了解 OpenTelemetry 跟踪和 Coralogix 分析如何解决延迟问题,证明可观测性在提高系统性能和可靠性方面的作用。
译自 Coralogix and OpenTelemetry on Checkly: Optimizing Latency,作者 Jan Grzesik。
编辑:在发布这篇文章后,Hacker News 上的一位用户询问我们是否可以探索相对节省而不是绝对节省。我从该线程中的回复:
根据上周的数据,我们的更改将任务时间从平均 3440 毫秒减少了 40 毫秒,并且此任务每天运行 1100 万次。这转化为大约 1% 的节省。
从这个角度来看,由于 OTEL 和 Coralogix,我们在大约一天的工作时间内识别并修复了问题。在大型系统中,微小的效率确实可以产生重大影响。
可观测性的意义何在?当然,如果您编写了良好的代码,维护它,处理技术债务并正确管理其资源,它将运行良好?为什么您需要密切关注已经过测试并且运行良好的服务?在本文中,我想展示如何使用 Checkly 和 Coralogix 等工具对系统进行持续监控,可以发现无法预测或预先优化的问题。更一般地说,我们将看到可观测性识别出的微小修复如何产生重大影响。
我们使用 OpenTelemetry 监控我们的 Node 服务并将数据发送到 Coralogix 仪表板,并通过一些挖掘发现了一个问题,该问题导致我们所有任务在一个多月的时间里都存在延迟。这是一个时间投入少,收益大的胜利,也是对可观测性工具的有力论据。
我们的故事始于一个谜团:一个比预期花费更长时间的进程。涉及的进程是“清理时间:”Checkly 服务在检查完成后花费的时间。在此期间,我们将跟踪写入我们的数据存储,发送带有状态的事件等。所有需要发生的事情,以便 Checkly 服务显示来自检查的数据,并在出现问题时通知用户。
我们决定使用 OpenTelemetry 来识别我们后端代码中问题的根源。Coralogix 支持 OpenTelemetry 从我们的应用程序获取遥测数据(跟踪、日志和 指标),因为请求通过其众多服务和基础设施。
OpenTelemetry 项目包含多个处于不同成熟度级别的语言项目,但所有列在主要语言项目页面上的项目都由生产中的大型团队使用。我们最初对开箱即用的 Node OpenTelemetry 项目的体验是跟踪 非常 嘈杂。
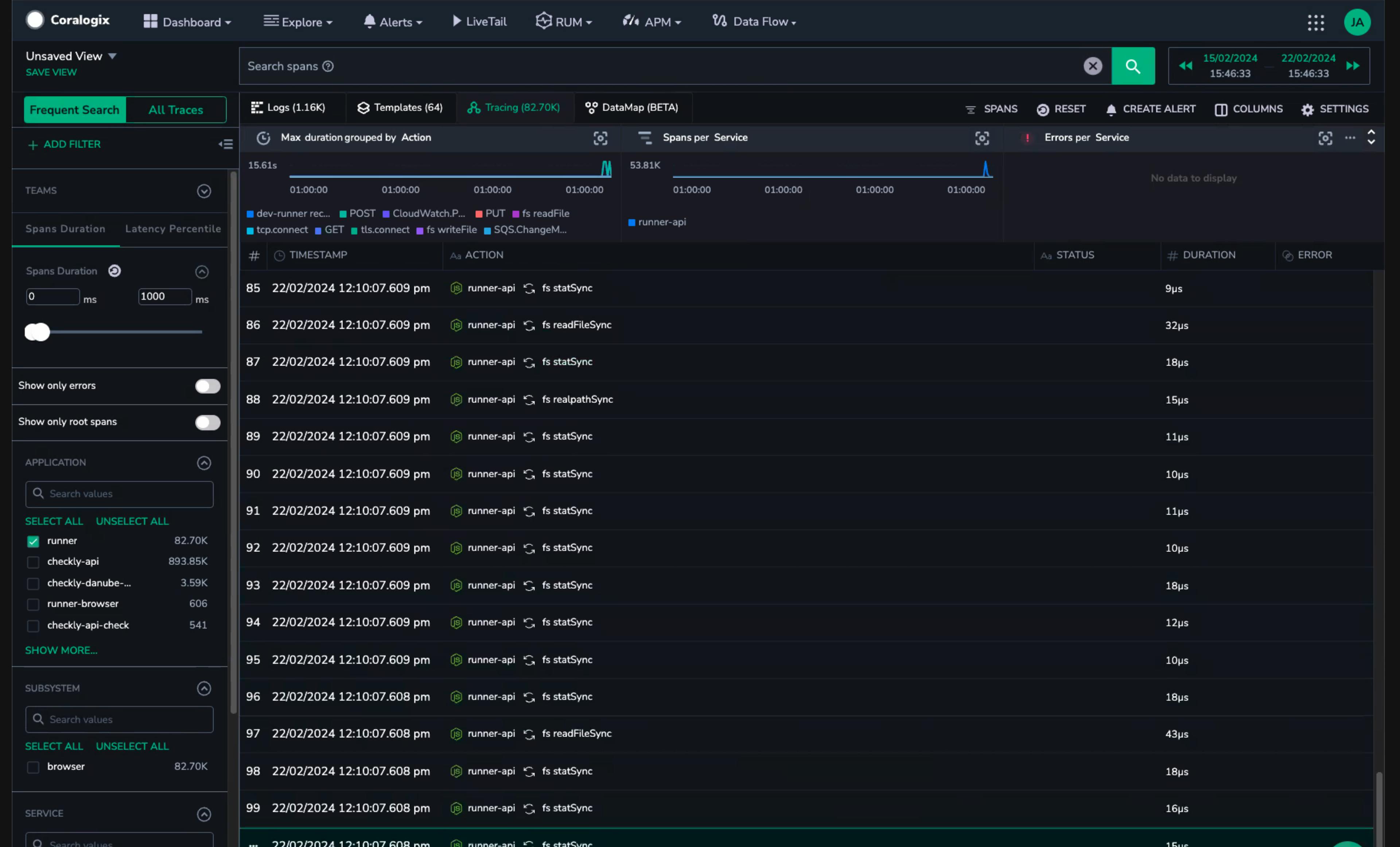
我们早期跟踪之一,其中包含许多微秒级的时间跨度
在 CNCF Slack 上咨询了一些聪明人后,我们发现 Node OpenTelemetry 仪器存在一些现有问题。很明显,问题是捕获了 NodeJS 的文件系统,每次需要模块时都会创建一个跨度。通过修改我们的配置,我们禁用了 文件系统仪器 并开始获得更有趣的跟踪数据。
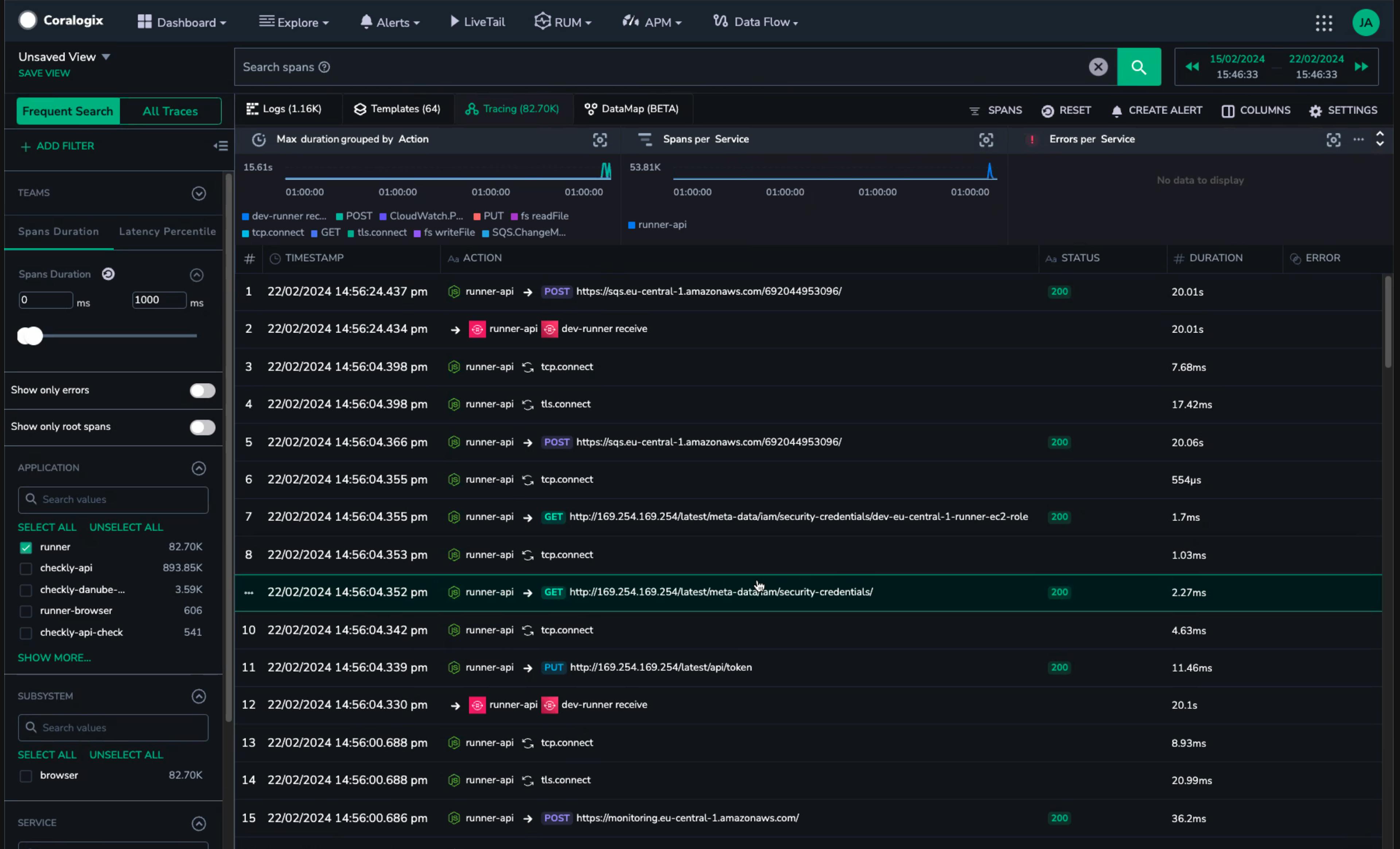
具有多种跨度类型和毫秒级测量,这是一个值得一看的跟踪。
有许多方法可以过滤您的 OpenTelemetry 数据,事实上,如果您对这个主题感兴趣,您可能想查看 Nica 最近在 KCD 纽约:“控制来自 OpenTelemetry 收集器的 Data Overhead。” 上的演讲。
可观测性做得对的一件很棒的事情是人类操作员在最高级别调查中的作用。自动扫描对很多事情都有用,但人类滚动浏览跟踪可以立即注意到看起来不对劲的事情。
值得注意的是,如果您想确保自己的检查跟踪更易于人类阅读,请考虑 在您的 Playwright 代码中添加步骤 以确保其他人可以看到检查组件的目的。
在我们的跟踪情况下,我们注意到对安全凭据的请求发生不止一次。这些请求间隔足够远,以至于它们没有显示在同一页的跨度中:
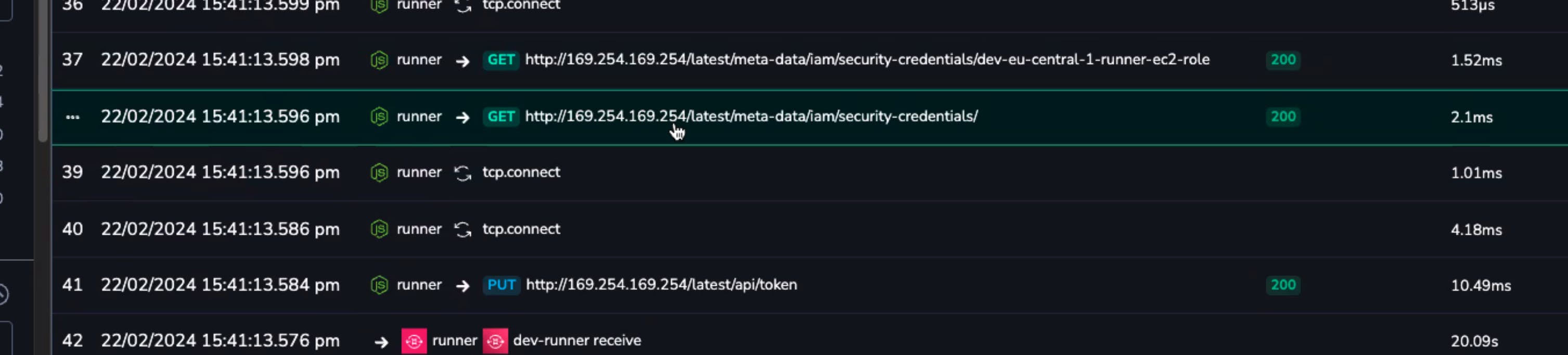
当您获取安全令牌时,一次很奇怪,两次很糟糕。
了解到问题是多个对 AWS 身份验证的请求后,我们搜索了一下,找到了 AWS SDK 中的具体问题。
令人高兴的是,Yurii Siedin 使用他自己的跟踪工具展示了问题的明确证据:
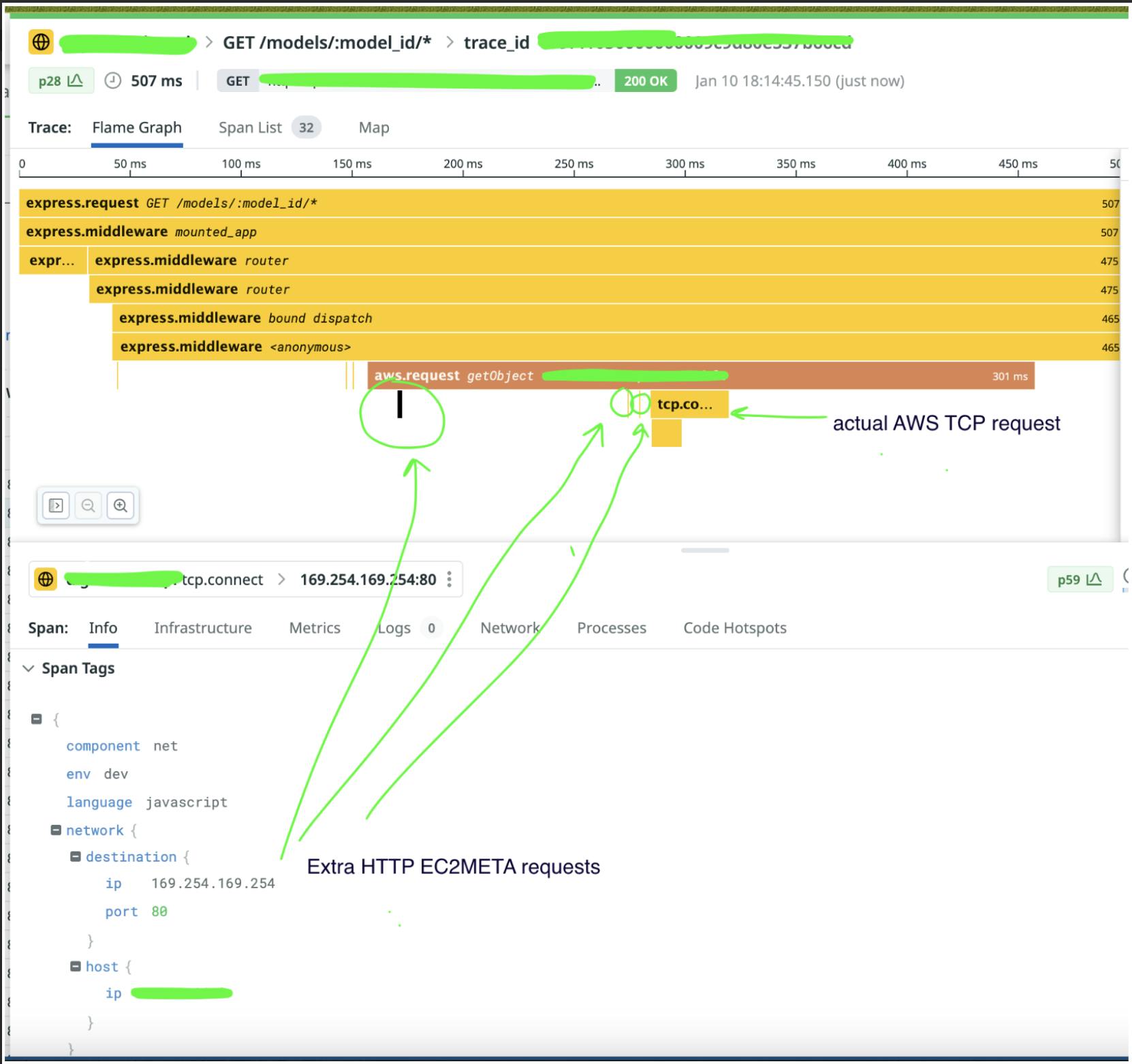
有时跟踪只是展示问题最简单的方法。 通过在 GitHub 问题中推荐的修复方法,将我们身份验证调用的结果保存在本地,避免重复请求,问题从我们的跟踪中消失了。
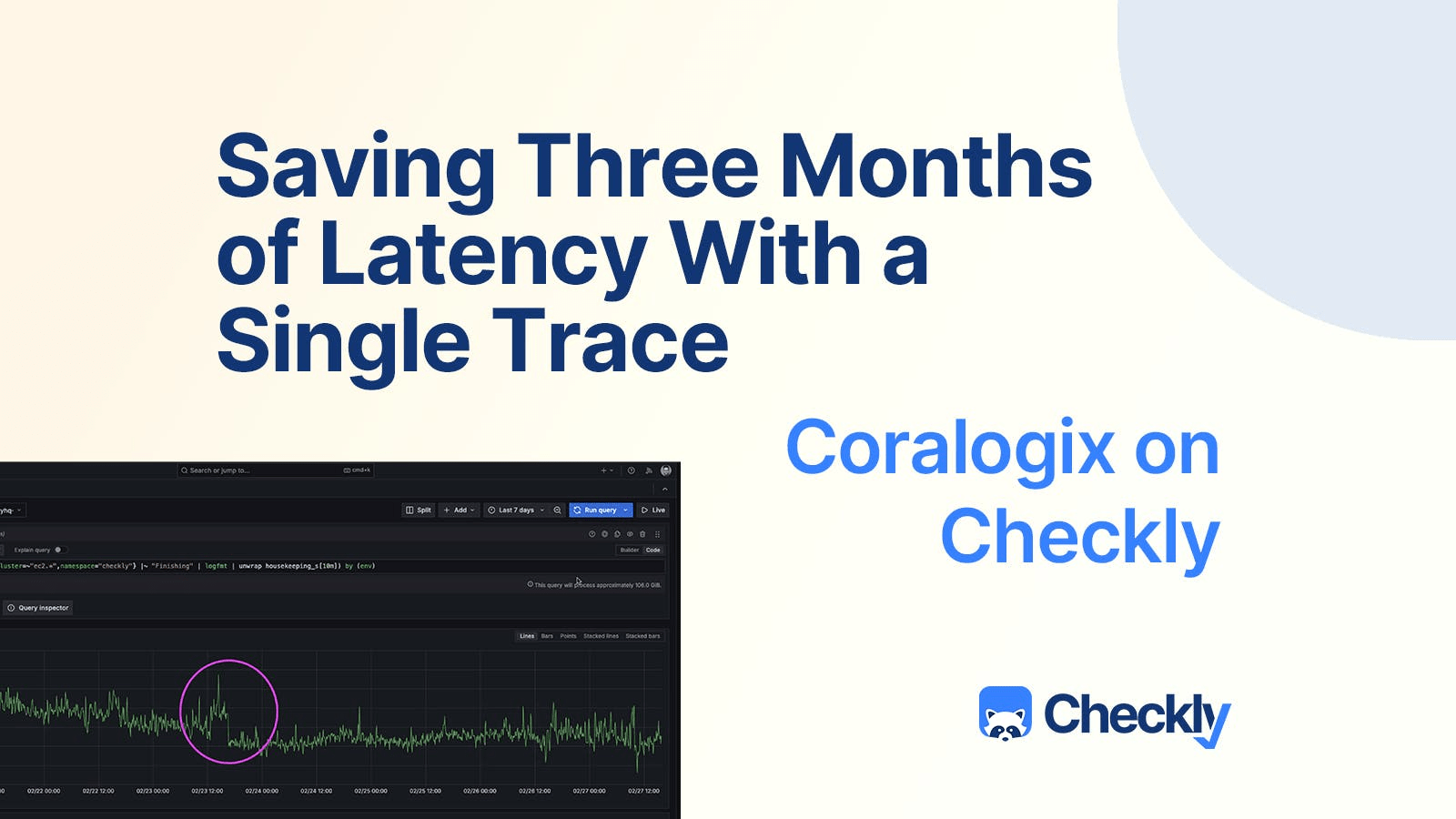
一个小小的改进可以带来巨大的改变。在本例中,我们修复的合并导致了维护任务时间的显著下降。
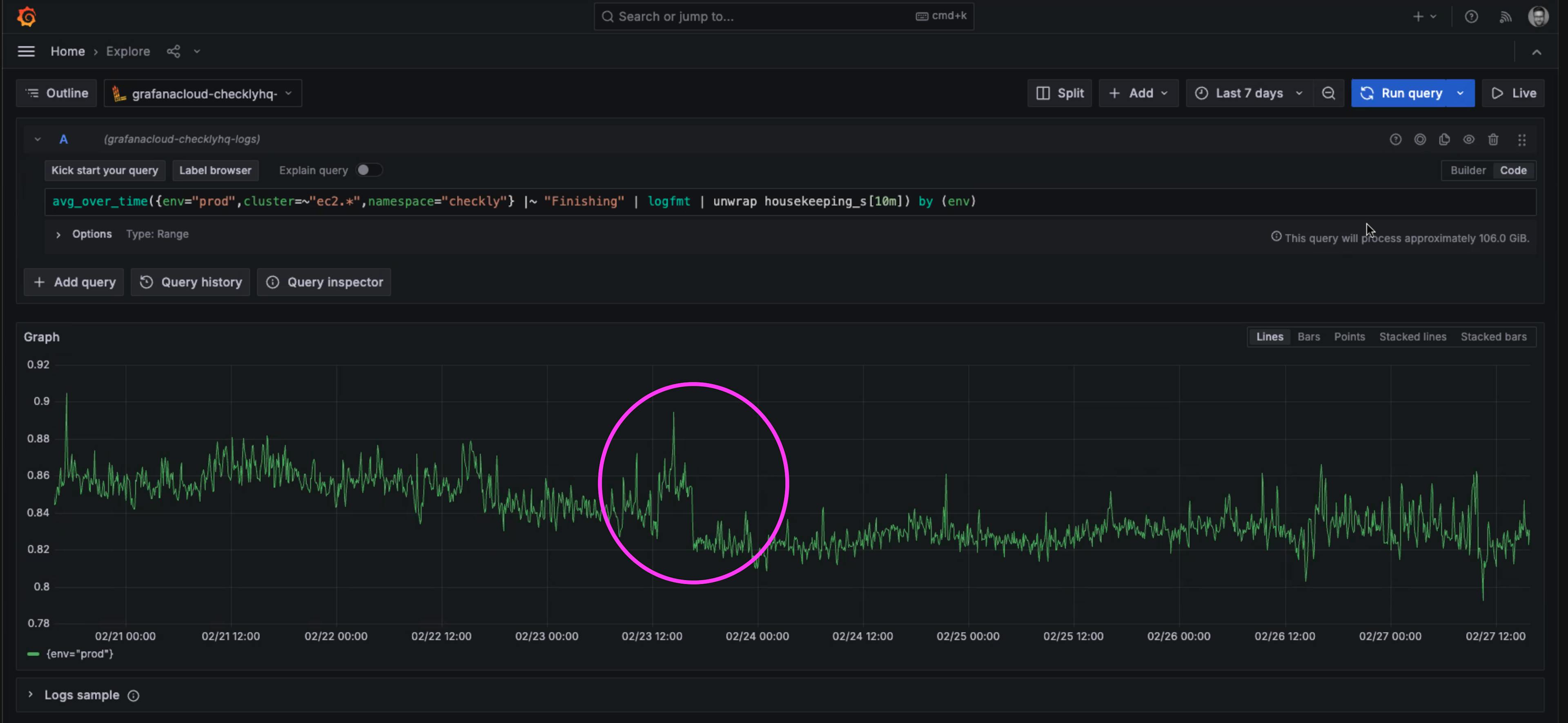
每次检查后运行的“维护”任务的平均执行时间下降了 40 毫秒。
将平均时间减少 40 毫秒可能看起来并不多,但这些任务是在每次检查后运行的。回想一下,即使每 2 分钟运行一次单页检查,每月也会超过 20,000 次检查。考虑到 Checkly 每月运行数亿次检查,这 40 毫秒的节省很快就会累积起来。
40 毫秒 * 2.5 亿次检查 / 每小时 3,600,000 毫秒 = 2,777 小时执行时间
这意味着在一个月的检查中,我们节省了超过 115 天的执行时间!结果是每个用户的性能略有提高,并且对我们的基础设施成本产生了重大影响,因为我们为完成相同任务而支付的计算时间更少。
可观测性是关于减少未知的未知数 - 不受欢迎的意外。这不是关于在错误发生之前捕获所有可能的错误 - 这是一个不切实际的目标。它是关于拥有可见性来理解和改进我们以前没有预料到的系统。Checkly 的愿景之一是,通过像 Checkly CLI 这样的工具,我们可以让每位工程师参与他们的监控工具。这种“监控即代码”(MaC)工作流程意味着,您可以通过让经验丰富的工程师帮助监控他们最了解的系统来减少意外事件的数量。
这里的故事强调了一个基本事实:无论你的测试多么彻底,代码多么干净,都会出现不可预见的问题。SDK 在不同的条件下会有不同的行为,在受控测试环境中有效的东西并不完全等于现实世界的操作。有些问题只发生在服务器环境中(而不是本地),OTEL 是一个很好的工具,可以深入了解已部署和正在运行的应用程序内部真正发生了什么。像 OpenTelemetry 这样的可观测性工具提供了我们观察这些条件、了解其影响并有效响应的镜头。
开放标准很重要。这就是为什么我们在 Checkly 支持开源 Playwright 库来编写我们所有的站点检查,从而允许自动执行像 视觉回归测试 和 等待元素 这样的复杂站点交互。
与捕获有关您最重要的流程的跟踪数据一样重要,重要的是拥有一个简单的方法来查看和共享这些数据,以便在您的组织中共享。在 Checkly,我们知道如果没有一个直观的界面来浏览我们所测量的数据,我们的合成监控数据就不会那么有用。
对于您后端服务的 OpenTelemetry 数据,Coralogix 是一个很好的地方,可以将这些数据发送到那里并分析您发现的内容。
使用 Coralogix 仪表板对我们的 OpenTelemetry 数据进行排序和过滤,可以轻松地观察到这个问题。将您的 遥测数据和 Coralogix 相结合,可以增强您系统可观测性的能力。
我们问题的解决方案 - 一个看似微不足道的优化 - 对运营效率和成本产生了深远的影响,节省了数千小时的执行时间。有时,它需要通过跟踪来寻找不“适合”的东西,并找出其他人是否也遇到了同样的问题。
OpenTelemetry 为监控数据的存储和共享带来了巨大的前景。 正是通过用于发送跟踪的 OpenTelemetry 标准,Checkly 团队实装了我们的 Coralogix 集成,以便将我们的综合用户监控跟踪发送至您的 Coralogix 控制面板。欢迎查阅我们最近对新集成的公告。
从经过良好监控的系统中获得的见解可以指导优化,通知架构决策,并且最终导致更具弹性和效率的应用程序。这就是我们支持 Monitoring as Code 工作流的原因,其中 Checkly CLI 等工具可以帮助您将监控转变为每个开发人员工作流程的一部分,直接从命令行运行和部署测试。
总之,监控您能够监控的所有内容。您将获得的见解是无价的。是的,OpenTelemetry 规则。