通过早期自愈克服托管 Kubernetes 的缺陷。
译自 From Fragile to Faultless: Kubernetes Self-Healing In Practice,作者 CSS Engineering。
由核心基础设施团队的工程团队成员 Grzegorz Głąb 和 Nibir Bora 撰写。
许多组织选择使用托管 Kubernetes 发行版,如 Azure Kubernetes Service (AKS),以便在无需大型工程团队操作 Kubernetes 集群的情况下快速启动并运行。这是 City Storage Systems 核心基础设施团队的核心设计原则。然而,多年来,我们了解到托管 Kubernetes 发行版的实际运营成本实际上并非为零。
即使是公有云也会偶尔出现故障。硬件故障、内核错误配置、网络瓶颈、有问题的推出、资源稀缺、安全漏洞等会导致持续数分钟或在某些情况下持续数周的复杂情况。在此博客中,我们将分享我们的经验,说明如果小故障得不到解决,可能会迅速升级并影响业务连续性。
我们设计了一个自我修复框架,而不是参与持续的救火行动,通常在短短 1 天内实施 Automation ,周转时间短。这些 Automation 有时是临时修复,直到云提供商解决问题,而另一些时候,它们成为我们平台可靠性的永久增强。虽然我们的旅程始于关注 AKS,但此框架是一种通用模式,可提高任何 Kubernetes 平台的弹性。
第一个自愈的用例被实现为一个单体程序。但是,当我们添加了新的用例时,我们发现了一些可重复利用的库,它们促使我们将程序组织成一个框架。该框架现在由 Automation 组成,每个 Automation 都解决一个特定的失效模式。 Automation 被实现为一个独立的 Detector 和一个 Fixer,它们或者是一个控制器,或者是一个 Go 程序。
Detector 负责收集信号并标记故障条件。有两种类型的 Detector - 集群级别(Deployment)和节点级别(DaemonSet)。集群级别 Detector 监视集群范围的故障事件,并具有监视或创建 API 服务器资源的权限。节点级别 Detector 监视节点级别故障(例如,错误配置的 OS 标志、镜像拉取问题、缺少 systemd 服务等),并具有特权主机访问权限。
Fixer 通过执行补救步骤来纠正或清理故障状态,从而补充 Detector。与 Detector 类似,有两种类型的 Fixer - 集群级别(Deployment)和节点级别(DaemonSet)。集群级别 Fixer 执行在集群级别资源上操作的补救操作,并具有监视 API 服务器资源的权限。节点级别 Fixer 在节点级别执行补救操作,或需要特权主机访问的操作。
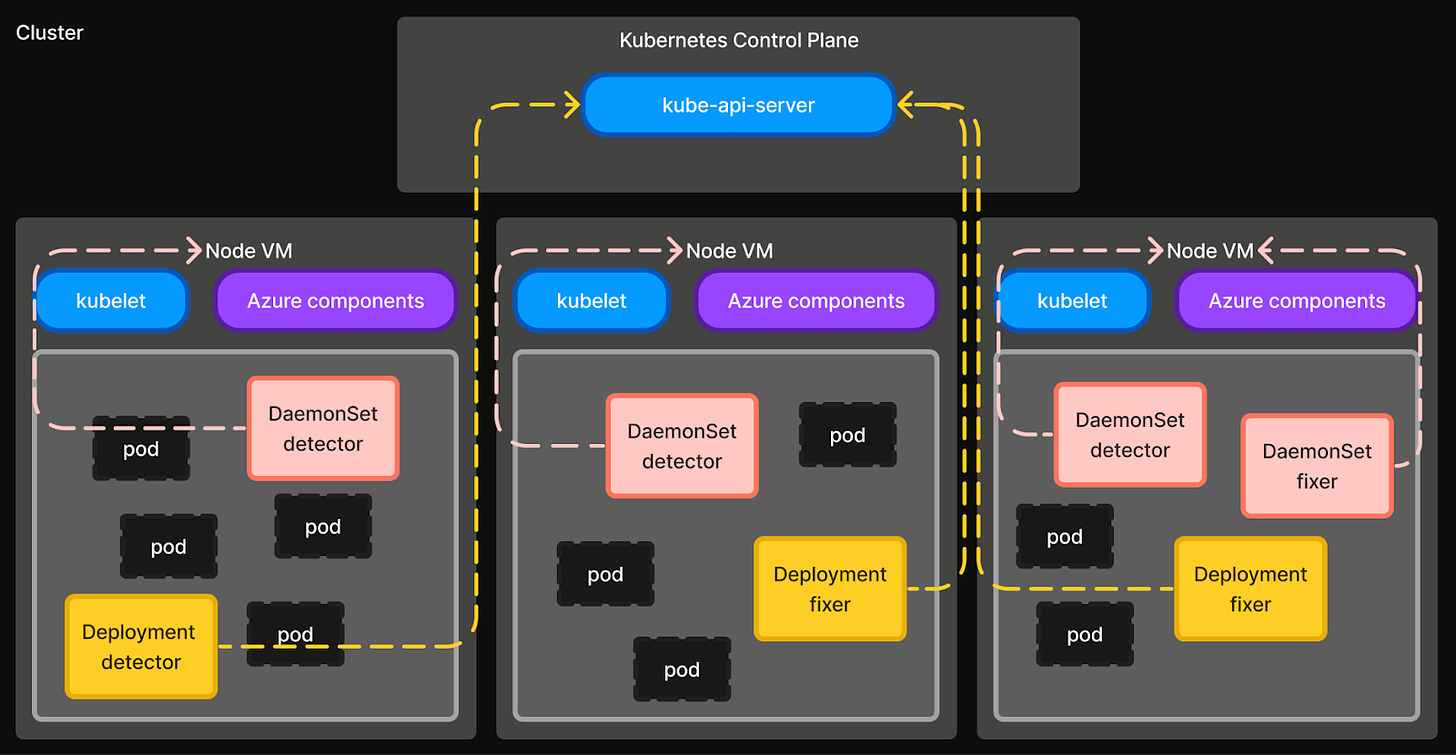
图 1:运行在 Kubernetes 集群中的自愈框架的架构图。
这种概括使我们能够保持框架的简单性和适当隔离权限。这是在需要时快速添加新 Automation 功能的关键。每当我们发现新的性能下降时,我们都会在所有集群中实施和部署相应的 Detector 和 Fixer 。以下 Automation 是一些示例,它们保护我们的内部开发人员和应用程序免受潜在影响,并且还显着减少了我们团队的支持工作 - 从工程时间的 30% 减少了一半。

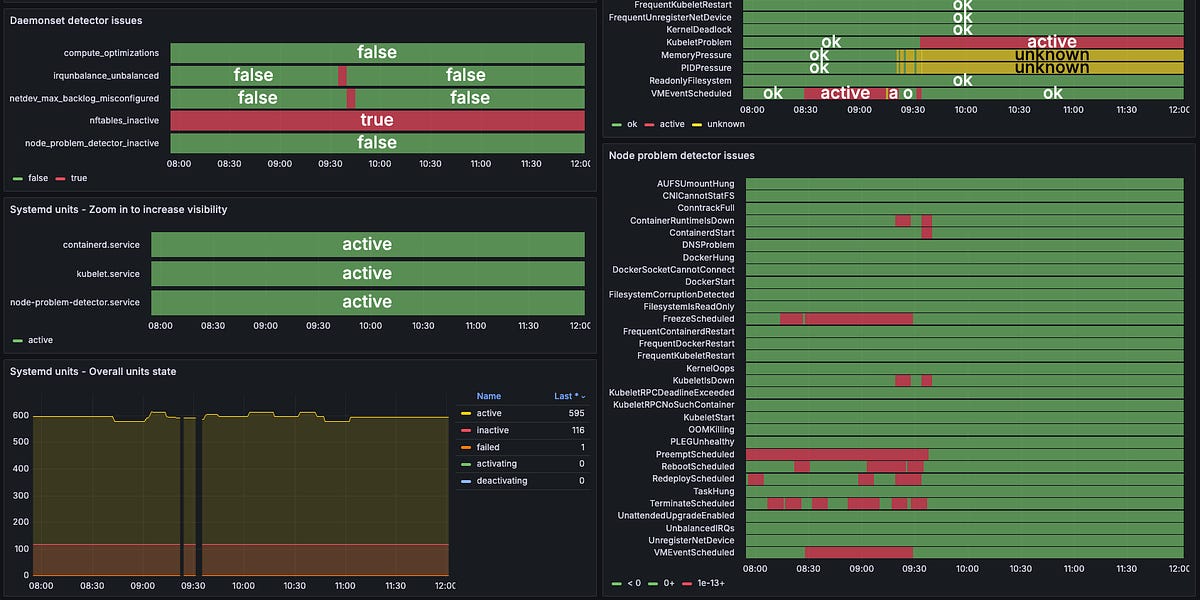
图 2:在我们 Kubernetes 平台上当前处于活动状态的自我修复自动化列表。
在过去的一年半中构建这些 Automation 功能教会了我们一些关键经验教训:
- Kubernetes 并不是最终产品。它是一个用于构建平台的框架。托管 Kubernetes 仍然受益于为开发人员创造杠杆作用的特定于业务的定制。
- 抽象不会消除底层。Kubernetes 虽然功能强大,但仍然要求我们深入到主机 VM 或内核层进行深度调试 - 这是我们通过经验磨练的一项技能。
- 成本优化具有可靠性税。优化成本需要通过提高对可靠性的警惕性来平衡。例如,在 Spot 节点上运行有状态工作负载要求我们在 Automation 方面进一步投资。
- 无法预测云错误。与其预测想象中的故障场景,不如优化诊断不可预见的问题和为其实施 Automation 的速度。例如,我们将所有节点故障信号整合到一个“节点检查器”仪表板中,使我们的开发人员能够在收到寻呼时迅速做出响应。
在以下部分中,我们将详细描述一些 Automation ,涵盖如何识别每种故障模式以及如何对其自愈进行 Automation 。
我们在 Kubernetes 平台上广泛使用 Spot 节点来优化资源成本,运行无状态和不太重要的有状态工作负载。但是,AKS 上的 Spot 节点缺乏任何 SLA,这可能导致潜在的突然抢占。我们经历了一次事件,其中大量 Spot 节点抢占导致多个有状态工作负载失败,从而导致级联应用程序故障并导致停机。
当 AKS 上的 Spot 节点被抢占时,在底层 VM 突然被移除前 30 秒会发出一个计划抢占事件。该节点未被隔离,工作负载未正常关闭,并且该节点未从 Kubernetes API 服务器注销。该节点对象在 5 分钟后因心跳失败而被清理之前,将保持没有物理 VM(请参阅问题 #3528)。发生这种情况时,无状态工作负载 Pod(由 Deployment 和 ReplicaSet 控制)将自动重新调度,但 StatefulSet Pod 不会。StatefulSet Pod 在 API 服务器中留下“幻影”Pod 对象(其中 .status.phase: Unknown),这对我们的有状态工作负载来说是不可接受的行为。
为了解决这个问题,我们实现了一个自愈 Automation ,它会拦截 Spot 节点抢占信号并优雅地驱逐受影响节点上的所有 Pod。一个 Detector 会监视 VMEventScheduled 节点条件(如下例所示),并创建一个 SpotNodePreemption 自定义资源(CR),其中包含修复程序的详细信息。然后,修复程序以 10 秒的宽限期驱逐 Pod。
.status.conditions: [
{
status: "True",
type: "VMEventScheduled",
reason: "VMEventScheduled",
message: "Preempt Scheduled : Tue, 14 May 2024 12:57:00 GMT",
lastHeartbeatTime: "2024-05-14T12:56:43Z",
lastTransitionTime: "2024-05-14T12:56:42Z"
}
]

图 3:为预占 Spot 节点上调度的 Pod 编制的 Kubernetes 事件示例时间表。

图 4:2023 年 11 月左右时段预占即时节点的大量预留量。
一旦此 Automation 投入使用,我们注意到一些 Spot 节点仍在没有计划的抢占事件的情况下终止。这是因为当节点问题 Detector (NPD) 查询 Azure 元数据服务以获取 VMEventSchedule 事件时,请求偶尔会失败,从而导致 NoVMEventScheduled 节点条件(如下例所示)。为了解决这个问题,我们添加了另一个自愈 Automation ,以便在抢占事件未被拦截时清理已终止的 Spot 节点。当 Spot 节点对象从 API 服务器中删除时, Detector 会创建一个 SpotNodeDeletion CR,并且修复程序会强制删除该节点上的所有 Pod 对象,假设它们不再可访问。
.status.conditions: [
{
...
type: "Unknown",
reason: "NoVMEventScheduled",
message: “Timeout when running plugin \"/etc/node-problem-detector.d/plugin/check_scheduledevent_consolidated.sh\": state - signal: killed. output - \"\"”
}
]
AKS 节点池建立在 Azure 虚拟机规模集 (VMSS) 基础设施之上。我们观察到 VMSS 层中的 VM 故障通常会使 AKS 节点不可访问。发生这种情况时,节点控制器会添加一个 NoExecute 污点,并且节点上的所有 Pod 都会在 5 分钟后被驱逐。虽然无状态 Pod 会自动重新调度,但 StatefulSet Pod 不会(请参阅问题 #54368 和 设计提案)。这可能导致由有状态工作负载(如 CockroachDB 或 OpenSearch)中的复制不足引起的数据丢失。
为了解决这个问题,我们实现了一个自愈 Automation ,它会监视 Kubernetes API 服务器以查找带有 node.kubernetes.io/unreachable 污点的节点对象。 Detector 会过滤掉被污点超过 5 分钟的节点,并且修复程序会强制删除这些节点上的所有 Pod(假设它们无法恢复),从而允许调度新的 Pod。

图 5:检测到的每日不可达节点(过去 3 个月)。

图 6:不可达节点修复器每天删除的 Pod(过去 3 个月)。
在调查由于 etcd 磁盘大小增加而导致的集群运行状况下降时,我们发现了 Succeeded Pod 作为重要因素。这些 Pod 由短暂的 cron 作业、没有控制器的 Pod(例如 Flink 作业)和驱逐的 Pod 创建。由于 kube-controller-manager 不会自动清理成功的 Pod,因此这是我们大型多租户集群中的一个问题。可以通过配置 --terminated-pod-gc-threshold 标志来修改此默认行为。但是,由于我们使用托管 Kubernetes,因此控制平面由云提供商管理,并且不可由用户配置。
为了解决此问题,我们实施了一种自修复 Automation ,用于监视 Kubernetes API 服务器,以查找具有以下任一条件的 Pod:
- status.phase = Succeeded
- status.phase = Failed,且
- pod.Status.Reason = Evicted
Detector 标记在这些阶段停留至少 15 分钟的 Pod。此阈值可按命名空间配置。相应的修复程序从 API 服务器中删除这些标记的 Pod。

我们注意到网络 IO 密集型工作负载中的数据包丢失率增加,最初认为是应用程序错误。但是,我们看到受影响工作负载的节点具有 VMFreezeEvents(请参阅 AKS 文档)。调查显示,来自节点网络接口的硬件中断仅由 8 个 CPU 核心中的 2 个不均匀地处理,导致这些核心上 100% 的利用率(请参阅 博客 中的详细调查)。重新启动 irqbalance 服务(它应该均匀地分配中断)解决了此问题。
为了解决此问题,我们实施了一种自修复 Automation ,用于标记 CPU 核心少于一半被配置为处理来自网络接口的中断的节点。这是通过检查 /proc/irq/IRQ#/smp_affinity 来完成的,它表示 CPU 核心与中断请求队列 (IRQ) 的关联性。相应的修复程序在主机 VM 上重新启动 irqbalance systemd 服务。我们还将每个节点用于 IRQ 的核心数公开为度量,以持续观察。上游问题后来在 ubuntu 的更高版本中得到修复(请参阅错误 #2038573)。

图 8:最近,存在不平衡 IRQ 的节点激增(在上游修复后)。
尽管进行了此修复,但仍有一些数据包丢失。这被追溯到网络接口接收队列中的积压。我们发现,如果接收队列大小设置为小于 10000,则会导致数据包丢失。为了解决此问题,我们实施了另一个 Automation ,用于标记 net.core.netdev_max_backlog 小于 10000 的节点。相应的修复程序在主机 VM 上将其重置为 10000。
在将我们的节点从 Ubuntu 迁移到 Azure Linux 操作系统时,我们注意到 nftables 并未在已迁移的节点上运行。Kubernetes 依赖于主机 VM 上的 nftables,用于在节点上进行 Pod 间路由规则和出口流量。这阻止了网络策略正确应用,导致节点上出现不规则的网络故障。经过调查,我们发现这是由于 nftables.conf 文件中缺少换行符(请参阅问题 #4144 和 [#7301](https://github.com/microsoft/azurelinux/issues/7301),以及拉取请求 #8310)。
为了解决此问题,我们实施了一种自修复 Automation ,用于标记主机 VM 未运行 nftables 的节点。相应的修复程序通过在末尾追加换行符来更正 nftables.conf 文件,并重新启动 nftables systemd 服务。

图 9:修复程序部署前节点的故障 nftables 数量。
AKS 运行 node-problem-detector (NPD) 以监视 节点运行状况 并标记在故障期间要移除的节点。它每 30 秒运行 10 次检查,并将输出注入节点条件。我们将这些条件集成到我们的可观察性堆栈中。在工作负载故障调查期间,我们注意到一个节点只有 4 个状态条件,而不是通常的 14 个(10 个来自 NPD,4 个来自 kubelet)。这让我们发现 NPD 未在该节点上运行。工作负载失败,因为容器运行时接口 (CRI) 在该节点上发生故障,从而阻止 kubelet 验证工作负载状态。
我们实施了一个自修复 Detector ,用于标记 NPD 未运行的节点。进一步的分析显示,25% 的节点存在此问题。自动终止这些节点被认为风险太大。相反,我们将所有节点上的节点操作系统回滚到以前的工作版本,并将问题上报给云提供商(请参阅问题 #3988,后来归因于已修复的上游 CVE。我们还为没有 NPD 的节点设置了自动警报,以防止未来出现问题。

图 10:没有检测到 node-problem-detector 的节点。
我们面临着针对具有大型容器映像(7-10GB)的工作负载的 ImagePullBackOff 错误激增。kubelet 错误消息(如下例所示)无济于事,并且工作负载数小时无法启动。有时在多次重试后,手动驱逐会有所帮助。一项在 Azure 托管 OS 磁盘 和 临时 OS 磁盘 上对写入速度进行基准测试的无关实验,让我们确定这些问题仅发生在具有托管 OS 磁盘的节点上。
Oct 31 11:57:43 aks-nodepool0392-17898922-vmss0000LX kubelet[2874]: E1031 11:57:43.120279 2874 remote_image.go:242] "PullImage from image service failed" err="rpc error: code = Canceled desc = failed to pull and unpack image \"cssacrprod.azurecr.io/chronorepo-companion-cron:efdc4a316aebcc878c38483b09bb939524dbd94a\": failed to commit snapshot extract-332345855-2JgL sha256:d2bd2b7dd52900b17c2e8d2f50d94273892a45d96a760f078aeb58bc54fbc160: context canceled" image="cssacrprod.azurecr.io/chronorepo-companion-cron:efdc4a316aebcc878c38483b09bb939524dbd94a"
我们实现了一个自修复 Detector ,通过解析 kubelet 日志来标记具有 ImagePullBackOff 错误的节点。目前,我们缺少自动修复程序。相反,我们为每个受影响的 Pod 发出自定义警告事件。受影响的工作负载可以重试,或者如果问题仍然存在,则为标签设置节点亲和性 ephemeral-storage = true。我们平台中所有具有临时 OS 磁盘的节点都有此标签。
为 Kubernetes 构建自修复解决方案使我们能够增强 Kubernetes 平台的可靠性,而不会给自己带来运营和支持负担。对于我们来说, Automation 被证明是扩展到数百个集群的正确原则。
那么,接下来是什么?我们不断向我们的自修复框架添加新的 Detector 和修复程序。低级别网络、嘈杂邻居问题、CPU 内核使用优化是我们积极研究如何自动检测和纠正问题的几个示例。此外,我们计划将该框架从平台缺陷扩展到应用程序缺陷。我们相信自修复的相同机制具有广泛的适用性。自修复是使平台的维护成本低于业务增长率的唯一答案。因此,我们认真考虑进一步投资。