
机器学习模型的能力正在迅速提升;我们如何在 Go 应用程序中利用这些强大的新工具?
译自 ML in Go with a Python sidecar,作者 Eli Bendersky。
对于像 ChatGPT、Gemini 或 Claude 这样的顶级商业大型语言模型 (LLM),这些模型都以与语言无关的 REST API 的形式提供。我们可以手动创建 HTTP 请求或使用 LLM 供应商提供的客户端库(SDK)。然而,如果我们需要更定制化的解决方案,就会出现一些挑战。完全定制的模型通常使用 TensorFlow、JAX 或 PyTorch 等工具在 Python 中进行训练,而这些工具并没有真正的非 Python 替代方案。
在这篇文章中,我将为 Go 开发人员介绍一些在他们的应用程序中使用机器学习模型的方法——定制化程度逐渐提高。预先总结一下,这很容易,而且我们只需要很少地处理 Python,甚至根本不需要——取决于具体情况。

这是最简单的类别:来自 Google、OpenAI 和其他公司的多模态服务以 REST API 的形式提供,并为大多数主流语言(包括 Go)提供了便捷的客户端库,以及在其上提供抽象的第三方包(例如 langchaingo)。
请查看今年早些时候发布的 Go 官方博客,标题为 在 Go 中构建 LLM 驱动的应用程序。我之前也在这个博客上写过这方面的内容:#1、#2和 #3 等。
在这个领域,Go 通常和其他编程语言一样受到良好支持;事实上,由于其网络原生特性,它对于此类应用程序来说尤其强大;引用 Go 博客文章中的话:
使用 LLM 服务通常意味着向网络服务发送 REST 或 RPC 请求,等待响应,然后根据响应向其他服务发送新请求,依此类推。Go 擅长所有这些,它为管理并发性和处理网络服务的复杂性提供了强大的工具。
由于这方面已经有了广泛的介绍,让我们继续讨论更具挑战性的场景。
有大量高质量的开源模型[1]可供选择,可以在本地运行:Gemma、Llama、Mistral 等等。虽然这些模型的功能不如最强大的商业 LLM 服务,但它们通常表现得非常好,并且在成本和隐私方面具有明显的优势。
业界已经开始对用于交付和共享这些模型的一些通用格式进行标准化——例如来自 llama.cpp 的 GGUF、来自 Hugging Face 的 safetensors 或较旧的 ONNX。 此外,还有许多优秀的开源工具,可以让我们在本地运行此类模型,并公开 REST API,以提供与 OpenAI 或 Gemini API 非常相似的体验,包括专用的客户端库。
最著名的此类工具可能是 Ollama;我过去曾广泛地写过关于它的文章:#1、#2 和 #3。
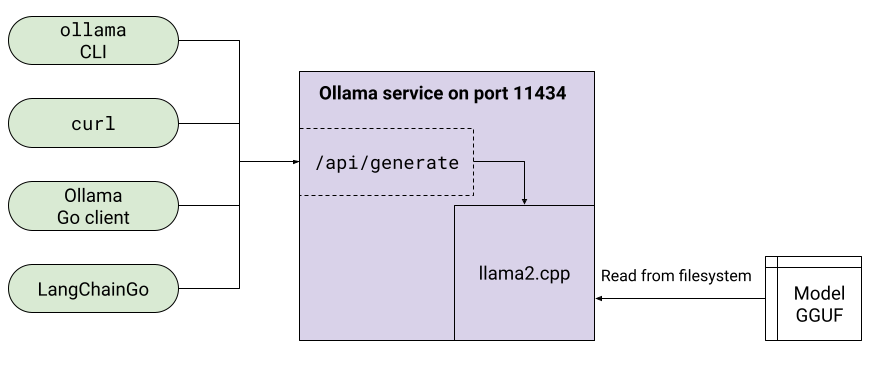
Ollama 允许我们通过 Modelfile 自定义 LLM,其中包括设置模型参数、系统提示等。如果我们微调了一个模型[2],也可以通过指定我们自己的 GGUF 文件将其加载到 Ollama 中。
如果您在云环境中运行,一些供应商已经提供了现成的解决方案,例如 GCP 的 Cloud Run 集成,这些解决方案可能会有用。
Ollama 也不是这个领域唯一的参与者;最近出现了一个新工具,它采用了一种略有不同的方法。Llamafile 将整个模型分发为一个二进制文件,该文件可移植到多个操作系统和 CPU 架构。与 Ollama 一样,它也为模型提供了 REST API。
如果这种定制的 LLM 适用于您的项目,请考虑直接运行 Ollama 或 Llamafile,并使用它们的 REST API 与模型进行通信。如果您需要更高程度的定制,请继续阅读。
在我们继续之前,我想简要讨论一下应用程序部署的 边车模式。该 k8s 链接讨论的是 容器,但这种模式并不局限于此。它适用于任何功能跨进程隔离的软件架构。
假设我们有一个应用程序需要一些库功能;以 Go 为例,我们可以找到合适的包,导入它并开始使用。然而,假设没有合适的 Go 包。如果存在具有 C 接口的库,我们可以选择使用 cgo 导入它。
但是假设也没有 C API,例如,如果该功能仅由一种没有方便的导出接口的语言提供。也许它在 Lisp、Perl 或……Python 中。
一个非常通用的解决方案是将我们需要的代码包装在某种服务器接口中,并将其作为单独的进程运行;这种进程称为 sidecar —— 它专门为另一个进程提供额外的功能而启动。无论我们使用哪种进程间通信 (IPC) 机制,这种方法都有很多好处——隔离、安全性、语言独立性等。在当今的容器和编排世界中,这种方法正变得越来越普遍;这就是为什么许多关于 sidecar 的链接都指向 k8s 和其他容器化解决方案。

上一节中概述的 Ollama 方法是使用 sidecar 模式的示例。Ollama 为我们提供 LLM 功能,但它作为服务器在其自己的进程中运行。
本文其余部分介绍的解决方案是使用 sidecar 模式的更明确和更完整的示例。
假设现有的开源 LLM 都不适合我们的项目,即使经过微调。此时我们可以考虑训练我们自己的 LLM——这非常昂贵,但也许别无选择。训练通常涉及大型机器学习框架之一,如 TensorFlow、JAX 或 PyTorch。在本节中,我不会讨论如何训练模型;相反,我将展示如何运行已经训练好的模型的本地推理——使用 Python 和 JAX,并将其用作 Go 应用程序的 sidecar 服务器。
该示例(完整代码在此)基于官方 Gemma 存储库,使用其 sampler 库 [3]。它附带一个 README,解释了如何设置所有内容。这是实例化 Gemma 采样器的相关代码:
# Once initialized, this will hold a sampler_lib.Sampler instance that
# can be used to generate text.
gemma_sampler = None
def initialize_gemma():
"""Initialize Gemma sampler, loading the model into the GPU."""
model_checkpoint = os.getenv("MODEL_CHECKPOINT")
model_tokenizer = os.getenv("MODEL_TOKENIZER")
parameters = params_lib.load_and_format_params(model_checkpoint)
print("Parameters loaded")
vocab = spm.SentencePieceProcessor()
vocab.Load(model_tokenizer)
transformer_config = transformer_lib.TransformerConfig.from_params(
parameters,
cache_size=1024,
)
transformer = transformer_lib.Transformer(transformer_config)
global gemma_sampler
gemma_sampler = sampler_lib.Sampler(
transformer=transformer,
vocab=vocab,
params=parameters["transformer"],
)
print("Sampler ready")模型权重和分词器词汇表是根据 Gemma 存储库 README 中的说明从 Kaggle 下载的文件。
因此,我们在 Python 中启动并运行了 LLM 推理;我们如何在 Go 中使用它?
当然,使用 sidecar。让我们围绕这个模型快速构建一个 Web 服务器,并在本地端口上公开一个简单的 REST 接口,Go(或任何其他工具)可以与之通信。例如,我围绕此推理代码设置了一个基于 Flask 的 Web 服务器。Web 服务器使用 gunicorn 调用——有关详细信息,请参阅shell 脚本。
除了导入之外,以下是完整的应用程序代码:
def create_app():
# Create an app and perform one-time initialization of Gemma.
app = Flask(__name__)
with app.app_context():
initialize_gemma()
return app
app = create_app()
# Route for simple echoing / smoke test.
@app.route("/echo", methods=["POST"])
def echo():
prompt = request.json["prompt"]
return {"echo_prompt": prompt}
# The real route for generating text.
@app.route("/prompt", methods=["POST"])
def prompt():
prompt = request.json["prompt"]
# For total_generation_steps, 128 is a default taken from the Gemma
# sample. It's a tradeoff between speed and quality (higher values mean
# better quality but slower generation).
# The user can override this value by passing a "sampling_steps" key in
# the request JSON.
sampling_steps = request.json.get("sampling_steps", 128)
sampled_str = gemma_sampler(
# ... rest of the code would be hereinput_strings=[prompt],
total_generation_steps=int(sampling_steps),
).text
return {"response": sampled_str}服务器公开了两个路由:
-
prompt:客户端发送文本提示,服务器运行 Gemma 推理并在 JSON 响应中返回生成的文本 -
echo:用于测试和基准测试
以下是所有内容组合在一起的样子:

重要的是,这只是一个示例。实际上,此设置的任何部分都可以更改:可以使用不同的 ML 库(例如 PyTorch 而不是 JAX);可以使用不同的模型(不是 Gemma,甚至不是 LLM),并且可以使用不同的设置在其周围构建 Web 服务器。有很多选择,每个开发人员都会选择最适合他们项目的选择。
还值得注意的是,我们总共编写了不到 100 行 Python 代码——其中大部分是将教程中的代码片段拼凑在一起。这少量的 Python 代码足以将带有简单 REST 接口的 HTTP 服务器包装在通过 JAX 在 GPU 上本地运行的 LLM 周围。从现在开始,我们可以安全地回到应用程序的实际业务逻辑和 Go 中。
现在,谈谈性能。开发人员对基于 sidecar 的解决方案的担忧之一是 Python 和 Go 之间 IPC 的性能开销。我添加了一个简单的 echo 端点来测量这种影响;看一下测试它的 Go 客户端;在我的机器上,从 Go 向 Python 服务器发送 JSON 请求并返回 echo 响应的延迟平均约为 0.35 毫秒。与 Gemma 处理提示并返回响应所需的时间(通常以秒为单位,或者在非常强大的 GPU 上可能以数百毫秒为单位)相比,这完全可以忽略不计。
也就是说,并非您可能需要运行的每个自定义模型都是成熟的 LLM。如果您的模型很小且速度很快,并且 0.35 毫秒的开销变得很重要怎么办?不用担心,它可以优化。这是下一节的主题。
这篇文章的最后一个示例混合了一些内容:
- 我们将使用一个简单的图像模型(而不是 LLM)
- 我们将使用 TensorFlow+Keras(而不是 JAX)自己训练它
- 我们将在 Python sidecar 服务器和客户端之间使用不同的 IPC 方法(而不是 HTTP+REST)
该模型仍然在 Python 中实现,并且仍然由 Go 客户端作为 sidecar 服务器进程驱动[4]。这里的想法是展示 sidecar 方法的多功能性,并演示一种在进程之间进行通信的低延迟方法。
示例的完整代码在此处。它训练了一个简单的 CNN(卷积神经网络)来对CIFAR-10 数据集中的图像进行分类:

使用 TensorFlow 和 Keras 的神经网络设置取自官方教程。以下是完整的网络定义:
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation="relu", input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation="relu"))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation="relu"))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation="relu"))
model.add(layers.Dense(10))CIFAR-10 图像是 32x32 像素,每个像素是红色、绿色和蓝色的 3 个值。在原始数据集中,这些值是包含范围 0-255 中的字节,表示颜色强度。这应该可以解释代码中出现的 (32, 32, 3) 形状。训练模型的完整代码位于示例中的 train.py 文件中;它运行一段时间并将序列化模型以及训练的权重保存到本地文件中。
下一个组件是“图像服务器”:它从磁盘加载训练的模型+权重文件,并对传入的图像运行推理,返回模型认为每个图像最可能的标签。
但是,服务器不使用 HTTP 和 REST。它创建一个Unix 域套接字并使用简单的长度前缀编码协议进行通信:

每个数据包都以一个 4 字节的字段开头,该字段指定其余内容的长度。类型是单个字节,主体可以是任何内容[5]。在示例图像服务器中,当前支持两个命令:
- 0 表示 "echo" - 服务器会将相同的包返回给客户端。包体的内容无关紧要。
- 1 表示 "classify" - 包体被解释为一个 32x32 的 RGB 图像,编码方式为:前 1024 字节为每个像素的红色通道(32x32,行优先),接下来的 1024 字节为绿色通道,最后 1024 字节为蓝色通道。服务器会将图像送入模型,并回复模型认为描述图像的标签。
示例还包括一个简单的 Go 客户端,它可以从磁盘读取 PNG 文件,将其编码为所需的格式,并通过域套接字发送到服务器,并记录响应。
客户端还可以用于对往返消息交换的延迟进行基准测试。与其解释它的作用,不如直接展示代码:
func runBenchmark(c net.Conn, numIters int) {
// Create a []byte with 3072 bytes.
body := make([]byte, 3072)
for i := range body {
body[i] = byte(i % 256)
}
t1 := time.Now()
for range numIters {
sendPacket(c, messageTypeEcho, body)
cmd, resp := readPacket(c)
if cmd != 0 || len(resp) != len(body) {
log.Fatal("bad response")
}
}
elapsed := time.Since(t1)
fmt.Printf("Num packets: %d, Elapsed time: %s\n", numIters, elapsed)
fmt.Printf("Average time per request: %d ns\n", elapsed.Nanoseconds()/int64(numIters))
}在我的测试中,往返的平均延迟约为 10μs(即 微秒)。考虑到消息的大小以及另一端是 Python,这与我之前对 Go 中 Unix 域套接字延迟的基准测试大致相符。
使用此模型进行单次图像推理需要多长时间?在我的测量中,大约需要 3 毫秒。回想一下,HTTP+REST 方法的通信延迟为 0.35 毫秒;虽然这仅占图像推理时间的 12%,但也足够接近,可能令人担忧。在强大的服务器级 GPU 上,时间可以更短[6]。
使用域套接字上的自定义协议,延迟(10μs)看起来可以忽略不计,无论最终在 GPU 上运行什么。
这篇文章中示例的完整代码位于 GitHub 上。
- [1] 吹毛求疵地说,这些模型并不完全开放:它们的推理架构是开源的,它们的权重是可用的,但它们的训练细节仍然是专有的。
- [2] 微调模型的细节超出了这篇文章的范围,但网上有很多关于这方面的资源。
- [3] 在大型语言模型(LLMs)中,“采样”大致意味着“推理”。一个训练好的模型被输入提示,然后“采样”以产生它的输出。
- [4] 在我的样本中,Python服务器和Go客户端简单地在不同的终端运行并相互通信。服务管理的结构非常具体于项目。我们可以设想一种方法,其中Go应用程序启动Python服务器在后台运行并与它通信。然而,这些天越来越可能的是一个基于容器的设置,每个程序都有自己的容器,一个编排解决方案启动和管理这些容器。
- [5] 你可能会好奇为什么我在这里实现一个自定义协议,而不是使用一些已经建立的东西。在现实生活中,我绝对推荐使用像gRPC这样的东西。然而,为了这个样本,我想要一些(1)