
Jon Udell 考虑 SQLite 和 DuckDB 是否可以在 LLM 助理团队的帮助下成为 Postgres 的分析替代方案。
译自 LLM-Assisted Translation From Postgres to SQLite and DuckDB,作者 Jon Udell。
我的 Hacker News 存储库提供了一组 Powerpipe 仪表盘,这些仪表盘使用 Steampipe 插件 从 Hacker News API 获取数据,并提供数据的交互式可视化。最初它只适用于 Postgres,但最近 Powerpipe 获得了将数据从 SQLite 和 DuckDB 传输到其仪表盘的功能。
一旦我让 SQLite 和 DuckDB 的移植正常工作,我发现两者运行仪表盘的几十个查询的速度几乎是 Postgres 的两倍。
这是主页仪表盘:

理论上,这些基于 Postgres 的仪表盘应该与 SQLite 和 DuckDB 完全相同。实际上,有两个层面存在需要解决的差异:HCL 和 SQL。Powerpipe 使用 HCL 定义小组件(包括图表、表格、信息卡和选择列表),并使用 SQL 将数据传输到这些小组件中。我们从 HCL 层开始。以下是 HCL 定义,用于比较 Hacker News 标题中提到的语言的三种不同时间尺度的面板三联画。
container {
chart {
base = chart.languages_base
width = 4
type = "donut"
title = "language mentions: last 24 hours"
query = query.mentions
args = [ local.languages, 0, 1440 ]
}
chart {
base = chart.languages_base
width = 4
type = "donut"
title = "language mentions: last 7 days"
query = query.mentions
args = [ local.languages, 0, 10080 ]
}
chart {
base = chart.languages_base
width = 4
type = "donut"
title = "language mentions: last 30 days"
query = query.mentions
args = [ local.languages, 0, 43200 ]
}
}这些以及类似的公司、数据库等三联画,会重复使用一个通用的 SQL 查询,query.mentions。每个图表实例会将三个参数传递给查询:一个名称列表(语言、公司等),以及一对整数,用于定义 Hacker News 帖子的年龄(以分钟为单位)。以下是当前的语言列表,表示为正则表达式,以便 SQL 查询可以进行模糊匹配。
languages = [
"C#",
"C\\+\\+",
"Clojure",
"CSS",
"Erlang",
"golang| go 1.| (in|with|using) go | go (.+)(compiler|template|monorepo|generic|interface|library|framework|garbage|module|range|source)",
"Haskell",
"HTML",
"Java ",
"JavaScript",
"JSON",
"PHP",
"Python",
"Rust ",
"Scala ",
"SQL",
"Swift",
"TypeScript",
"WebAssembly|WASM",
"XML"
]以下是接收这些参数的查询。
query "mentions" {
sql = <<EOQ
with names as (
select
unnest( $1::text[] ) as name
),
counts as (
select
name,
(
select
count(*)
from
hn
where
title ~* name
and (extract(epoch from now() - time::timestamptz) / 60)::int between symmetric $2 and $3
) as mentions
from
names
)
select
replace(name, '\', '') as name,
mentions
from
counts
where
mentions > 0
order by
mentions desc
EOQ
param "names" {}
param "min_minutes_ago" {}
param "max_minutes_ago" {}
}第一个 CTE(通用表表达式)将名称列表转换为一组行。Powerpipe 将名称作为字符串数组传递,这是一个本机 Postgres 类型,可以使用其 unnest 函数展开。对于这些名称中的每一个,第二个 CTE 会计算 hn 表中标题与名称匹配且时间戳在所需范围内帖子的数量。
这在 SQLite 或 DuckDB 中均不起作用。两者都不能接受字符串数组作为参数。ChatGPT 和 Claude 独立提出的解决方案是,在 HCL 层将列表转换为逗号分隔的字符串,然后在 SQL 层中以不同的方式展开它。以下是 HCL 部分。
locals {
joined_companies = join(",", local.companies)
joined_languages = join(",", local.languages)
joined_operating_systems = join(",", local.operating_systems)
joined_clouds = join(",", local.clouds)
joined_dbs = join(",", local.dbs)
joined_editors = join(",", local.editors)
}由于 DuckDB 的 string_to_array 和 unnest 函数,展开非常简单。在 SQLite 中,它出乎意料地复杂。
如果可能,我宁愿避免 SQL 递归。在这种情况下,ChatGPT 和 Claude 都指出了相同的解决方案,所以我勉强接受了。
# duckdb
with names as (
select
unnest(string_to_array(?, ',')) as name
),
# sqlite
WITH RECURSIVE names(name, remaining) AS (
SELECT
'',
? || ','
UNION ALL
SELECT
substr(remaining, 1, instr(remaining, ',') - 1),
substr(remaining, instr(remaining, ',') + 1)
FROM
names
WHERE
remaining != ''
),现在查询必须计算展开列表中每个名称的提及次数。以下是针对三个数据库得出的解决方案。
-- postgres
where
title ~* name
and (extract(epoch from now() - time::timestamptz) / 60)::int between $2 and $3
-- sqlite
where
title LIKE '%' || name || '%'
and (julianday('now') - julianday(datetime(substr(time, 1, 19)))) * 24 * 60 BETWEEN ? AND ?
-- duckdb
where
regexp_matches(title, name, 'i')
and (extract(epoch from CURRENT_TIMESTAMP::timestamp - time::timestamp) / 60) between ? and ?这种事情总是很繁琐,虽然 ChatGPT 和 Claude 肯定有帮助,但我必须严格监督它们。两者都渴望编写查询、函数或其他大量代码的完整新版本。这些重写通常会失败,虽然将错误传递回 LLM 有时可以快速解决,但该策略可能会变成死亡螺旋——就像在这种情况下一样。
正确的策略并不是什么高科技:将问题分解成可测试的小块,运行这些测试,以细粒度的方式解决问题,并逐步构建完整的东西。这只是你无论如何都应该做的,如果严格监督,LLM 可能会非常有帮助。但确实需要努力让它们保持专注。
我尝试使用以下说明自定义 ChatGPT 的基本用户级提示。
- 我需要逐步构建的实用解决方案,并具有明确定义且可测试的中间状态。
- 除非我明确要求,否则请不要编写代码,我总是想从讨论策略开始。
不过,这似乎并没有抑制其热衷于编写代码的风格。我必须真正地严格要求它以可测试的小增量工作。
主页仪表盘上的其余查询以不同程度的难度移植到 SQLite 和 DuckDB。正则表达式在三个数据库中工作方式不同,并且 LLM 可以轻松适应。日期时间类型和表达式也工作方式不同,它们提出了 本质上更困难的问题,并且在这些情况下,LLM 的帮助较小。一如既往,我依赖于两个 指导原则:永远不要信任,始终验证 和 比较 LLM 的输出。但这仍然有点费力。
回想起来,这种困难本不应该令人惊讶。我主要使用 Postgres,它很流行,搜索引擎很熟悉,因此 LLM 也很熟悉。但虽然 SQLite 多年来一直在发展,而 DuckDB 正在强势崛起,其在线足迹较小。
我们在此讨论的仪表板提供了相对流行度的非正式衡量标准。以下是黑客新闻标题中最近提到的三个数据库的计数。
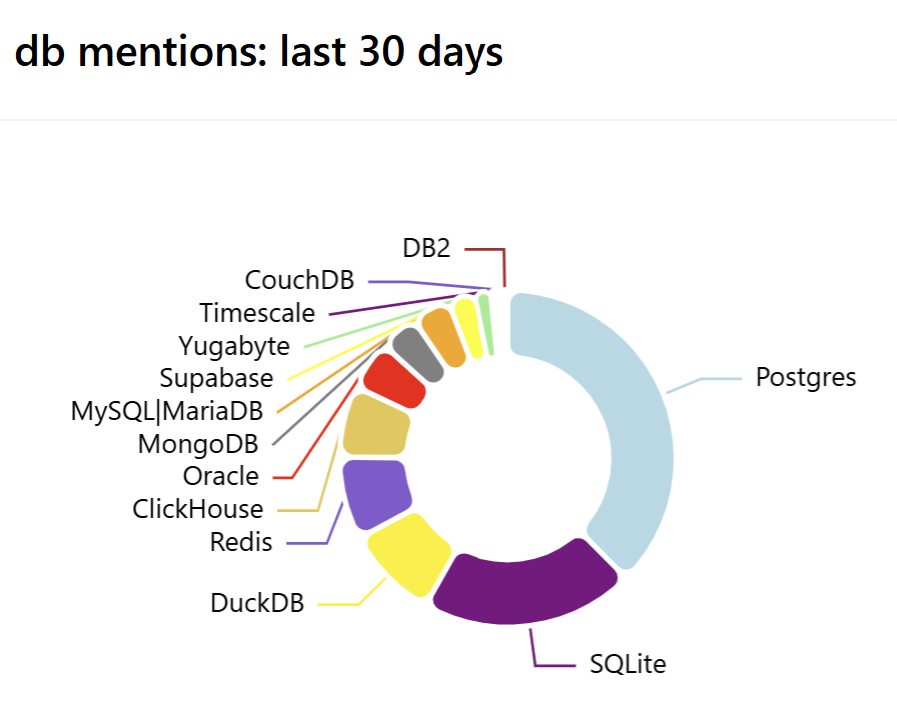
如果我需要定期使用 SQLite 或 DuckDB,我会使用支持 检索增强生成 (RAG) 的 LLM,例如 Unblocked,以使用文档和讨论丰富 LLM 上下文。同样的原则适用于 Python 和 JavaScript 以外的语言。当您使用最流行的技术时,LLM 会让您更轻松;在长尾中,您必须更加努力才能获得好处。
一旦我让 SQLite 和 DuckDB 端口工作,我发现两者都运行仪表板的几十个查询,速度几乎是 Postgres 的两倍。将 SQLite 和 DuckDB 都视为 Postgres 的分析替代品,DuckDB 很有趣。它感觉几乎和 SQLite 一样轻,Postgres 风格的 SQL 比 SQLite 更容易移植到它,它甚至可以附加 Postgres 表。但 DuckDB 还有另一种个性。它有时被称为“列式 SQLite”,它可以处理 Postgres 或 SQLite 无法处理的大型数据集(通常采用 Parquet 格式)。
到目前为止,我主要构建了连接到 Steampipe 的 Powerpipe 仪表板,Steampipe 是一个 Postgres 实例,它与 插件套件 配合使用,该套件将许多 API 和文件格式转换为 SQL。现在我已经以面向行的形式使用 DuckDB,我还想探索其面向列的个性,并了解在两个世界之间使用 SQL 作为桥梁是什么感觉。