将 Pinecone 与使用 pgvector 和 pgvectorscale 的自托管 PostgreSQL 在 5000 万个向量的基准测试中进行比较,包括查询延迟、查询吞吐量和成本。
译自 Pgvector vs. Pinecone: Vector Database Comparison,作者 Avthar Sewrathan。
Pinecone 和 带有 pgvector 扩展的 PostgreSQL 是在开发 AI 应用程序时最常用的两个向量数据库。一方面,Pinecone 是一个专有托管向量数据库,专门设计用于向量工作负载。另一方面,PostgreSQL 是一个流行且强大的通用关系数据库,带有 pgvector 扩展,增加了对向量存储和搜索的支持。
PostgreSQL 和 pgvector 都是开源的,可以灵活地进行本地部署、自我管理或从多个托管数据库提供商(包括 Timescale)进行部署。PostgreSQL 是一个成熟的数据库,具有高可用性、流复制、时间点恢复和可观察性等高级生产必需功能。Pinecone 的开发专注于执行快速向量搜索,但在操作功能方面明显不够成熟。
因此,问题是:在构建 AI 应用程序时,您需要像 Pinecone 这样的独立向量数据库,还是可以使用 PostgreSQL,这是一个您可能已经熟悉且知道如何操作(并且已经在您的数据堆栈中部署)的数据库?更重要的是,对于在生产 AI 应用程序(如 RAG(检索增强生成)、搜索和 AI 代理)中常见的、大规模的向量工作负载,哪一个才是更好的选择?
在这篇博文中,我们比较了 Pinecone 和带有 pgvector 的 PostgreSQL 的性能、成本和易用性,但增加了一个转折点,我们还考虑了 pgvectorscale,这是一个新的开源 PostgreSQL 扩展,它基于 pgvector 构建,以获得更高的性能和可扩展性,使 PostgreSQL 成为更适合 AI 应用程序的数据库。
Pgvectorscale 作为扩展向 PostgreSQL 添加了专门的数据结构和算法,用于大规模向量搜索和存储。
Pgvectorscale 通过使用新的搜索索引 StreamingDiskANN 来补充 pgvector,该索引专为高性能和经济高效的可扩展性而构建。StreamingDiskANN 克服了内存索引(如 HNSW(分层可导航小世界))的限制,通过将索引存储在磁盘上,使其在向量工作负载增长时运行和扩展更具成本效益。
Pgvectorscale 还增加了统计二进制量化,这是一种压缩技术,由 Timescale 的研究人员开发,它通过提高使用量化来减少向量存储所需空间时的准确性来改进标准二进制量化技术。这使得索引遍历更快,而不会牺牲高精度。
在我们开始基准测试之前,要了解有关 pgvectorscale 的更多信息。有关 pgvectorscale 的更多信息,请查看 pgvectorscale GitHub 存储库 . 对于那些寻求深入技术细节的人, 这篇关于我们构建它的原因的文章,我们的工程团队在这篇文章中进行了详细阐述。
在我们“深入”了解我们如何比较 Pinecone 与带有 pgvector 和 pgvectorscale 的 PostgreSQL 的方法之前,让我们总结一下我们为那些寻找 TL;DR 的人发现的内容:
- 我们创建了 ANN 基准工具的分支 来比较 PostgreSQL(pgvector 和 pgvectorscale)在 5000 万个 Cohere 嵌入数据集上的性能与 Pinecone 的性能。
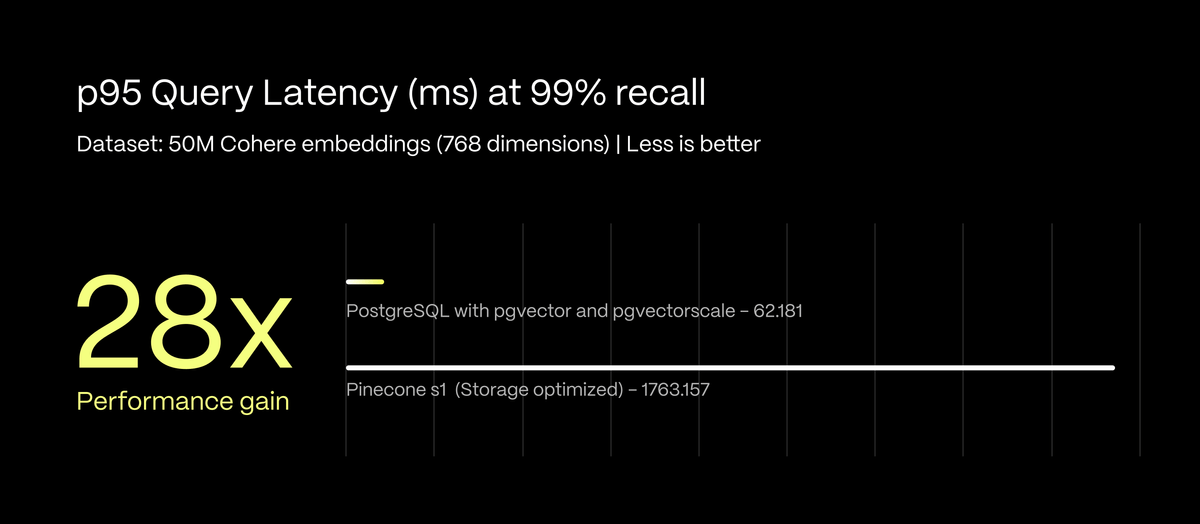
- 与 Pinecone 的存储优化索引 (s1) 相比,带有 pgvector 和 pgvectorscale 的 PostgreSQL 在recall 为 99% 的近似最近邻查询中实现了 28 倍更低的 p95 延迟和 16 倍更高的查询吞吐量,所有这些在 AWS EC2 上自托管时的每月成本都降低了 75%。
- 与 Pinecone 的性能优化索引 (p2) 相比,带有 pgvector 和 pgvectorscale 的 PostgreSQL 在recall 为 90% 的近似最近邻查询中实现了 1.4 倍更低的 p95 延迟和 1.5 倍更高的查询吞吐量,所有这些在 AWS EC2 上自托管时的每月成本都降低了 79%。
借助 pgvectorscale 和 pgvector,开发人员现在可以使用开源通用 PostgreSQL 数据库来实现与 Pinecone 等专用向量数据库相当(通常是更优)的性能。
总的来说,我们证明即便对于生产环境 AI 应用中常见的较大规模矢量工作负载,PostgreSQL 就已足够。并且开发者可以抵制追逐新兴数据库的诱惑,继续依赖他们熟知并喜爱的 PostgreSQL 基础,并辅以专门构建的性能和可扩展性扩展。这也是对 PostgreSQL 社区的承诺和持续努力的证明,我们对此感到自豪。
既然您知道了目的地,那么让我们开始基准测试之旅。
基准测试工具:我们使用业界标准的一个分支开源工具 ANN-Benchmarks 来对 Pinecone 和带有 pgvectorscale 的 PostgreSQL 进行基准测试。在测试性能之前,我们对它进行了修改,以便在使用多线程和运行不同的查询以预热(相对于测试)索引时正确测量每秒查询数 (QPS)。您可以在我们对 ANN-Benchmarks 分支所做的此标记中找到我们所有的修改。
数据集:5000 万个 768 维的 Cohere 嵌入。该数据集是通过连接多个 Cohere 维基百科数据集创建的,直到我们在训练数据集中有 5000 万个 768 维的向量,在测试数据集中有 1000 个。数据集的链接在此处公开提供:
- Cohere/wikipedia-22-12-en-embeddings
- Cohere/wikipedia-22-12-simple-embeddings
- Cohere/wikipedia-22-12-de-embeddings
客户端机器详细信息:独立的客户端机器运行 ANN-Benchmarks 工具。此客户端机器与 Pinecone 索引和 PostgreSQL 机器位于同一区域,以确保我们在网络延迟方面拥有公平的竞争环境。此客户端机器有 16 个 CPU 和 64 GB RAM。我们在基准测试开始之前下载了数据集;它不会在运行期间进行流式传输。我们为 Pinecone 使用了 Python 客户端的 gRPC 版本,它为我们提供了比 HTTP(S) 版本更好的结果。
测试方法:客户端在每个基准测试中运行 29000 个查询,使用训练向量来“预热”系统。然后,客户端使用与预热集不同的 1000 个“真实”测试向量进行查询。我们仅使用测试向量的数字作为结果。
基于 Pod 的索引:我们对三个基于 Pinecone Pod 的索引 p1、p2 和 s1 进行了基准测试。我们没有对 Pinecone 无服务器索引进行基准测试,因为查询受到速率限制。Pinecone 建议仅将无服务器产品用于低于 5 QPS 的工作负载,因此在测试时不适合我们基准测试的规模。请参阅下表了解 Pinecone 基于 Pod 的索引的说明。

比较 Pinecone 基于 Pod 的索引类型的表格。来源:“伟大的算法还不够”,Pinecone 博客。
一般方法:我们对许多不同的 Pinecone 基于 Pod 的索引配置进行了基准测试。我们尝试了具有不同 Pod 大小和副本设置的存储优化 (S1) 和性能优化 (P1、P2) Pod 类型。由于时间和预算有限,这是许多开发人员面临的现实问题,我们没有探索所有可能的组合,但尽力探索了该空间。
性能最佳的配置:我们找到的最佳配置如下。
存储优化 (s1)
- Pod 类型:s1
- Pod 大小:x4
- Pod:5
- 副本:2
- 总 Pod:40
- Pod 饱和度:40 %
- 客户端线程:32
- 月度成本:3241 美元
性能优化 (s1)
- Pod 类型:p1
- Pod 大小:x8
- Pod:8
- 副本:1
- 总 Pod:64
- Pod 饱和度:70 %
- 客户端线程:16
- 月度成本:5186 美元
性能优化 (p2)
- Pod 类型:p2
- Pod 大小:x8
- Pod:4
- 副本:1
- 总 Pod:32
- Pod 饱和度:90 %
- 客户端线程:16
- 月度成本:3889 美元
一般方法:我们尝试了各种 PostgreSQL 机器、数据库和索引配置。我们在 AWS EC2 上自托管 PostgreSQL 实例,以准确反映开发人员运行完全开源软件的体验。
机器详细信息:
- 实例类型:r6id.4xlarge
- CPU:16
- RAM:128 GB
- 1x950 GB 本地附加 NVMe SSD
- 操作系统:Ubuntu 23.10
- 月度成本:835 美元
PostgreSQL 设置
- 我们将数据目录放在本地附加的 NVMe SSD 上
- PostgreSQL 版本 16.3;pgvector v0.7.0
- 我们使用 timescaledb-tune 来调整 PostgreSQL 设置
StreamingDiskANN 索引:没有使用 pgvector 中的(HNSW 或 IVFFlat 索引,对于大规模近似最近邻搜索,我们使用了 StreamingDiskANN 索引。pgvector 的 StreamingDiskANN 索引是 pgvectorscale 扩展中引入的一个关键创新。
StreamingDiskANN 索引参数:与 Pinecone 不同,pgvectorscale 的 StreamingDiskANN 索引向用户公开参数,以便为其特定工作负载配置搜索性能。我们使用了以下索引参数;大多数是默认值,非默认参数用星号 (*) 标记:
- num_neighbors: 50
- search_list_size: 100
- max_alpha: 1.2
- query_rescore: 90% recall 为 115,99% recall 为 400*
- query_search_list_size: 90% recall 为 35,99% recall 为 75*
- num_bits_per_dimension: 2
- 所有 5000 万个向量都在一个表和索引中
概述:Pinecone 的 s1 索引与使用 pgvector 和 pgvectorscale 的 PostgreSQL 最为“相似”,因为 (1) 它针对存储进行了优化,使其适用于 5000 万个向量的数据集,并且 (2) 它是唯一基于 pod 的索引类型,它将原始向量保存在磁盘上,而不是完全保存在内存中,这反映了 pgvectorscale 的 StreamingDiskANN 索引存储架构。s1 pod 是 Pinecone 最准确的 pod,达到了 99% 的recall ,尽管代价是查询速度较慢。
PostgreSQL 与 pgvectorscale 与 Pinecone s1 的结果摘要:
- 使用 pgvector 和 pgvectorscale 的 PostgreSQL 实现了 99% recall 时近似最近邻查询的 p95 延迟降低了 28 倍。

- 使用 pgvector 和 pgvectorscale 的 PostgreSQL 实现了 99% recall 时近似最近邻查询的查询吞吐量(每秒查询数)提高了 16 倍。

- PostgreSQL 的成本比 Pinecone s1 的成本低 75%(Pinecone 每月 3241 美元,而 AWS EC2 上自托管每月 835 美元)。

概述:Pinecone 的 p2 索引是 Pinecone 性能最高的索引。它使用基于图的索引,并将原始向量存储在内存中,这与 pgvectorscale 的 StreamingDiskANN 不同,后者结合了内存和磁盘。它还以速度换取准确性,最高可实现 90% 的recall 。我们发现,使用 pgvectorscale,PostgreSQL 与 Pinecone 的 p2 性能优化索引相当,甚至优于后者。
PostgreSQL 与 pgvectorscale 与 Pinecone p2 的结果摘要:
- PostgreSQL 实现了 90% recall 时近似最近邻查询的 p95 延迟降低了 1.4 倍。

- PostgreSQL 实现了 90% recall 时近似最近邻查询的查询吞吐量(每秒查询数)提高了 1.5 倍。

- PostgreSQL 的成本比 Pinecone p2 的成本低 79%(Pinecone 每月 3889 美元,而 AWS EC2 上自托管每月 835 美元)。

由于其 PostgreSQL 基础,与 Pinecone 相比,Pgvectorscale 和 pgvector 具有以下操作优势:
- 丰富的备份支持:支持一致性备份、流式备份以及增量和完全备份。相比之下,Pinecone 仅支持手动操作,以获取其数据的一个非一致性副本,称为“集合”。
- 时间点恢复:用于从操作员错误中恢复。
- 高可用性:适用于需要高正常运行时间保证的应用程序。
- 灵活性和控制:Pinecone 无法控制近似最近邻搜索中的准确性-性能权衡。Pinecone 似乎只有三个选项来控制索引准确性;开发人员可以使用 s1、p1 或 p2 索引类型。这将开发人员锁定为选择准确但非常慢的索引 (s1) 或快速但不太准确的索引 (p2),而没有介于两者之间的选项。相比之下,pgvectorscale 可以使用索引选项根据生产要求进行微调。此外,PostgreSQL 生态系统支持多种索引类型,例如,可以加速对关联元数据的查询或执行全文搜索。此外,部分索引可以加速对向量和元数据搜索的关键组合的查询。
- 更好的可观察性和调试工具:计数、请求错误、请求延迟、向量计数和 pod 饱和度。这些可以在其 Web 控制面板中查看,或通过 Prometheus 或 Datadog 导出。虽然这很有价值,但实际上只是最低限度的,当某些内容执行不佳时,几乎没有信息可用于调试。另一方面,PostgreSQL 拥有非常丰富的可观测工具生态系统。例如,Prometheus 的 postgres_exporter 默认收集数百项指标。当在自托管时可以暂时忽略机器级和操作系统级可观测工具,PostgreSQL 提供了查看日志消息和自动记录慢查询、利用 EXPLAIN 命令获取有关如何执行查询的说明、使用 pg_stat_statements 跟踪一段时间内查询计划和执行的统计信息、使用累积统计信息系统跟踪数据库所有方面中有关统计信息、使用 pg_buffercache 查看 PostgreSQL 内存的内容以及使用 pg_prewarm 修改 shared_buffers 的内容的能力。如果 PostgreSQL 数据库中出现某个问题,“失常”,你可以使用多种工具来诊断问题。
Pgvectorscale 是一个新的开源扩展,使开发人员能够使用 PostgreSQL 构建更具可扩展性的 AI 应用程序,并具有更高性能的嵌入式搜索和经济高效的存储。
为了测试 pgvectorscale 的性能影响,我们创建了 ANN 基准工具的一个分支,以比较 PostgreSQL 和 Pinecone 在 5000 万个 Cohere 嵌入 数据集上的性能。
与 Pinecone 的存储优化索引 (s1) 相比,PostgreSQL 与 pgvector 和 pgvectorscale 实现 28 倍更低的 p95 延迟和 16 倍更高的查询吞吐量,用于 99% recall 的近似最近邻查询,所有这些都以 25% 的月度成本实现。
与 Pinecone 的性能优化索引 (p2) 相比,PostgreSQL 与 pgvector 和 pgvectorscale 实现 1.4 倍更低的 p95 延迟和 1.5 倍更高的查询吞吐量,用于 90% recall 的近似最近邻查询,所有这些都以 21% 的月度成本实现。
借助 pgvectorscale,开发人员现在可以使用开源通用 PostgreSQL 数据库来实现与 Pinecone 等专用向量数据库相当(通常更优)的性能。
Pgvector和pgvectorscale在PostgreSQL许可下均为开源,您可以在 AI 项目中直接使用。
在 GitHub 存储库中,您可以分别找到 pgvector 和 pgvectorscale 的安装说明。您还可以通过 Timescale 云端 PostgreSQL 平台上的任何数据库服务来访问 pgvector 和 pgvectorscale。
对于生产向量工作负载,我们现在支持使用 Timescale 上的 pgvector 和 pgvectorscale 的经过向量优化的数据库的抢先体验计划。在此注册以获取优先访问权。
pgvector 和 pgvectorscale 都是开源社区项目。以下是参与的方式:
- 与您的朋友和同事分享新闻:在 X/Twitter 和 Threads 上分享我们宣布 pgvectorscale 的帖子。我们承诺会转发。
- 提交问题和功能请求:我们鼓励您提交问题和功能请求,以获取您希望看到的、您发现的错误以及您认为可以改进这两个项目的功能。前往 pgvectorscale GitHub 存储库 分享您的想法。
- 做出贡献:我们欢迎为 pgvectorscale 做出社区贡献。Pgvectorscale 用 Rust 编写。您可以在 pgvectorscale 存储库 中找到有关如何做出贡献的说明。
- 在您的 PostgreSQL 云中提供 pgvectorscale 扩展:pgvectorscale 是 PostgreSQL 许可证 下的开源项目。我们鼓励您在您的托管 PostgreSQL 数据库即服务平台上提供 pgvectorscale,甚至可以帮助您传播信息。通过我们的 联系我们表格 联系我们,并提及 pgvectorscale 以进一步讨论。