了解我们如何为 PostgreSQL 配备高级索引技术,使其与其他专门的向量数据库(如 Pinecone)一样快。
译自 How We Made PostgreSQL as Fast as Pinecone for Vector Data,作者 Matvey Arye。
我们最近宣布开源 pgvectorscale,这是一个新的 PostgreSQL 扩展,为向量数据提供了高级索引技术。Pgvectorscale 为 pgvector 数据提供了一种新的索引方法,显著提高了近似最近邻 (ANN) 查询的搜索性能。这些查询对于利用现代向量嵌入技术来促进,它允许查找与查询语义搜索类似的内容含义至关重要。反过来,这支持了诸如检索增强生成 (RAG)、摘要、聚类或通用搜索之类的应用程序。
在我们的公告文章中,我们描述了我们的新 StreamingDiskANN 向量索引如何让我们比为此目的创建的定制专用数据库(如 Pinecone)更快地执行向量搜索。我们还观察到,如果定制数据库不更快,那么就没有理由使用它们,因为它们不可能与 PostgreSQL 等通用数据库丰富的功能集和生态系统竞争。
在本文中,我们将深入探讨允许我们“突破速度障碍”并在 PostgreSQL 中创建快速向量索引的技术贡献。我们将介绍我们做出的三项技术改进:
实现 DiskANN 算法,允许将索引存储在 SSD 上,而不是必须驻留在内存中。由于 SSD 比 RAM 便宜得多,因此这极大地降低了存储大量向量的成本。支持流式后过滤,即使应用了辅助过滤器,也能进行准确的检索。相比之下,如果过滤器排除了前 ef_search 个向量,则 HNSW(分层可导航小世界)索引将无法准确检索数据。Pinecone 之前在将自己与 pgvector 进行比较时抱怨过这个问题。猜猜看;通过开源的力量,这个问题已经得到解决。开发一种全新的向量量化算法,我们称之为 SBQ(统计二进制量化)。与现有的 BQ(二进制量化)和 PQ(乘积量化)算法相比,该算法提供了更好的准确性与性能权衡。
DiskANN 算法是由微软开发,它的目标是存储非常大量的向量(想想微软的规模)。在如此大的规模下,将所有内容存储在内存中在经济上是不可行的。因此,该算法旨在支持在 SSD 上存储向量并使用更少的 RAM。它的细节在论文中描述得很好,因此我下面只会提供一些直觉。
DiskANN 算法是一种基于图的搜索算法,如 HNSW。此领域的基于图的算法有一个众所周知的问题:查找与起始位置“非常远”的项目很昂贵,因为它需要大量跳跃。
HNSW 通过引入一个分层系统来解决这个问题,其中第一层(顶部)只有“远程”边,可以快速让你进入正确的邻近区域,并具有指向较低层节点的指针,允许你以更精细的方式遍历图。这解决了远程问题,但通过分层系统引入了更多间接,这需要更多随机访问,从而迫使图进入 RAM 以获得良好的性能。
相比之下,DiskANN 使用单层图,并通过允许引用远端节点的邻居边在图构建期间解决远程问题。单层结构简化了算法并减少了搜索期间必要的随机访问,从而可以有效地使用 SSD。
通常,在搜索语义上相似的项目时,你希望使用其他过滤器来约束搜索。例如,文档通常与一组标签相关联,你可能希望通过要求标签匹配和向量相似性来约束搜索。

图 1:两阶段后过滤的问题在于,如果匹配记录未位于第一阶段截止之前,最终答案将不正确。
对于许多基于 HNSW 的索引(包括 pgvector 的实现)来说,这是一个挑战,因为索引从索引中检索预设数量的记录(由 hnsw.ef_search 参数设置,通常设置为 1,000 或更少)在应用辅助过滤器之前。如果检索到的集合中没有足够的项目(例如,前 1,000 个项目)与辅助过滤器匹配,则会错过这些结果。
图 1 说明了在使用 hnsw.ef_search=5 查找与给定查询最接近的两个向量并且匹配标签“department=engineering”时遇到的此问题。在此场景中,具有正确标签的第一个项目是与查询最接近的第七个向量。
由于向量搜索仅返回最接近的五个项目,并且没有一个与标签过滤器匹配,因此不会返回任何结果!这是一个没有留下任何结果的极端示例,但只要检索到的集合中匹配过滤器的项目少于 k 个项目,就会出现一些准确性损失。

图 2:流式过滤通过公开一个*get_next()*函数来产生正确的结果,该函数可以连续调用,直到找到正确数量的记录。
相比之下,我们的 StreamingDiskANN 索引没有“ef_search”类型截止。相反,如图 2 所示,它使用流式模型,允许索引连续检索给定查询的“下一个最接近”项目,甚至可能遍历整个图!Postgres 执行系统将不断请求“下一个壁橱”项目,直到它匹配满足附加过滤器的 LIMIT N 个项目。这是一种后过滤形式,绝对不会降低准确性。
顺便说一句,Pinecone 在其比较中对“ef_search”类型限制对 pgvector 进行了大肆宣传](https://www.pinecone.io/blog/pinecone-vs-pgvector/?ref=timescale.com)。但是,随着 StreamingDiskANN 的引入,此批评不再适用。这只是展示了开源项目快速减轻限制的能力。
许多向量索引使用压缩来减少向量存储所需的空间,并以牺牲一些准确性为代价使索引遍历更快。常见的算法是乘积量化 (PQ) 和二进制量化 (BQ)。事实上,pgvector 的 HNSW 索引刚刚在其最新的 0.7.0 版本中添加了 BQ(欢呼!)。
大多数向量数据库检索 K 个结果的工作方式如下。系统首先使用近似量化差异检索 N 个结果(N>K),然后通过重新评分来“纠正”误差。它计算 N 个结果的完全距离,按完全距离对列表进行排序,并返回距离最小的 K 个项目。然而,即使重新评分,准确性也很重要,因为它允许您减小 N(从而更快地查询)并增加准确结果位于 N 个预取结果集合中的机会。
我们研究了 BQ 算法,并对其产生的准确性损失感到不满意。我们还立即看到了一些可以改进它的捷径。在调整算法时,我们开发了一种新的压缩算法,我们称之为统计二进制量化 (SBQ)。
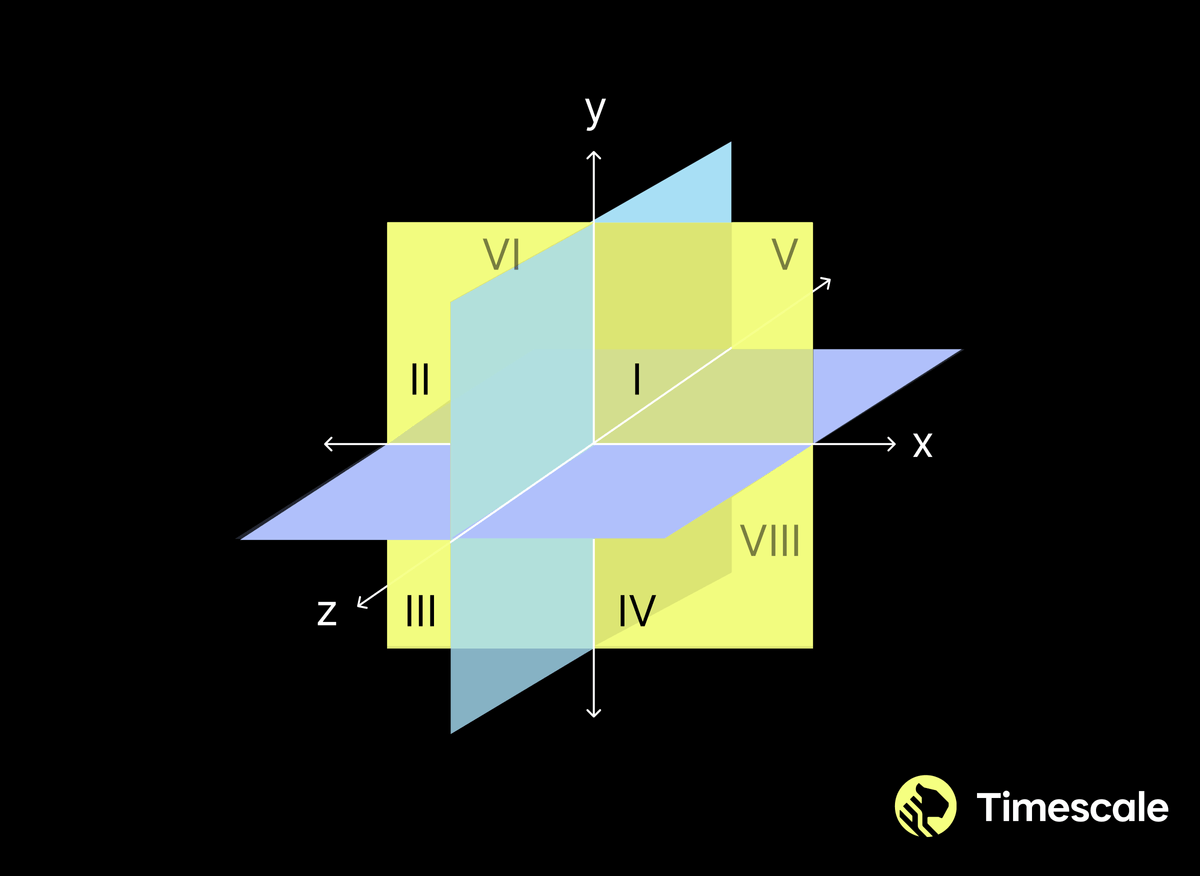
BQ 压缩算法以一种非常简单的方式将浮点向量转换为二进制向量:对于向量中的每个元素,如果值大于 0.0,则将二进制值设为 1;否则,将二进制值设为 0。然后,距离函数简单地变为 XOR 函数。为什么是 XOR?好吧,你会发现许多数学解释(我们都不太喜欢),但我们使用的直觉是二进制向量将空间划分为象限,如图 3 所示,而 XOR 函数只是计算从一个象限到另一个象限需要穿过多少个平面。

图 3:三个维度的 BQ。象限 1 由二进制向量 [1,1,1] 表示,任何落入该象限的向量都将具有 0 的距离。与其他象限中的向量的距离随着不同维度的数量而增加。
让我们感到奇怪的一件事是每个维度的截止值始终为 0.0。这很奇怪,因为在分析真实的嵌入时,我们之前发现每个维度的平均值甚至不近似为 0.0。这意味着我们在 BQ 中定义的象限没有将点空间一分为二,从而错失了差异化的机会。
直觉上,您希望切割平面的“原点”位于所有动作的中间,但在 BQ 中,它偏离了中心。解决方案非常简单:我们使用学习通道来推导出每个维度的平均值,然后将浮点值截断设置为平均值,而不是 0.0。因此,当且仅当浮点值大于维度的平均值时,我们将元素的二进制值设置为 1。
但随后我们又注意到另一件奇怪的事情:压缩算法对 1,536 个维度比对 768 个维度效果更好。这几乎没有道理,因为文献强烈暗示维度更高的难题比维度更低的问题更难(所谓的“维度灾难”)。但在这里,情况恰恰相反。
然而,从象限类比的角度思考,这似乎有道理——在 768 个维度中,象限会更少,每个象限都会更大,因此差异性更小。所以我们问自己,我们能否用 768 个维度创建更多象限?
我们的方法是将每个浮点维度转换为两位(我们稍后进行了概括)。其想法是使用平均值和标准差来推导出 z 分数(一个值与平均值的距离,由标准差标准化),然后将 z 分数划分为三个区域。然后我们将三个区域编码为两位,以便相邻区域的 XOR 距离为 1,并且距离随着 z 分数距离而增加。在具有三个区域的两位情况下,编码为 00、01、11。
通过实验,我们发现两比特编码确实有助于提高 768 维情况下的准确性。因此,默认情况下,我们对维度少于约 900 的任何数据使用两比特编码,否则使用一位编码。在一个具有 768 个维度的数据集的代表性示例中,从一位编码切换到两比特编码时,召回率从 96.5% 提高到 98.6%,在如此高的召回率水平下,这是一个显著的改进。
总之,这些技术帮助我们实现了更好的准确性/性能权衡。
我们在本文中介绍的三种技术使我们能够为 PostgreSQL 中的向量数据开发一流的索引,其性能可与 Pinecone 等定制数据库相媲美。我们通过利用 PostgreSQL 提供的大部分基础设施(包括缓存、WAL(预写式日志记录)和关联的恢复基础设施以及坚如磐石的磁盘写入系统)来实现这一点,而团队规模很小。
我们使用 Rust 编写了此内容,使用 框架来编写 PostgreSQL 的 Rust 扩展。这进一步加快了开发速度,因为我们可以依靠 Rust 和 PGRX 提供的一些安全保证,同时为代码的棘手部分(如磁盘 I/O)开发我们自己的安全包装器。我们认为,这种工具组合对于开发数据库功能和扩展 PostgreSQL 的覆盖范围非常有用且强大。PGRX
在过去的几个月里,我们的团队一直在不知疲倦地为 PostgreSQL 配备这些针对向量数据的新型高级索引技术。我们的目标是帮助 PostgreSQL 开发人员成为 AI 开发人员。但为此,我们需要您的反馈。
以下是如何参与:
- 与您的朋友和同事分享新闻:在 X/Twitter 和 Threads 上分享我们宣布 pgai 和 pgvectorscale 的帖子。我们承诺会转发。LinkedIn
- 提交问题和功能请求:我们鼓励您提交问题和功能请求,以获取您希望看到的、您发现的错误以及您认为可以改进这两个项目的功能。
- 做出贡献:我们欢迎社区对 pgvectorscale 和 pgai 的贡献。Pgvectorscale 用 Rust 编写,而 pgai 使用 Python 和 PL/Python。特别是对于 pgai,请告诉我们您希望看到支持哪些模型,尤其是开源嵌入和生成模型。请参阅 pgai GitHub了解更多信息。
- 在您的 PostgreSQL 云中提供 pgvectorscale 和 pgai 扩展:Pgvectorscale 和 pgai 是 Apache 2.0 许可证 下的开源项目。我们鼓励您在您的托管 PostgreSQL 数据库即服务平台上提供 pgvectorscale 和 pgai,我们甚至可以帮助您传播信息。通过我们的 联系我们表格 进一步讨论 pgai 和 pgvectorscale。
- 立即使用 pgai 和 pgvectorscale:您可以在 pgai GitHub 和 pgvectorscale GitHub 存储库中找到安装说明。您还可以在 Timescale 的云 PostgreSQL 平台上的任何数据库服务中访问 pgai 和 pgvectorscale。对于生产向量工作负载,我们提供对使用 Timescale 上的 pgvector 和 pgvectorscale 的向量优化数据库的私有测试版访问。在此注册以获得优先访问权限