昨晚在 Kubernetes 1.0 庆典上,我谈到了 Kubernetes 1.0 的发展历程,当时我坐在小溪对岸,而项目……
译自 Kubernetes: The Road to 1.0,作者 Brian Grant。
昨晚,我在 Kubernetes 1.0 庆典 上发表了关于 Kubernetes 1.0 之旅的演讲,地点就在我项目启动时所在的小溪对面,但 10 分钟的时间非常短,我只能浅尝辄止。Kelsey 并没有开玩笑,我确实有 30 张幻灯片,部分原因是我不确定观众想听什么,部分原因是我自己做笔记。
我写过关于设计背景的部分内容,但本文更多的是关于它如何产生的,以及从 Mountain View 方面(Borg 团队所在的地方)构建它的过程。Craig McLuckie、Joe Beda、Brendan Burns 和 Ville Aikas 在西雅图,Google Compute Engine 团队所在的地方。我将其大致分为 4 个学期,以及项目开始前的一段时间。
15 年前,即 2009 年初,我加入了 Google 的 Borg 控制平面团队。在那之前,我从事超级计算机工作超过 15 年,但 Borg 是一个多用户系统,上面、下面和旁边还有许多其他组件。我的“入门项目”是通过并发处理请求来提高可扩展性,因为在那之前的 1.5 年里,我一直在促进将 Google 的许多单线程 C++ 应用程序迁移到多线程,涉及 Linux(NPTL 尚未推出)、g++(线程安全注释)、线程原语(C++11 之前)、多线程 HTTP 服务器、改进的分析、文档和其他项目。
为了提高性能,我不仅需要了解实现,还需要弄清楚系统是如何使用的。在从事 Borg 的第一年,我发现 Borg 的控制平面架构和 API 在很多方面并不是真正为其使用方式而设计的。
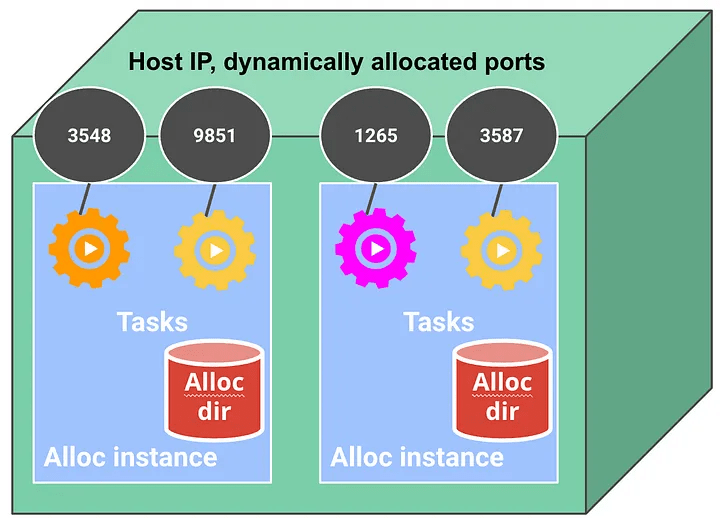
例如,Borg 并不是真正可扩展的,因此必须在其他服务和客户端中构建推出、批处理调度、cron 调度以及水平和垂直自动缩放等附加功能。这些其他服务会将数据嵌入到作业资源中,并持续轮询更改,例如新作业,这占 Borg 控制平面所有 API 请求的 99% 以上。通过 Watch API 订阅更改的能力仅受支持用于作业任务端点,方法是将动态调度的主机 IP 地址和动态分配的主机端口写入Chubby,这是启发了 Zookeeper 的键/值存储。

顺便说一句,在 Borg 上运行的工作负载普遍受到 Chubby 用于服务发现的影响,因为它们无法使用标准机制进行服务命名、发现、负载平衡、反向代理、身份验证等。我们希望现有应用程序能够在 Kubernetes 上运行,因此我们使动态分配的 Pod IP 地址可路由,这在当时是一个有争议的决定。
2010 年,我启动了一个名为 Omega 的研发项目,以重新设计 Borg 以适应其使用方式,并更好地支持 Borg 周围的生态系统。在很多方面,Kubernetes 更像是“开源 Omega”而不是“开源 Borg”,但它受益于从 Borg 和 Omega 中吸取的教训。
Omega 在其中心有一个基于 Paxos 的键/值存储,并带有 Watch API。在 Kubernetes 中称为 控制器 的组件异步运行,监视所需状态对象并回写观察到的状态。与 Kubernetes 不同,这些是存储中的单独记录,这有利于乐观并发,但拼接起来有点困难。我们也没有围绕存储包装一个统一的 API,尽管有人提出过这样的建议。

Borg 未按设计使用方式使用的另一个示例是,Borg 中的 Allocs 是跨机器预定的资源预留集合,即集群的水平切片。作业任务可以安排到这些插槽中。这是一个相当复杂的模型,使得诸如调试和水平自动扩缩等多项事情变得更加复杂,很少有用户利用这些优势。大多数 Allocs 用户将特定作业任务集固定到实例中。这导致了将这些容器捆绑起来,形成 Omega 中称为调度单元的复制和调度的一级单元的想法,这些单元最终在 Kubernetes 中被命名为 Pod。

我们在 Kubernetes 中将 标签 作为核心概念。Borg 最初没有标签。这个想法的灵感来自用户尝试将有关其作业的元数据打包到长达 180 个字符的作业名称中,然后使用正则表达式对其进行解析。Omega 中的对应概念更为复杂,但不需要额外的子结构。一个简单的映射就足够了。类似地,注释 的灵感来自 Borg 客户端尝试将信息塞进一个 notes 字符串中,这有点像用户代理(我们在 Google 的 RPC 库中没有),但它保留在作业中。

标签的来源(仅显示标签值以简化)
Kubernetes 中的 cpu 和内存请求和限制规范 比 Borg 的更一致,并且与 Omega 的相比更简单。
我们能够挑选有效的方法,丢弃无效的方法,简化一些过于复杂的方法,并再次迭代一些方法。Omega 中的许多概念,例如调度单元,在 Kubernetes 中被直接重新使用了。有些,比如 污点和容忍,被简化了,但名称与 Omega 中的相同。术语“ 声明” 也来自 Omega。中断预算 的想法来自 Omega,灵感来自 Borg 的中断代理服务。
这 10 年的经验教训让 Kubernetes 比那些基于 Docker 重新起步的项目(例如 libswarm)拥有先发优势。这还使 Kubernetes 比原本预期的更早变得复杂,但大多数功能都得到了广泛使用。
所有这些来自 Borg 和 Omega 的经验使我们很快地开始了比赛。2013 年下半年,当我们开始讨论要构建哪种容器产品时,我开始勾勒 API。它已经有了当今 Kubernetes 用户可以识别的形状。这是我在第一次原型演示的同一场会议中在那段时间所做的演示的摘要:
- CRUD:配置和 API 的架构相同
- 调度单元(sunits,又名分子):资源、任务、数据的捆绑包
- 新/更新实例的 sunit 原型
- 单独的复制规范指定所需数量
- 潜在的异构 sunit 集由标签、标签查询标识;没有索引
- 正交功能解耦

调度单元(Pod)概述

多种资源类型链接在一起
尽管我们还没有获得开源任何内容的批准,并且仍在讨论要构建哪种产品,但我们在此期间开始积极地开展该项目。我们吸引了更多的人,实际上是相当多的人。不幸的是,我无法再访问我的内部笔记,所以我可能无法在这里一一列出他们的名字,但会列出一些。
有些人,比如 Tim Hockin、Dawn Chen 和 Eric Tune,从事独立的实验和项目。例如,我们也不知道在 Docker 上实现 Pod 的可行性如何。在网络命名空间不可配置的情况下,多个容器如何共享 IP 地址并不明显。也没有一种直接的方法来嵌套 cgroup。我们还探讨了是否可以调整现有组件,例如 Omlet 节点代理和 lmctfy 容器运行时,我们决定不这样做。
我们中的一些人去与 Docker 的 Solomon Hykes 和 Ben Golub 讨论在 Kubernetes 中嵌入 Docker 以及我们发现的一些挑战。那次会议导致与 Docker 开始了 libcontainer 协作,以取代堆栈中的 LXC。Libcontainer 和 cadvisor(与 Kubernetes 同时发布)由 Victor Marmol、Rohit Jnagal 和 Vish Kannan 开发。

Libcontainer 在 Docker 中的位置
Tim 还开发了 Python container-agent,该代理于 2014 年 5 月发布,当时我们仍未获得开源 Kubernetes 的批准。此项目中的容器清单被逐字提升到最初的 v1beta1 Kubernetes 任务 API 中,这也是 Kubernetes 中“清单(manifest)”一词的来源。

其他人员(如 Ville Aikas 和 Daniel Smith)负责 Go 代码。唯一的 API 适用于任务(后来重命名为 Pod)、副本控制器和服务。没有节点。我最初使用 RAML 手动记录了 API。
以下是 Ville 设计文档中的图表。请注意,没有 Kubelet,Kube-proxy 直接从 Etcd 读取。在我们发布 Kubernetes 之前,添加了一个最小的 Kubelet。Kubelet 也直接从 Etcd 读取,并且 apiserver 同步调用 Kubelet 以检索任务状态。

早期设计
我们希望在 Dockercon 上发布,因此我们发布了我们拥有的内容(日期很有帮助),然后公开迭代。关键思想就在那里:API、期望状态、多容器实例、标签、控制器、调度/放置、服务发现。进行了一些清理,并且代码 已复制到新存储库。它从中复制的存储库仍然存在,但原始的 code.google.com 存储库及其提交历史记录已丢失,正如 Ville 在其演示中提到的那样。
我们发布的内容没有连贯的控制平面,有一个不完整、不一致的 API,有一个极其最小的 cloudcfgCLI,并且缺少用户需要的一些基本功能,因此在开源 Kubernetes 之后的 6-7 个月用于充实这些领域,以及纳入 Redhat 和社区中其他人的想法。
为了巩固控制平面,我们在 apiserver 中实施了 Watch。这使我们能够消除 Kubelet 和 Kube-proxy 中的直接 Etcd 访问。我们还消除了 调度程序 中的直接 Etcd 访问。
为了消除 apiserver 调用 Kubelet(节点、pod)或其他组件(副本控制器)以检索状态信息的需求,我们实施了 /status API 端点。
我们还将控制器管理器和调度程序组件从 apiserver 中分离出来,并 保护组件间通信(例如,Kubelet->apiserver)。
API本身经历了许多的改动。Task 被重命名为 Pod。新增了一个 Minion API 并之后重命名为Node。调度器改为了记录 Pod 字段的节点分配方法。Service API 进行了一次大修,做出了多项改动,包括对多个端口的支持。我将 go-restful 整合进了这个 api 服务器中,以生成这个 API 的 Swagger 文档,因为人工的方式已经无法跟上这些改变的步伐了。API 版本转换以及一个内部表示也被添加了进来以支持 API 的版本化。
Clayton Coleman 主导了整个 API 界面的全面检修。我们现在所熟知的 Kubernetes API 正是在此处形成的,它将元数据、期望状态(规范)和观测状态(状态)分离开来。加入了注释。将命名空间插入资源路径中。提升了不同资源类型和字段的一致性,我还撰写了 API 约定的初稿。我们的工作非常彻底,以至于 v1 API 很少包含不能向后兼容的更改。

命令行工具在我们开源 Kubernetes 时 称为 cloudcfg。我们很快将其重命名为 kubecfg,但它没有很好地构建以进行扩展。幸运的是,Sam Ghods 自愿重写 CLI,该 CLI 成为 kubectl。这是 spf13/cobra CLI 框架集成并且动词-名词模式得到巩固的时候。
我们还创建了 kubeconfig,派生出了一个 客户端库,在多个文件和资源类型中实现了 批量操作,并为声明性操作奠定了基础。
我们添加的功能有多个目标。添加了一些功能以使系统更易于使用,例如 容器终止原因报告 和 通过 apiserver 获取日志 的能力。有些是为了安全性,例如用户身份验证、服务帐户、ABAC 授权和命名空间。其他是为了充实模型,例如服务 IP 和 DNS 以及 PersistentVolume 和 PersistentVolumeClaim。还有一些是为了展示当时在拥挤的空间中思想领导力,例如 存活探测 和 就绪探测。
2015 年初,我们开始讨论为 Kubernetes 和更广泛的云原生生态系统创建一个基金会的想法。我们决定将 1.0 里程碑与 7 月的发布活动日期保持一致。目标是让系统准备好投入生产。
现在我们有了截止日期,我们必须决定 包含哪些功能,哪些功能要推出。我们制定了该项目的第一个代码冻结。我们甚至删除了一些不完整的代码。我们包含了我们认为对实际使用很重要的功能,例如 优雅终止 和 查看失败容器的日志 的能力。我们通过 清理死容器、重新启动不健康组件 和 事件重复数据删除 等更改来强化系统以进行持续操作。
许多重要功能被推迟到 1.0 之后:kubectl apply、Deployment、DaemonSet、StatefulSet、Job、CronJob,ConfigMap、HorizontalPodAutoscaler、节点端口和 Ingress、kube-proxy 的 iptables、通过 apiserver 公开的资源指标、容器 QoS、大多数调度功能、Kubernetes 仪表盘和第三方资源。这绝对是 MVP 的正确选择。
我们还修复了 P0 Bug,解决了未经身份验证的端口等安全问题,实施了升级测试,增加了更全面的 API 验证,并且使用 Prometheus 的客户端库对组件进行了检测以便进行可观测性。
在最后几个月,我们创建了 kubernetes.io 网站。我们把一些现有文档移到了那里,但我们还编写了 新的用户指南。网站在发布当天出现了一个小故障,但我们及时解决了。主页仍然包含一些我当时写的一些文本,例如“生产级容器编排”标签行,“Kubernetes 是一个用于自动部署、扩展和管理容器化应用程序的开源系统”,以及一些功能描述,尽管有些功能在 1.0 版本中仍是理想状态。
几十人齐心协力帮助实现这一里程碑,他们以各种方式提供帮助,从查找和修复文档错误到组织活动,再到宣传项目,以及许多我在这些年后可能已经忘记的事情。
此时,该项目已经投入了大量工作。距离最初发布大约一年,但从开始算起已经超过一年半,并且在此之前还有多年的研发。这项工作对其成功起到了作用。