vGPU、MIG 和 时间切片技术优化 AI 和 ML 的 GPU 使用。了解这些方法如何降低 GPU 成本并提高项目可扩展性。
译自 Guide to GPU Sharing Techniques: vGPU, MIG and Time Slicing,作者 Sameer Kulkarni。
优化 GPU 利用率在现代计算中至关重要,尤其是在 AI 和 ML 处理方面,GPU 在这些领域发挥着关键作用,因为它们具有无与伦比的并行计算能力,可以快速处理大型数据集。现代 GPU 在这些领域非常宝贵。它们拥有 数千个内核,可以实现非常高的并行性。这使得复杂模型训练和实时数据分析成为可能,而这些在传统 CPU 上是不切实际的。
通过充分利用 GPU 资源,组织可以加速 MLOps 工作流程,获得更快的洞察力,并提高其计算基础设施的效率。这可以通过减少对额外硬件和运营费用的需求来节省大量成本,同时还能提高可扩展性和灵活性,以满足当代计算任务的动态需求。优化 GPU 利用率的一种关键方法是通过在不同的工作负载之间共享 GPU。这就是虚拟 GPU (vGPU)、多实例 GPU (MIG) 和 GPU 时间切片发挥作用的地方!
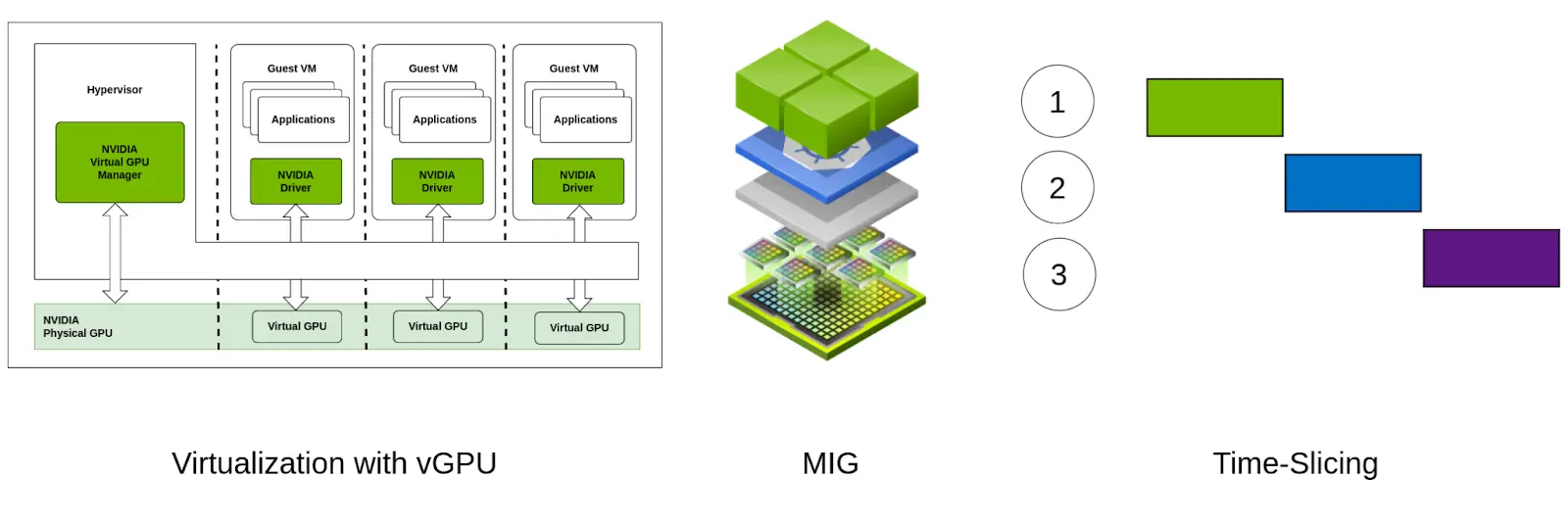
vGPU、MIG 和 GPU 时间切片都旨在通过允许多个任务或用户共享单个物理 GPU 来优化 GPU 资源的利用率。不过,它们在工作方式、硬件要求和用例方面存在一些差异。在本博文中,我们将阐明这些差异,并帮助您做出最佳选择,以实现更好的 GPU 优化。
vGPU 或虚拟 GPU 是一种技术,允许将物理 GPU 在多个虚拟机 (VM) 之间共享。每个 VM 都获得 GPU 资源的专用部分,使多个用户或应用程序能够同时访问 GPU 加速。这种虚拟化技术对于需要高性能图形或计算能力以实现一致且可预测的性能的每个 VM 的环境至关重要。
vGPU 在需要在虚拟机上提供 GPU 的情况下非常有用。一些具体的例子包括虚拟桌面基础设施 (VDI)、云游戏和远程工作站场景。
对于 AI/ML 处理,vGPU 对于在容器化环境中运行工作负载非常重要。
- vGPU 允许每个 VM 拥有 GPU 资源的专用部分。这确保了每个 VM 的一致且可预测的性能。
- 由于资源是静态分配的,因此在一个 VM 中运行的工作负载不会干扰另一个 VM 中的工作负载,从而防止由于资源争用而导致的性能下降。
- 每个 vGPU 实例都在其自己的 VM 中运行,提供了强大的安全边界。这种隔离对于多租户环境至关重要,在这些环境中,数据隐私和安全性至关重要,并且在高度监管的行业中通常是强制性的。
- 一个 vGPU 实例中的错误或故障将被限制在该实例内,防止它们影响共享同一个物理 GPU 的其他 VM。
- 虽然最大分区数量取决于 GPU 实例模型和 vGPU 管理器软件,但 vGPU 支持创建 每个 GPU 最多 20 个分区,使用 A100 80GB GPU 和 NVIDIA 虚拟计算服务器 (vCS)。
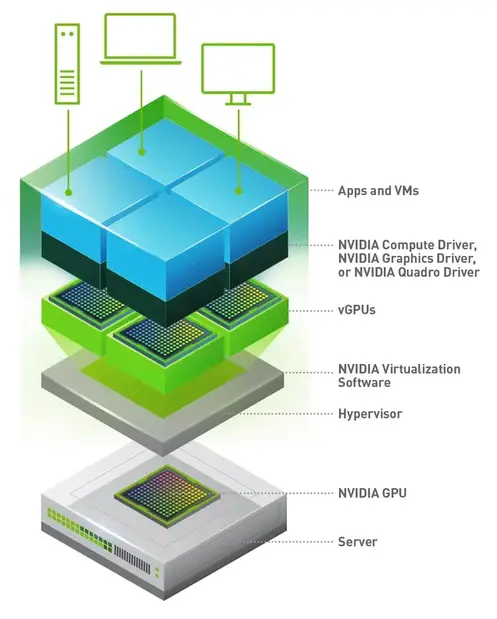
vGPU 通过创建可以分配给单个 VM 的 GPU 硬件虚拟实例来工作。该过程通常涉及以下部分。
GPU 虚拟化是抽象物理 GPU 硬件以创建多个虚拟 GPU (vGPU) 的过程,这些 vGPU 可以分配给不同的虚拟机 (VM) 或容器。GPU 抽象是通过结合软件组件实现和管理的,包括管理程序和专门的 GPU 驱动程序。
管理程序,例如 VMware vSphere、Citrix XenServer 或 KVM(基于内核的虚拟机),管理 vGPU 的分配和调度。管理程序包括一个 GPU 管理层,它与物理 GPU 交互并控制 GPU 资源到 VM 的分配。
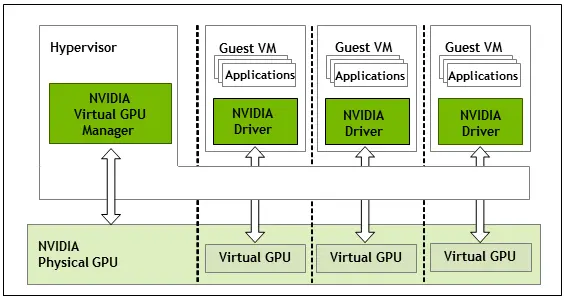
NVIDIA vGPU 的 vGPU 架构
以下是启用主机上 vGPU 所涉及的关键组件。
- 主机驱动程序: 此驱动程序运行在 hypervisor 或主机操作系统上,并管理物理 GPU,将其资源划分为虚拟实例。
- 客户机驱动程序: 安装在每个 VM 中,此驱动程序与主机驱动程序通信以访问分配的 vGPU 资源。
- vGPU 管理器: 由 GPU 供应商(例如 NVIDIA)提供的软件组件,用于创建和管理 vGPU。
注意: 在某些情况下,您可能不需要主机驱动程序和 GPU 管理器同时存在。其中一个可能就足够了。请参阅制造商文档以获取具体指南。
每个 VM 根据预定义的配置文件分配 GPU 资源的一部分。这些配置文件确定每个 VM 获取多少 GPU 内存和计算能力,确保公平分配和最佳利用。
要启用和使用 vGPU,您确实需要与虚拟化兼容的特定 GPU,尽管大多数现代 GPU 都与虚拟化兼容。NVIDIA 提供了几款支持 vGPU 的 GPU,主要来自其 Tesla、Quadro 和 A100 系列。AMD Firepro S-Series 也支持使用 SR-IOV 的虚拟化。
Multi-Instance GPU (MIG) 是 NVIDIA 在 2020 年 5 月推出的一项技术。它允许将单个物理 GPU 在硬件级别划分为多个隔离的 GPU 实例。每个实例独立运行,拥有自己的专用计算、内存和带宽资源。这使多个用户或应用程序能够共享单个 GPU,同时保持性能隔离和安全性。
由于 MIG 允许在硬件级别对 GPU 进行分区,因此它可以实现更好的性能,更低的开销和更高的安全性。
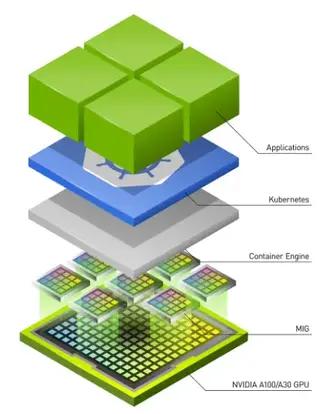
多实例 GPU 通常用于 GPU 密集型应用程序,例如 HPC 工作负载、超参数调整等。它也用于 AI 模型训练和推理服务器,这些服务器需要高性能和进程之间更高的安全性。
- MIG 确保 GPU 资源得到充分利用,减少空闲时间并提高整体效率。
- MIG 将 GPU 静态分区为多个隔离的实例,每个实例都有自己的专用资源部分,包括流式多处理器 (SM);确保更好且可预测的流式多处理器 (SM) 服务质量 (QoS)。
- 专用部分内存 在多个隔离的实例中确保更好的内存 QoS。
- 静态分区还提供错误隔离,从而实现故障隔离和系统稳定性。
- 更好的数据保护和恶意活动的隔离,为多租户设置提供更好的安全性。

NVIDIA MIG 在硬件级别实现 GPU 共享。GPU 芯片资源(如 CUDA 内核和内存)在硬件级别被划分为更小的隔离实例。

MIG 技术通过内置于 GPU 的多个架构功能的组合来实现。以下是一些重要的功能:
- SM 分区: SM(流式多处理器) 是 GPU 的核心计算单元。GPU 架构允许根据所选配置将特定数量的 SM 分配给每个 MIG 实例。
- 内存分区: GPU 的内存被划分为通道。该架构允许将每个通道分配给不同的实例。这使每个 MIG 实例能够独占访问自己的内存。
- 高速互连: GPU 内部的内部高速互连被分区,以确保每个实例都能访问其公平的带宽份额。
MIG 利用 NVIDIA A100 GPU 的架构,该架构设计为可拆分为最多七个独立的 GPU 实例。每个实例称为“MIG 切片” ,可以配置不同数量的 GPU 资源,例如内存和计算核心。
每个 MIG 切片独立于其他切片运行,并具有硬件强制隔离。这确保在一个实例上运行的工作负载不会干扰另一个实例上的工作负载,从而提供安全且可预测的性能环境。隔离还防止实例之间发生任何潜在的安全漏洞或数据泄露。
GPU 的资源通过固件和软件的组合划分为实例。管理员可以根据工作负载的特定需求创建和管理这些实例。例如,大型训练作业可能需要更大的切片,具有更多内存和计算能力,而较小的推理任务可以使用较小的切片。
多实例 GPU 是一项新技术,仅受少数 GPU 系列型号支持。它与 NVIDIA A100 系列一起推出,截至 2024 年 6 月,目前仅受 NVIDIA Ampere、Blackwell 和 Hopper 一代 GPU 支持 (来源)。这些代的一些示例型号分别是 A100、B100/200 和 H100/200 GPU。
GPU 时间切片是一种虚拟化技术,允许多个工作负载或虚拟机 (VM) 通过将处理时间划分为离散切片来共享单个 GPU。每个切片按顺序将 GPU 的计算和内存资源的一部分分配给不同的任务或用户。这使得能够在单个 GPU 上并发执行多个任务,最大限度地提高资源利用率并确保公平地将 GPU 时间分配给每个工作负载。
GPU 时间切片适用于需要在有限硬件上执行大量作业的所有工作负载。它适用于不需要复杂资源管理的场景,以及可以容忍可变 GPU 访问和性能的任务。
- 最大限度地提高资源利用率并减少空闲时间,无需专门的硬件或专有软件。
- 减少对额外硬件的需求,从而降低运营成本。
- 提供灵活性,根据工作负载需求处理不同的计算需求。
- 时间切片相对易于实施和管理,使其适用于不需要复杂资源管理的环境。
- 此方法对于可以容忍 GPU 访问和性能变化的非关键任务有效,例如后台处理或批处理作业。
- 可用最大分区数量不受限制。
- 工作负载之间频繁的上下文切换会导致性能开销并增加任务执行的延迟,从而降低 GPU 利用率的整体效率。
- GPU 可能无法有效地处理具有高度可变资源需求的工作负载,因为固定时间切片可能与所有任务的计算需求不一致。
- 性能可能不一致,因为不同的工作负载可能具有不同的计算和内存需求,从而导致潜在的资源争用。
- 用户对分配给每个工作负载的 GPU 资源的确切数量控制有限,因此难以保证特定任务的性能。
如上所述,GPU 时间切片根据定义的配置文件将 GPU 资源分配给每个时间切片的不同进程。以下是使用时间切片调度和执行 GPU 任务的主要步骤。

{kind=link}
GPU 调度程序管理 GPU 资源在不同任务之间的分配。它将 GPU 的时间切片成间隔,并根据预定义的策略将这些时间段分配给各种工作负载或 VM。每个时间切片代表一个固定持续时间,在此期间特定工作负载独占访问 GPU 资源。这些切片通常很短,允许 GPU 快速地在任务之间切换。
传入的 GPU 任务被放置在一个由调度程序管理的队列中。调度程序根据优先级、资源需求和其他策略组织这些任务。调度程序可以使用不同的策略,例如 循环调度。
当分配给任务的时间片结束时,GPU 会执行上下文切换,以保存当前任务的状态并加载下一个任务的状态。这涉及保存和恢复寄存器、内存指针和其他相关数据。GPU 确保每个任务在其分配的时间片内都能访问必要的计算和内存资源。这包括管理内存分配并确保数据正确地传输到 GPU 和从 GPU 传输。
在其分配的时间片内,任务在 GPU 上运行,利用计算核心、内存和其他资源。调度程序监控每个任务的性能,根据需要调整时间片和资源分配,以优化整体 GPU 利用率并确保公平访问。
GPU 时间切片没有特定的硬件要求。大多数现代 GPU 都支持它。
以下是三种 GPU 分区技术的鸟瞰图比较。此图表提供了快速参考,以了解它们在分区类型、SM/内存服务质量、错误隔离等不同功能方面的差异。
| 功能 | vGPU | 时间切片 | MIG |
|---|---|---|---|
| 分区类型 | 逻辑 | 逻辑 | 物理 |
| 最大分区 | 最多 20 个(使用 VCS 和 A100 80GB GPU) | 无限 | 7 |
| SM QoS | ❌ | ❌ | ✅ |
| 内存 QoS | ❌ | ❌ | ✅ |
| 错误隔离 | ✅ | ❌ | ✅ |
| 重新配置 | 动态 | 动态 | 需要重启 |
| GPU 支持 | 大多数 GPU | 大多数 GPU | A100、A30、Blackwell 和 Hopper 系列 |
在这篇博文中,我们探讨了三种 GPU 虚拟化技术:vGPU、多实例 GPU (MIG) 和 GPU 时间切片。
- vGPU(虚拟 GPU):允许单个物理 GPU 在多个虚拟机 (VM) 之间共享,每个虚拟机都有其自己的 GPU 资源专用部分。
- 多实例 GPU (MIG):将单个物理 GPU 分区成多个隔离的实例,每个实例在硬件级别都有专用的计算、内存和带宽资源。
- GPU 时间切片:将 GPU 的处理时间划分为离散的时间间隔,允许多个任务以时间复用方式共享 GPU。
现在您已经了解了 vGPU、GPU 时间切片和 MIG 之间的区别,我们很乐意听取您如何使用这些技术。想要进入生产级别并需要支持,您可以引入 AI 和 GPU 云专家 来帮助您构建自己的 AI 云。
如果您发现这篇文章有用且信息丰富,请订阅我们的每周时事通讯,以获取更多类似的文章。请在 LinkedIn 上开始关于这篇文章的对话。我很想听听您的想法。