17:14:23 Creating reducer-0
2024/04/28 17:14:23 Creating reducer-1
2024/04/28 17:14:23 Waiting for jobs to finish.
2024/04/28 17:14:33 All jobs completed.
2024/04/28 17:14:33 Reducers took 10.106014703s to finish
2024/04/28 17:14:33 Total runtime: 40.290376921s
整个作业花费了 40 秒。我们在此处并未期望出现任何疯狂的情况,毕竟,我是在一台动力不足的笔记本电脑上运行此作业,而不是一个真正的集群。
让我们简单了解一下。master 创建了 4 个 mappers,每个 mappers 都分配了一个书籍范围。
使用kubectl,我们可以看到集群正在创建 4 个容器。这是集群拉取我们之前推送的镜像的时候!
michal@michal-ThinkPad-T490s:/mnt/nfs$ kubectl get pods
NAME READY STATUS RESTARTS AGE
mapper-0-zgz24 0/1 ContainerCreating 0 11s
mapper-1-m824k 0/1 ContainerCreating 0 11s
mapper-2-ctqqt 0/1 ContainerCreating 0 11s
mapper-3-l2ddh 0/1 ContainerCreating 0 11s
这些容器启动并完成运行所需的时间并不长。
michal@michal-ThinkPad-T490s:/mnt/nfs$ kubectl get pods
NAME READY STATUS RESTARTS AGE
mapper-0-zgz24 1/1 Running 0 18s
mapper-1-m824k 0/1 Completed 0 18s
mapper-2-ctqqt 0/1 Completed 0 18s
mapper-3-l2ddh 0/1 Completed 0 18s
master 定期轮询 Kubernetes API 服务器以获取这些作业的状态。一旦所有作业都完成,它就会启动归约器。
在进入归约器之前,让我们看看其中一个映射器生成的中间文件:
michal@michal-ThinkPad-T490s:/mnt/nfs/job-2024-04-28-17-13-53/mapper-3$ ls
partition-0 partition-1
检查分区-1 的末尾,显示了陀思妥耶夫斯基的《地下室手记》中一个角色的键值对。到目前为止,一切都好!
michal@michal-ThinkPad-T490s:/mnt/nfs/job-2024-04-28-17-13-53/mapper-3$ tail partition-1
zverkov,1
zverkov,1
zverkov,1
zverkov,1
zverkov,1
…
接下来,master 启动归约器,
michal@michal-ThinkPad-T490s:/mnt/nfs$ kubectl get pods
NAME READY STATUS RESTARTS AGE
…
reducer-0-4xt58 0/1 ContainerCreating 0 2s
reducer-1-xvhfk 0/1 ContainerCreating 0 2s
它们很快完成。
michal@michal-ThinkPad-T490s:/mnt/nfs$ kubectl get pods
NAME READY STATUS RESTARTS AGE
…
reducer-0-4xt58 0/1 Completed 0 7s
reducer-1-xvhfk 0/1 Completed 0 7s
就是这样 - 我们刚刚使用我们自己的 MapReduce 框架计算了单词频率!让我们看看我们可以从结果中学到什么!
我可以在作业文件夹的根目录中看到输出文件:
michal@michal-ThinkPad-T490s:/mnt/nfs/job-2024-04-28-17-13-53$ ls
… reducer-0 reducer-1
让我们使用 grep 来查找一些单词的频率。
michal@michal-ThinkPad-T490s:/mnt/nfs/job-2024-04-28-17-13-53$ grep -w zverkov reducer-0 reducer-1
reducer-1:zverkov,112
michal@michal-ThinkPad-T490s:/mnt/nfs/job-2024-04-28-17-13-53$ grep -w the reducer-0 reducer-1
reducer-1:the,822175
michal@michal-ThinkPad-T490s:/mnt/nfs/job-2024-04-28-17-13-53$ grep -w mapreduce reducer-0 reducer-1
michal@michal-ThinkPad-T490s:/mnt/nfs/job-2024-04-28-17-13-53$
michal@michal-ThinkPad-T490s:/mnt/nfs/job-2024-04-28-17-13-53$ grep -w map reducer-0 reducer-1
reducer-1:map,188
michal@michal-ThinkPad-T490s:/mnt/nfs/job-2024-04-28-17-13-53$ grep -w reduce reducer-0 reducer-1
reducer-0:reduce,123
遗憾的是,在古腾堡计划最流行的 100 本书中没有提到 MapReduce……也许有一天?
最后一点,请注意这些输出文件如何按键对结果空间进行分区。当我们查找一个单词时,它只存在于一个文件中!这几乎就像我们做对了什么!
如果您已经读到这里,您不妨查看GitHub 仓库。您已经熟悉SQLite 存储格式内部。研究和撰写这些文章需要大量时间和精力。为确保您不会错过下一篇文章,请考虑订阅或关注我。