2024 年 Python 包管理生态系统概述。
译者目前使用 poetry,经历过 pipenv 等工具后,现在觉得 poetry 很棒。译自 Python has too many package managers,作者 Larry Du。
Python 是一种很棒的编程语言。我用它来构建网络应用程序、深度学习模型、游戏和数值计算。然而,Python 的一个方面多年来一直是令人难以忍受的痛苦。那就是碎片化的 Python 包和环境管理生态系统,可以用以下 XKCD 漫画简洁地表示:
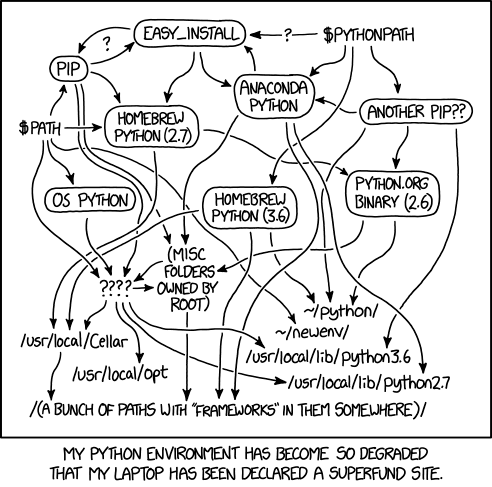
你看,许多其他编程语言都开发了标准化的方法来设置版本控制、依赖关系解析和开发环境设置。C# 有 NuGet,Javascript 有 npm,Dart 有 pub,最值得注意的是 Rust 有 Cargo——这可能是现存最受欢迎的包管理器工具。
在一个理性的世界里,包管理应该像 Cargo——rust 包管理器那样工作。你有一个单一的 TOML 主配置文件,你只需在其中列出你的依赖项和配置设置。TOML 文件进入一个封装整个开发环境的文件夹。为了提高可重复性,每当你构建环境并解析所有包依赖项时,一个 *.lock 文件会记录你使用的所有包及其版本和哈希值。
最后,由于依赖关系解析是一个有向无环图 (DAG) 解析问题,因此依赖关系检索和解析都应该被设计成相对快速。依赖关系信息应该从公共 API 元数据服务器以易于解析的方式自由获取,并在下载后缓存在本地,以避免重复访问该服务器。最后,依赖关系解析算法本身应该用相对快速的编程语言(如 C++ 或 Rust)编写。
Python 的问题是,还没有一个工具能很好地做到 所有这些,尽管有些工具已经非常接近了。为此,以下是我对十多个 Python 包管理/虚拟环境工具的概述:
pip 和 venv
是 Python 包管理器的鼻祖。依赖关系解析?pip 直到最近才几乎没有进行任何依赖关系解析。从历史上看,它会一个接一个地安装包,无论是否发生冲突。在 2020 年发布的 20.3 版本中,pip 终于添加了依赖关系解析回溯功能,这意味着如果检测到不一致的状态,它会回溯并尝试解决问题。与本列表中的许多其他工具不同,以及与 Rust 和 C# 中的 Cargo 或 NuGet 等工具不同,pip 不与依赖项一起管理环境。需要使用 venv 或 virtualenv 等单独的工具来创建“虚拟环境”,而这些环境又与特定项目或项目目录完全分离。
pip 的一个主要缺陷是,当你决定删除一个依赖项时会发生什么。删除依赖项实际上不会删除由原始依赖项引入的子依赖项,从而留下许多潜在的垃圾。这实际上需要手动完成,或者使用 pip-autoremove 等另一个工具来删除不再有用的子依赖项。
pyenv
pyenv 关于 python 的 venv 工具需要注意的一点是,它实际上并没有为 不同版本的 Python 创建虚拟环境。要真正做到这一点,还需要另一个名为 pyenv 的工具,它允许你随意在不同版本的系统 Python 之间切换,并可以选择为特定项目在本地设置 Python。我经常看到这个工具被滥用来全局设置 Python 版本,这会导致一些严重的重复性问题,因为人们会忘记他们为不同的项目使用了哪个版本的 Python。
pipenv
因此,pip 和 venv 的组合可以让你构建“虚拟环境”,而 pyenv 可以让你切换 Python 版本。自然而然地,应该有一个工具允许你在一个文件中指定 python 版本和依赖项。pipenv 基本上设置了这一点,可以选择与 pyenv 进行互操作,让用户在 Pipfile 中指定 python 版本和依赖项,并在 Pipfile.lock 中锁定依赖项。
pipenv 的缺点是,它的依赖关系解析并不比它使用的 pip 好。此外,在 2020 年,一个新的“Python 增强提案” PEP 621 被接受,定义了未来 Python 项目如何合并包元数据,从而使 Pipfile 和 Pipfile.lock 从长远来看不再完全是“惯用的”……
在 PEP-621 之前,给定 Python 项目中可能存在大量配置文件:
-
requirements.txt:项目的依赖项,可能包含也可能不包含包哈希值(出于安全原因),具体取决于其设置方式。 -
setup.py和setup.cfg: 一個腳本和一個配置文件,共同定義依賴關係和選項。 -
MANIFEST.in: 告诉打包软件(如 setuptools)在包中包含哪些非代码文件。 -
tox.ini:Tox 工具使用此文件配置环境设置、依赖项和测试命令(你现在看到冗余了吗?) -
Pipfile和Pipfile.lock: 适应于使用pipenv的人。 -
.pylintrc: 用於為像black和isort這樣的 linting 工具設置配置。 -
environment.yml: conda专门用来定义依赖项,其中一些根本不是python包。有趣的是,你可以分别指定pip依赖包和conda依赖包,即使pip包在conda频道上有对应的(可能经过精心整理)版本! -
.condarc: Conda 的配置文件。
所有这些工具和标准的扩散自然会导致大量的冗余。实际上没有标准的方法来列举给定包的依赖项,也没有如何设置诸如linters和测试之类的工具的标准方法。

2020 年已接受 PEP 621。此提案切实地提供了将所有内容整合到 pyproject.toml 文件中的指南,这与 Rust 中的 Cargo.toml 几乎完全相同,并且与 npm 中所用 package.json 相似。这自然孕育出了众多 Python 包管理器,这些管理器利用了新标准。输入诗,PDM,Flit 和 Hatch。
当前,Poetry 是 Python 生态系统中最接近于 Cargo 和 npm 等工具使用体验的大规模使用工具。Poetry 不同于 pip,类似于 conda 和 mamba(见下文),它会事先尝试解决完整的依赖关系图 DAG,并按拓扑顺序安装依赖项。它主要遵循 pyproject.toml 并将其作为一级公民对待。像 conda 和 venv 一样,poetry 也可以管理虚拟环境,该环境可以存在于项目文件夹内或外部。poetry 还会生成 poetry.lock 文件,这对于可复制性来说非常有用。值得注意的是,这些锁文件是多平台锁文件,这意味着它们可能非常大。最后,poetry 也是一个构建工具,允许用户无缝构建和发布 Python 包。
尽管如此,poetry 几乎是这项工作的完美工具,但它也有许多缺点,对于制作甚至基础的研究和开发来说,这些缺点可能完全是交易破坏因素。首先,依赖项解析可能非常缓慢。很大一部分原因不在于 poetry 本身,而是因为 Python 包枚举其依赖项的不同方式。与其他编程生态系统不同,并非所有 Python 包都以公共元数据 API(如 PyPI)可以简洁地提供的形式声明其元数据。在这些情况下,为 DAG 中的每个可能的包浏览每个依赖项可能涉及大量的操作,以通过下载和解析 Python 轮子直接找出软件包依赖项。对于一些做基础研发的人来说,仅仅让几个包排除在依赖关系解析之外的成本可能比等待几分钟到几小时来找到“依赖关系解析失败”更公平的权衡。
此外,截至 2024 年,Poetry中的依赖关系解析器实际上仍以深度优先搜索算法的形式用 Python 编写。相比之下,诸如 mamba 之类的工具有以布尔 SAT 求解器形式用 C++ 编写的求解器,速度快几个数量级!Poetry中大型项目的依赖关系解析,加上多平台锁定文件的生成可能需要相当长的时间……特别是在 DAG 中有实际冲突时。
我实际上在上一次的工作中使用了 poetry,这个工具的一个最大问题在于大多数人(甚至是经验极其丰富的人!)错误地使用它来指定广泛共享的库代码的依赖边界的。在 poetry 中可以选择使用脱字符 ^ 运算符来隐式地指定上下界。比如,指定 ^0.2.3 等价于指定 >=0.2.3,<0.3.0。这个上限固定在表面上看起来是个好主意,但是当应用于一个拥有众多“假阳性”和不可解决的依赖有向无环图的庞大研发组织时,就会造成灾难性的后果,特别是好心的软件工程师过于随心地应用它时。对于那些打算广泛使用的库来说,这种善意的上限固定可能会产生毁灭性的后果。
pdm
pdm 与 Poetry 极其相似,但其核心区别在于它还支持 PEP-582。此 PEP 基本上使 pdm 与其他编程语言环境设置保持一致,它抛弃了独立于给定的项目/文件夹的虚拟环境的概念。当你位于自己的项目目录中时,事实上你就处于自己的虚拟环境中(它不一定是与系统环境和任何其他活动的虚拟环境完全隔离的)。这可以极大减少在 Python 中激活和停用各种虚拟环境工具时进行琐碎操作的情况。此外,pdm 比 Poetry 更符合 PEP 标准,这可能是某些用户的杀手锏优势。
与该列表上的其他工具不同,hatch 是一个完全支持 pyproject.toml 的 python 构建系统。我还没有真正尝试这个工具,但在很多方面它与 poetry 都有重叠,并且它还具有一个我尚未在任何其他 Python 工具中看到过的特定特性。你实际上可以使用 hatch 在多个版本的 Python 上并行运行测试。
在不谈论 Conda 的情况下,不可能深入探讨关于 Python 工具的文章。conda 由 Python 开源社区中最杰出的成员之一创建 - Travis Oliphant(Numpy、Numba 和 SciPy 的创建者之一)和 Peter Wang,他是 Bokeh 的开发者。
conda 在很多方面,conda 和 anaconda 解决了数据科学工作中 Python 环境设置的大多数核心问题。conda 实际上可以在其自己的 conda 虚拟环境中管理非 Python 依赖项以及 Python 包。这为科学家提供了一种相当符合人体工程学的方式来交换非 Python 依赖项,而无需诉诸使用 Docker(使用 Docker 的摩擦力要大得多)。这是我在工作之外使用的工具,它非常适合实验。
与 poetry 类似,conda 在构建环境时执行完整的依赖项解析,但与 poetry 不同的是,近年来,conda 依赖项解析器已被 替换为用 C++ 编写的更快的解析器,称为 libmamba。此外,与 poetry 不同,当上游包维护者提供的元数据不足时,无需尝试直接解析 Python 包。这是因为 conda 拥有完全独立的元数据 API 服务器,这些服务器强制包上传者维护更严格的依赖项声明标准。
conda 的核心权衡是它试图通过强制存在一个单独的 environment.yml 来以“正确”的方式进行包元数据,该文件正确声明了依赖项和其他元数据。实际上,正是这些信息由 conda 的独立元数据 API 服务器提供。这对于已经拥有许多内部 Python 包的公司来说可能难以适应。如果存在一些鲜为人知的 Python 包没有这个文件,那么您将无法使用 conda 干净地安装它。但是,pip 可以在 conda 环境中安装,从而导致可能令人尴尬地依赖于两个包管理器的混合使用。关于 conda 的另一件事是,它既不生成开箱即用的锁定文件,也不支持 pyproject.toml 配置文件。
在 2024 年,conda 并不是理想的人体工程学。用户仍然必须使用 conda 虚拟环境,这些环境与特定项目文件夹分离。项目的依赖项和配置可能难以在 conda environment.yml 文件、pip 安装和其他配置文件中跟踪。发布包既不特别简单也不容易。
我还看到一些组织避免在生产部署中使用 conda,因为 conda 倾向于安装大量垃圾,因为它也管理非 Python 依赖项。此类组织将倾向于使用 Docker 和 *.lock 样式文件来枚举依赖项。
话虽如此,conda 可能是目前数据科学家和实验人员最好的工具。它被 Python 生态系统中广泛使用的许多第三方工具(如 Ray 和 Metaflow)视为一等公民。
mamba 实际上有 conda 的多个实现。mamba 基本上是用 C++ 重新编写了 conda,使其速度大大提高。然而,conda 中最慢的部分实际上是求解器,截至 2024 年,libmamba 求解器已从 mamba 项目移植到 conda。
在 2024 年,mamba 团队的成员转向了 pixi 的工作 - 一个完全用 Rust 编写的 mamba 和 conda 的替代品(见下文)。
Python 包管理领域的一些最具前景的发展来自 Rust 社区。毫无疑问,Rustaceans 对包管理器设置的运作方式有一个清晰的例子,即 Cargo,因此在过去两年中出现了几个有希望的解决方案,其中最值得注意的是 uv。
为了说明多个团队都试图为 Python 创建一个“Cargo”,我想简要提一下 huak。该工具在本文撰写之时完全处于实验阶段,尚未得到广泛使用,但试图将 Cargo 的人体工程学移植到 Python 包管理器中。
最雄心勃勃的 Rust 项目之一是 pixi,它旨在成为 conda 的直接替代品。与 conda 一样,pixi 可以管理非 Python 依赖项。在 2024 年年中,pixi 开始从其自己的后端 rip 切换到 uv(见下文)以获得更好的性能。这是一个积极发展的工具,我迫不及待地想看看它将走向何方。与 conda 和 mamba 不同,pixi 结合了自己的 *.lock 文件 类型,这使其立即领先于普通 conda,从而提高了可重复性。
Armin Ronacher 最早尝试用 Rust 重做 Python 包管理的尝试之一。当我一年前第一次看到它时,实际的慢速部分(依赖项解析)只是在幕后调用 piptools,导致速度或性能没有明显提升。
然而,随着时间的推移,该项目已经成熟到可以完成 poetry 的大部分甚至全部功能,而且速度更快。该项目最近被 Astral.sh(uv 和 ruff linter 的开发者)接管,现在使用与 uv 相同的后端依赖项解析器。该工具在一些主要项目中也获得了相当大的关注。例如,OpenAI Python API 库使用它。rye 的功能最终可能会被 uv 独自完全复制,从而导致这两个项目合并。
到目前为止,是 Python 生态系统中最有希望的包管理工具。该项目实际上旨在成为 pip 的直接替代品,同时也是 Python 的 Cargo。该 API 目前(截至 2024 年)尚不稳定,但基准测试非常有希望。最值得注意的是,该开发得到了 Astral.sh 的支持,Astral.sh 是一家由 Charlie Marsh 和 ruff linter 的创建者组成的公司,这是一款广受好评的工具,在 2022 年发布时几乎在一夜之间取代了所有现有工具。
与 poetry 一样,该项目支持 pyproject.toml,与 pip 一样,它使用回溯方法进行依赖项解析。与 pip 不同的是,该算法是用 Rust 编写的,速度非常快!基准测试表明,uv 在 依赖项解析方面 至少比 poetry 快一个数量级。我完全相信 uv 在未来会取代像 poetry 这样的工具,因为该项目会成熟并稳定 API,但是截至本文撰写之时,它更像是各种 pip 工具的直接替代品,而不是像 poetry 或 rye 这样的有见地的构建/打包/版本控制工具。
uv 性能和采用率的一个有希望的迹象是,其他包管理器(如 pixi 和 rye)使用其库。
希望有一天,Python 包管理能够像 Javascript 和 Rust 开发生态系统那样简单易用。在此之前,我建议大多数数据科学/实验人员继续使用 conda,而面向生产的人员使用 pip 或 poetry(对于使用 poetry 的复杂项目,要对缓慢的依赖项解析有所了解)。
不过,我希望能看到 uv 腾飞,Python 社区有一天能够围绕一个标准化的工具团结起来!而且有一些有希望的迹象表明,像 pixi 这样的工具可以改进 conda 及其更广泛的依赖项管理。