从 Borg 和 Omega 中汲取的经验教训,并将其应用于 Kubernetes。
译自 The Technical History of Kubernetes,作者 Brian Grant。
我没有参加 2024 年的 Kubecon,但是 Kubernetes 的十周年纪念在 KubeconEU 和 六月 再次庆祝,在那里我谈到了 通往 1.0 的道路。 你可能也对我 其他 Kubernetes 相关的帖子 感兴趣。
我们实际上在 2013 年就开始着手 Kubernetes 的工作,Kubernetes 直接基于之前几年所做的研发工作。当然,更早之前也有一些先驱,包括 Linux 容器、Borg、Workqueue 和 Babysitter,但我将重点介绍我直接参与的工作。五年前,我在 Twitter 上为五周年纪念写了一系列帖子。我终于抽出时间根据这些帖子发表了一篇博客(仍然是 Twitter 大小的段落)。我更新了一些链接并添加了一些标点符号,但除此之外没有做太多编辑。希望这比几十个单独的 Twitter 帖子更容易找到。
Kubernetes Borg/Omega 历史主题 1:Pod。在 Borg 中,作业任务被调度到 Alloc 实例中,但几乎每个人都将任务组固定到每个实例中。通常这些是 sidecar,例如用于日志记录或缓存。很明显,将这些组用作显式原语会更简单。我们称这些为“调度单元”。它们在 Borg 中进行了原型设计,但引入新概念太难了。它们在 Omega 中变成了“SUnits”,然后在 K8s 中变成了 Pod,就像豌豆荚或鲸鱼荚一样。
我们在 Kubernetes 的早期阶段讨论过是否要接受容器作为轻量级虚拟机的趋势,并且每个 Pod 只支持一个容器(最初在代码中称为 Tasks),但我很高兴我们没有这样做。每个容器一个应用程序释放了更智能管理的潜力。
它使 Kubernetes 和其他系统能够观察正在运行的应用程序(从它们的镜像)、它们何时以及为何失败、它们使用了多少 CPU 和 RAM 等。而且,重要的是,它使镜像能够在构建过程中生成,而不是在部署期间生成。
而且,经常被忽视的一点是,Pod 共享网络标识、存储卷以及其他操作系统和机器资源。这使得从虚拟机迁移更容易。
我们在 2013 年 10 月开始研究后来的 Kubernetes API,当时我们还没有确定开源或只是一个托管/管理的云项目。2014 年初,探索工作加剧,一些团队成员开始研究 libcontainer,容器代理于 2014 年 5 月发布。
Kubernetes Borg/Omega 历史主题 2:标签(Labels)。Borg 具有可在调度约束中使用的机器键/值属性。Borgmon 具有目标标签来传达应用程序拓扑、环境和区域设置。但作业本身最初没有键/值标签。因此,Borg 用户会将属性值嵌入到作业名称中,用点和破折号分隔,最多 180 个字符长,然后在其他系统和工具中使用复杂的正则表达式解析它们。
很明显,负载均衡器、监控系统以及发布、推出和配置工具需要共同支持识别可在应用程序的整个生命周期中流动的属性。然而,单值标签(如 gmail 和 GCE 中的标签)缺少类型。
因此,在 2013 年年中,我们为 Borg 和 Google Cloud 提出了键/值标签,以促进更高级别的应用程序管理。当然,将它们合并到像 Kubernetes 这样的全新项目中要容易得多,Kubernetes 从一开始就带有标签。
标签选择器语义最初是为监控系统设计的。监控和负载均衡系统希望确保可以构建不重叠的查询。如果没有析取,具有不同值的公共键可确保两个选择器不重叠。
选择器也足够简单,可以进行反向索引,watch 可以使用它来查找与新/更改的资源实例的标签匹配的未完成查询。但我们还没有在 K8s 中实现这一点(https://github.com/kubernetes/kubernetes/issues/4817)。
SRE 在最初设计中要求的我们尚未实现的另一件事是默认、要求、禁止和验证标签键和值的方法:https://github.com/kubernetes/kubernetes/issues/15390。
Kubernetes Borg/Omega 历史主题 3:注解(Annotations)。Borg 的作业类型只有一个注释字段。与 DNS TXT 记录一样,这被证明是不够的。例如,客户端库和工具层希望附加其他信息。
一些用户发现了其他创造性的方法来携带信息,例如调度偏好,其中可以存储任意的键/值字符串。最终支持了任意的 protobuf 扩展。
这是 Kubernetes API 的许多部分中的一个常见主题:考虑何时可能需要多个值或键/值对,而不仅仅是单例值。我在 #1201 中提出了 annotations。
Annotations 提供了一个地方来存储 apply 的配置状态,如 #1178 和 #1702 中所述,并在 v1beta3 API 改进 (prs.k8s.io/1225) 中包含了 Openshift 的 description 字段。
有些人认为拥有两种键/值字符串元数据(标签和注解)会令人混淆,因此我很早就努力在文档中阐明它们的区别,例如在 #1817 中。我认为将它们统一会降低可用性。
Kubernetes Borg/Omega 历史主题 4:工作负载控制器。在介绍历史之前,一些概念背景可能会有用,因为这些基础知识在许多云原生环境中都会出现。关键是显式地对状态进行建模,以便可以对其进行外部操作。
在 Kubernetes 开源前后,创建了许多库和工具来在多台机器上启动容器。最初的 libswarm 就是其中之一。这种命令式、客户端方法的问题在于难以添加自动化。
可以通过模拟单台机器的远程 API 在两者之间插入一个调度程序,但这仍然缺乏用户尝试实例化的内容的显式模型,相当于 Kubernetes 中的 Pod 模板。
其他一些工具添加了这一点,但缺乏对实例集进行建模,以及显式的副本计数,是更高层自动化(例如水平自动缩放和渐进式滚动更新)的障碍,Kubernetes 在 1.1 和 1.2 中都添加了这些功能。
Kubernetes 最初只支持一个工作负载控制器,即 ReplicationController,它是为具有可替代副本的弹性无状态工作负载而设计的。在我们开源 Kubernetes 后不久,我们开始讨论如何添加对其他类型工作负载的支持。
在 #1518 中,我们开始讨论后来成为 DaemonSet 的内容。关键的决定是是否向 ReplicationController 添加更多功能,还是创建新的资源类型。其他系统的用户担心使用多种类型的复杂性。
Borg 只支持一个工作负载“控制器”,即 Job。(我将在稍后讨论 Borg 的同步状态机和 Kubernetes 异步控制器之间的区别。)Borg 论文对此进行了很好的描述:https://ai.google/research/pubs/pub43438。
Job 是一个 Tasks 数组,用于弹性服务、在每个节点上运行的代理、批处理工作负载和有状态工作负载。因此,它有大量的设置,并且需要额外的外部控制器来支持这些不同的工作负载。
例如,对于守护程序用例,需要一个特殊的控制器/自动缩放器来确保 Job 具有足够数量的 Tasks 来覆盖所有机器,并且需要对从数组中间移除机器的情况进行特殊处理。
不仅 Job 是一级原语而不是 Tasks,而且每个 Task 都有一个稳定的标识,就像 Kubernetes 中的 StatefulSet 一样。这不仅对守护程序,而且对自动缩放的工作负载、CI 工作负载、正常终止、调试等都过于严格。
Job 还包括已发布的 Tasks 的 BNS 记录,这大致相当于 Kubernetes 中的 Endpoints。BNS 记录存储在 Chubby 中,可以在其中进行观察。(我稍后将更全面地介绍 K8s 中的 watch。)
Pod、工作负载控制器和 Endpoints 的解耦,以及 Kubernetes 中多个工作负载控制器的先例,已被证明非常灵活,可以支持许多类型的负载。现在有许多特定于应用程序的工作负载控制器(也称为 Operators)。
如 #170 中提出的,将 PodTemplate 显式表示为一个单独的对象,对于这些第三方控制器可能也很有用,但实际上缺乏对此的支持并没有成为一个巨大的障碍。(嗯,API 存在,但未使用。) 我在 2013 年 6 月提出了将工作负载控制器建模为使用标签选择器分组的松耦合实例集的想法,该想法基于对 Borg Job 用例的 11 页分析,与最初的标签提案大致处于同一时间段。
这也在一定程度上启发了 replicapool.googleapis.com,尽管当时 GCE 缺少标签使得实现完整模型不可行。
关于“模板”: “模板”是用于制作相同形状副本的模式。我认为 Kubernetes 的“Pod 模板”用法符合该口语定义,但典型的 CS 用法暗示参数化和/或宏扩展,因此也许“原型”会更好。
显式建模状态以便可以对其进行外部控制和观察是云原生的一个关键原则。我最初将其包含在我为 CNCF 编写的更长形式的定义中:https://github.com/cncf/toc/blob/master/DEFINITION.md。
该原则也可以应用于工作流系统和配置管理(例如,参见 https://github.com/kubernetes/design-proposals-archive/blob/main/architecture/declarative-application-management.md)。将这些体现为代码功能强大,但能力越大,责任越大,因为它阻碍了外部工具和自动化。
Kubernetes Borg/Omega 历史主题 5。异步控制器。Borgmaster 具有同步的、事务性的、边缘触发的状态机。我们在扩展、演进和扩展它们方面遇到了挑战。
高基数资源实例可能超出单个事务可以完成的范围。添加新状态会破坏客户端。未观察到的更改可能会导致意外的状态转换。添加新的资源类型很困难,并且必须添加到单体文件中。
因此,当新团队致力于新功能(例如批处理调度和自动缩放)时,他们将其构建到外部组件中,这些组件是异步的。从节点(Borglets)提取状态也是异步的。Omega 采用了异步控制器。
Omega 在其事务性 Paxos 存储中的单独记录中表示所需状态和观察到的状态。这使得更难组合出一幅正在发生的事情的画面。在 Kubernetes 中,我们决定在 v1beta3 中在与规范相同的对象中表示状态:http://issues.k8s.io/1225。
我们也完全接受了控制器模型,即使对于 Kubelet 也是如此,通过让 Kubelets 向 apiserver 报告(http://issues.k8s.io/156)并修补状态(https://github.com/kubernetes/kubernetes/issues/2726),以便 API 可以用作其他控制器的真相来源。
我们最初采用可以报告处于每种状态的开放式原因的简单基本状态(https://github.com/kubernetes/kubernetes/issues/1146),而不是僵化的细粒度状态枚举,这些枚举无法演进,后来又采用了非正交的、可扩展的条件(http://issues.k8s.io/7856)。
现在,整个系统可以描述为无限数量的独立异步控制循环,从/向模式化资源存储读取和写入作为真相来源。这种模式已被证明非常有弹性、可演进和可扩展。
Kubernetes Borg/Omega 历史主题 6:Watch。这是一个深入的主题。它是控制器主题的后续。我意识到我忘记链接到关于 Kubernetes 控制器的文档: https://github.com/kubernetes/community/blob/master/contributors/devel/sig-api-machinery/controllers.md。
Borgmaster 有 2 种模型:内置逻辑使用同步边缘触发状态机,而外部组件是异步的和基于级别的。更多关于级别与边缘触发的信息:https://hackernoon.com/level-triggering-and-reconciliation-in-kubernetes-1f17fe30333d。
我在 2009 年加入 Borgmaster 团队时做的第一件事就是并行化读取请求的处理。大约 99% 的请求是读取,主要来自轮询外部控制器和监控系统。
只有 BNS(类似于 K8s 端点)被写入 Chubby,这使得复制缓存和更新通知成为可能。这使其能够扩展到更大数量的读取器(Borg 中的几乎每个容器)并减少延迟,对于轮询来说,延迟可能是数十秒。 类似于手表的通知 API(又称同步和尾随)在 Chubby、Colossus 和 Bigtable 等存储系统中很常见。在 2013 年,设计了一个通用的 Watch API,这样每个系统就不需要重新发明轮子了。一个名为“Observe”的变体添加了针对每个实体的排序。
我们基于 Etcd 构建了 Kubernetes,因为它与 Chubby 和 Omega 存储类似。当我们通过 K8s API 暴露 Etcd 的 watch (https://coreos.com/etcd/docs/latest/learning/api.html) 时,我们让更多的 Etcd 细节泄露了出来,这超出了最初的预期。我们需要尽快清理其中的一些细节。
Kubernetes 模型的描述如下:https://github.com/kubernetes/design-proposals-archive/blob/main/architecture/resource-management.md#declarative-control。
其他一些系统使用消息总线进行通知。为什么我们没有这样做?控制器需要从初始状态启动,我们也不希望它们落后或对过于陈旧的状态进行操作,并且它们需要能够处理“丢失”的事件——基于级别的基本原理。
我们还希望 Kubernetes 能够以少量依赖项运行,并具有有限的计算和存储容量:如果我们假设一个托管消息总线可以存储一周的事件,并且有一个弹性计算平台可以并行处理它们,那么设计将会不同。
对于我们典型的场景(大多数实体处于活动状态,每个实体的变化率很高,而不是大量不活动的实体(例如,销售目录条目)),Watch 的效果很好,因为它假设可以访问所有相关状态。在某种程度上,我们需要进行分片。
需要键/值存储进行领导者选举和配置、数据库进行持久化、进程外缓存以提高性能、消息总线进行事件传递以及消息总线持久化存储(3-5 个有状态组件)的系统可能难以操作。
Kubernetes Borg/Omega 历史主题 7:Kubernetes 资源模型:为什么我们(最终)使其统一和声明式。一个比 watch 更深入的主题。更多细节可以在这里找到: https://github.com/kubernetes/design-proposals-archive/blob/main/architecture/resource-management.md。
像大多数 Google 内部服务一样,Borgmaster 有一个命令式、非版本化的单体 RPC API,它是使用 grpc.io 的前身 Stubby 构建的。它公开了一组特别的临时操作,例如 CreateJob、LookupPackage、StartAllocUpdate 和 SetMachineAttributes。
成百上千的客户端与这个 API 交互。正如前面讨论的那样,其中许多是异步控制器或监控代理,还有一个简单的命令行工具和两个广泛使用的配置 CLI。
API 被手动映射到两种图灵完备的配置语言中,并且还有一个手工制作的 diff 库,用于比较先前和新的期望状态。概念集、RPC 操作和可配置资源类型不容易扩展。
核心功能的一些扩展,例如批量调度和垂直自动缩放,通过手动添加与 Job 对象一起存储的子结构来使用 Borgmaster 作为配置存储,然后通过轮询 Job 来检索这些子结构。
其他一些扩展,例如负载均衡,构建了具有自己的服务 API 和配置机制的独立服务。这使得团队能够独立地发展他们的服务,但也创建了一个异构的、不一致的管理界面。
Omega 支持可扩展的对象模型,@davidopp 曾提议在持久存储的前面放置一个 API,就像我们后来在 Kubernetes 中所做的那样,但它不是声明式的。随着 Google Cloud 成为焦点,关于通用配置存储的单独工作被停止了。
GCP 由独立的服务组成,具有一些共同的标准,例如组织层次结构和授权。它们使用 REST API,就像业内其他公司一样,而且 gRPC 当时还不存在。但是,GCP 的 API 不是原生声明式的,Terraform 也不存在。
@jbeda 提议在底层 GCP 和第三方服务 API 之上构建一个具有统一的声明式 CRUD REST API 的聚合配置存储/服务。这后来演变成了 Deployment Manager。
我们将从这 5 个以上的系统中吸取的经验教训融入到 Kubernetes 资源模型中,该模型现在支持任意数量的内置类型、聚合 API 和集中式存储 (CRD),并且可用于配置第一方和第三方服务,包括 GCP:https://youtu.be/s_hiFuRDJSE。 KRM 是一致的和声明式的。元数据和动词是统一的。规范和状态是明显分开的。资源标识符,其建模非常类似于 Borgmaster 的 (http://issues.k8s.io/148),提供了声明式名称。标签选择器支持声明式集合。
大多数情况下,控制器知道哪些字段要从一个资源实例传播到另一个资源实例,并在声明式对象(而不是字段)引用上优雅地等待,而无需假设引用完整性,这使得操作顺序更加宽松。
该模型中存在一些差距(例如,http://issues.k8s.io/34363,http://issues.k8s.io/30698,http://issues.k8s.io/1698,http://issues.k8s.io/22675),但在大多数情况下,它有助于对任意资源类型执行通用操作。
在下一个主题中,我将详细介绍配置本身,例如 kubectl apply 的起源。
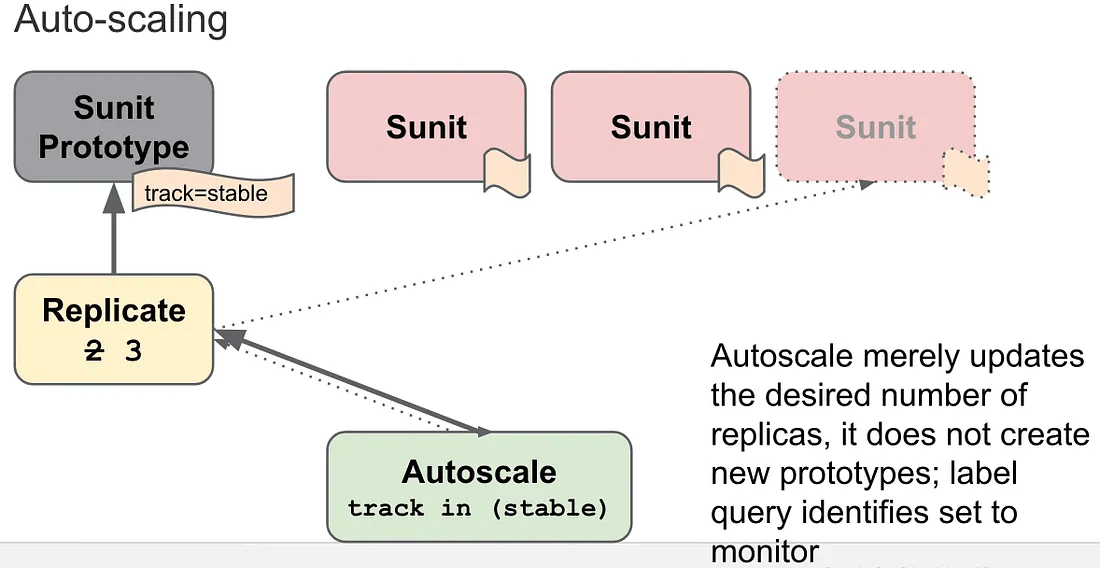
顺便说一句,当我翻阅旧文档/演示文稿时,我发现了 2013 年 12 月 API 提案中的一个图表:Sunit->Pod,SunitPrototype->PodTemplate,Replicate->ReplicaSet,Autoscale->HorizontalPodAutoscaler。
Kubernetes Borg/Omega 历史主题 8:声明式配置和 Apply。在 Google 内部,Borg 最常用的配置方法是图灵完备的 Borg 配置语言 (BCL)。您可以在此演示文稿的幻灯片 7 中看到 BCL 的片段:inf.ed.ac.uk/teaching/cours…
已经编写了数百万行 BCL 代码。相当一部分 BCL 用于配置应用程序命令行标志,这是配置服务器二进制文件最常用的方法,在我看来这很疯狂,但遗憾的是,这种做法延续到了 Kubernetes 组件中。
BCL 使用 borgcfg CLI 进行评估和实例化,该 CLI 支持 up、down 和 update 等命令。用于比较和合并、执行滚动更新以及更新实时状态的逻辑嵌入在该工具中。常见生成函数的逻辑是用 BCL 编写的。
这创建了一个单体配置和工具生态系统。即使是像 mapreduce 这样的框架和 Borg 之上的服务(如 BorgCron)也必须使用 BCL 和 borgcfg 与 Borg 交互。入门工具会生成 BCL。
后来还开发了一种基于 Python 的语言。它通过一个与 Borgmaster 不太相同的 protobuf 与更新逻辑交互。其他语言,例如 Ruby,在 Google 中没有使用。开发了几种新的 Borg 配置语言,但都没有获得批准。
jsonnet.org/articles/desig… 和 https://github.com/cuelang/cue/ 的灵感来自 BCL,但并非专门为 Borg 使用而开发。aurora.apache.org/documentation/… 和 https://github.com/stripe/skycfg 的灵感来自 Python 语言。
Borgcfg 不提供配置包。共享模板未进行版本控制,而是直接从它们在单体存储库中的位置导入,这给它们的使用者带来了麻烦。也没有“堆栈”或生命周期指令,因此需要一些强制性更新。
在 Kubernetes 中,我们希望将配置编写和生成与通过 API 对所需状态的更新解耦,以便用户可以使用他们熟悉的语言和工具来表达配置:Jinja、Python、Ruby、Javascript、Terraform、Ansible 等。
我在 http://prs.k8s.io/1007 中写过这方面的内容。我还认为自动化应该能够直接写入 API,而不需要更新某些任意的配置语言。为此,我们需要能够合并用户意图和自动化更改。
我在 http://issues.k8s.io/1178 中的最初提案是在服务器中维护和合并两层独立的所需状态。对这个想法的抵制导致了我在 http://issues.k8s.io/1702 中提出的客户端 Apply 提案。我们终于要实现服务器端 apply 了:https://github.com/kubernetes/enhancements/blob/master/keps/sig-api-machinery/0006-apply.md。
在 Apply 实现的早期,我们遇到的一个问题是复杂的模式拓扑。合并两个扁平的 map 很容易,但不幸的是,我们有关联列表:关联列表。还有集合和未区分的联合(正在处理:联合)。
战略合并补丁的开发是为了让我们可以比较和合并两个包含关联列表(在列表元素内的字段值中带有索引键的非有序列表)的对象:战略合并补丁。
我在声明式应用管理中写了关于配置设计动机和原则的概述。该文档的原始草案还包含了后来成为application 和 kustomize 的草图。
Apply 促进了人机之间的协作配置创作(感谢@originalavalamp 的描述),而 kustomize 通过促进对未更改的基本原型/种子配置的修改,实现了人与人之间的协作。
声明式 API、Apply 和 kustomize 有助于将配置维护为 YAML 或 JSON 或 proto 格式,以便于工具操作,而不是使用带有宏的 YAML、复杂的配置语言或用通用编程语言编写的脚本。
一方面,已开发的约 100 个工具表明,配置格式与 API 的解耦是有效的。另一方面,它也表明仍然存在差距。通过像 diff 和 dry run (diff and dry run) 和 prune (prune) 这样的工作,我们正在努力弥合这些差距。
工具列表可以在这里找到:工具列表。我刚刚添加了其他 20 个左右我看到的工具。这个帖子已经是迄今为止最长的了,所以我稍后将开始另一个关于配置术语的帖子:声明式 vs 意图、宏 vs 配置语言、包 vs 堆栈、原型 vs 模板、白盒 vs 黑盒、覆盖、生命周期指令等。
我与@eric_brewer 在 Google 共事多年,包括在配置方面,在 Omega 和 Kubernetes 之间。在这个播客的后半部分,Eric 也简要讨论了声明式配置:声明式配置播客。
顺便说一句,最终一个名为 ProdSpec 的“生产数据库”确实成功并推出了。Borg 已经趋向于类似于 Kubernetes 资源模型和“GitOps”的模型(尽管我们的内部 VCS 不是 git),这里有描述:描述。
Kubernetes Borg/Omega 历史主题 9:调度约束。关于配置,我还有很多要写的内容,但现在将继续讨论历史主题。Borg 的约束集随着时间的推移而有机地增长。它开始时只有所需的内存,在多核和 NPTL 之前。其他资源也添加了:cpu、磁盘。对键/值机器属性的硬约束和软约束,以及“属性限制”以限制每个故障域的任务数量。自动注入的反约束用于实现专用机器。
在 Omega (Omega) 中,我们添加了污点和容忍的概念,以便包含一些临时方法来防止大多数任务的调度和/或将它们从某些机器中驱逐,以及 forgiveness 以推迟驱逐。
这些调度功能非常直接地融入了 Kubernetes:#168, #367, #1574, #17190。@davidopp 曾是 Borg 和 Omega 中调度的 TL,也参与了 Kubernetes 中许多这些功能的开发。
我在 2015 年初写的一份调度心得 (kubernetes/kubernetes#4301 (comment)) 可能有助于说服一些人,Google 确实在与该项目充分分享其经验。调度设计文档可以在 kubernetes/design-proposals-archive 中找到。
这些机制可用于管理工作负载如何进行装箱以提高效率、分散以提高可用性、彼此隔离以提高性能、可靠性或安全性、与所需资源共存、与所需配置匹配以及管理节点排出。
这些调度原语非常灵活,但如果存在无法表示的约束或其他策略或标准,用户可以使用自己的调度程序。要在 Borg 中做到这一点,必须向任务添加约束以将其固定到特定机器。
Omega 论文比较了具有信息隐藏的二级调度的性能,但它没有提到一个问题,即低级调度程序需要实现与所有高级调度程序相同的所有约束,否则它可能永远无法满足它们的要求。
无论如何,虽然资源优化是一个重要问题,但在决策中还有许多其他考虑因素,例如容器镜像是否已经驻留,这有助于加快启动时间。
Kubernetes Borg/Omega 历史主题 10:为了纪念 #KubeConEU 和 Kubernetes 开源五周年,我将从 Borg 和 Omega 团队的角度为起源故事添加更多视角。
在内部,Google 非常重视资源效率和工程效率。出于这两个原因,早在 2013 年 6 月,也就是 GCE 即将正式发布前的几个月 (Google Compute Engine 正式发布),Borg 和 GCE 团队开始更紧密地合作以改进这两方面。
最初的重点倾向于直接支持 Cloud 在 Borg 中所需的功能,这样 Cloud 就无需解决缺少这些功能的问题(请参阅我之前关于二级调度的评论:二级调度评论)。
Google 还花费大量精力不断减轻其内部软件和基础设施中的熵。单体仓库就是其中一种机制。它还启动了许多工作来“统一”或“融合”共同演化以执行类似操作的多个系统。
在这种情况下,两个月后,Google Cloud 和 Google 的内部基础设施组“TI”(包括 Borg)成立了统一计算工作组。目标是制定一个“计算平台”的提案,供 Cloud 和内部客户使用。
很明显,虚拟机过于繁琐和低效,而 App Engine 的通用性不足以运行各种内部服务,例如网络搜索和 Gmail。我们需要一个更像 Borg 的、基于容器的平台。
人们讨论了它应该与 App Engine 和 Borg 的兼容程度。比较了 Docker、构建包和 Omlet(一个正在开发的新节点代理,用于取代 Borglet)。早期的讨论假设了一个托管服务,如 GCE、GAE 和 Borg。
2013 年 9 月,收集了 9 位以上工作组参与者的观点,并将其编写成“统一计算 PRD”,重点是服务工作负载(例如,而不是批处理)。那是我第一次意识到“容器即服务”一词的使用。
10 月,成立了工作组的子组,以专注于关键问题,包括容器管理 API 子组。11 月,我们从 Borg 和 Cloud 引入了更多人员来讨论许多 API 细节。12 月,向整个工作组提交了一份 API 提案。
在同一次会议上,提出了后来成为 App Engine 灵活环境的提案 (App Engine 灵活环境),以及构建开源容器平台的提案,这样我们就不会被其他开源项目“Hadoop 化”。
那个开源容器平台是 Project 7。之后,Borg 团队和 Cloud 团队都提出了几个构建具有兼容 API 的产品的建议。与 Borg 团队的合作加深了。Borglet 团队成员于 2014 年 4 月开始为 Docker 研发 libcontainer。
其他 Borg 团队成员(我 @thockin @erictune4 Dawn Chen @originalavalamp @davidopp @vishnukanan)应该参与这个开源项目来设计和开发类似 Borg 的功能,这一点很快就变得清晰起来。我们深信其对外部用户的潜在价值。因此,我们创建了 Kubernetes,因为我们需要它,并且我们相信其他人也需要它。回顾当时(以及之后)可用的其他解决方案(例如,tsuru/docker-cluster, signalfx/maestro-ng),我们做出了正确的决定。
Kubernetes Borg/Omega 历史主题 11: PodDisruptionBudget。Google 在其数据中心不断执行软件和硬件维护:固件更新、内核和镜像更新、磁盘修复、交换机更新、电池测试等等。随着时间的推移,种类越来越多。即使 Borg 任务被设计为具有弹性,这也会造成相当大的干扰。如果存在几十个维护任务,则单独限制每个任务的速率效率低下,并且并非总能同时执行所有类型的维护。
即使限制了机器中断的速率,相同的任务也可能一次又一次地被打断,就像一个罐子在路上被踢来踢去。因此,站点可靠性工程师(SRE)开发了安全移除服务(又名 SRSly,发音为 seriously)。SRE 构建了大量的自动化。
SRSly 跟踪相同 Borg 作业的任务被中断(即被驱逐)的频率。维护自动化会在将机器停用之前查询 SRSly,了解该机器上调度的所有任务。这使 Borg 能够提供任务中断的服务等级目标 (SLO)。
然而,Borgmaster 并不知道 SRSly。相反,所有关键/生产工作负载都被更改为以相同的优先级运行,这样它们就不会互相抢占。为公司中的每个 Borg 作业执行此操作非常痛苦——稍后将详细介绍优先级/抢占。对于 Omega,我们开发了一个模型,该模型可以应用于任务抢占以运行更高优先级的任务以及用于维护的驱逐——中断计数器。由于不断的变化,时间维度最终失效了,所以我们在 Kubernetes 中放弃了它。
我认为我第一次在 Kubernetes 中提到这一点是在我的大型调度思路评论中:kubernetes/kubernetes/issues/4301#issuecomment-74355529。当我提议使用 maxUnavailable 来缓和 Deployment 设计期间更新导致的并发中断时,它再次出现:kubernetes/kubernetes/pull/12236#discussion_r36501373。
该讨论被分叉到 kubernetes/kubernetes/issues/12611。大约在那个时候,Matt Liggett (kubernetes/kubernetes/pulls?q=is%3Apr+author%3Amml+is%3Aclosed) 从 Borg SRE 加入 GKE 团队(太好了!)。Matt 最早从事的工作之一是改进节点排出:kubernetes/kubernetes/issues/6080。
我们与 @davidopp 和 @erictune4 一起将中断预算纳入了重新调度设计方案:kubernetes/community/blob/master/contributors/design-proposals/scheduling/rescheduling.md#disruption-budget。(重新调度值得拥有自己的主题——我接下来会做这个)。
实施始于 https://github.com/kubernetes/kubernetes/pull/24697 和 https://github.com/kubernetes/kubernetes/pull/25551,PodDisruptionBudget 现在有文档支持:https://kubernetes.io/docs/concepts/workloads/pods/disruptions/ 和 https://kubernetes.io/docs/tasks/run-application/configure-pdb/。试试看,告诉我们它对你来说效果如何。我们希望将其从测试版推进到正式版:https://github.com/kubernetes/enhancements/issues/85。
您可以使用 kubetctl排出安全地排出节点: https://kubernetes.io/docs/tasks/administer-cluster/safely-drain-node/ 。 Google Kubernetes Engine (GKE) 中的节点升级和集群自动缩放程序也遵循 PodDisruptionBudget。后者记录在此处:https: //cloud.google.com/kubernetes-engine/docs/concepts/cluster-autoscaler 。
节点升级行为记录在此处: https://t.co/eyWfp2TZn3。有关自动化背后的 Google SRE 理念的更多信息,请参阅 SRE 书籍: https://sre.google/sre-book/automation-at-google/ 。
Google 在 VEE 2018 上发表的《VM Live Migration at Scale》论文中也提到了安全删除服务: https ://dl.acm.org/doi/10.1145/3296975.3186415。
Kubernetes Borg/Omega 历史主题 12 :PodDisruptionBudget 主题的后续内容:descheduler ( https://github.com/kubernetes-incubator/descheduler )。 Descheduler 比原来的术语“重新调度器”更合适,因为它的工作是决定杀死哪些 Pod,而不是替换或调度它们。
在 Kubernetes 中,当在 GKE 等云提供商上运行时,如果待处理的 Pod 没有可用空间可放置,则可以进行集群自动缩放,甚至可以进行节点自动配置( https://github.com/kubernetes/autoscaler/blob ) /master/cluster-autoscaler/proposals/node_autoprovisioning.md , https://cloud.google.com/kubernetes-engine/docs/how-to/node-auto-provisioning )可以为它们创建新节点。
在 Borg 中,创建重新调度程序是为了对节点进行碎片整理以腾出空间。它选择要驱逐的任务,以便新任务可以安排,同时也确保被驱逐任务的替代者也可以找到新家,以免造成不必要的流失。
在 K8s 中,descheduler 的目的主要是对 pod 进行重新洗牌,以改善 pod 跨节点的整体分布。由于 Pod 自动缩放、Pod 更新、用于批处理/CI 任务的 Pod 等而导致 Pod 终止,导致集群发生一些变动后,Pod 布局可能会变得不均匀。
一个简单的示例:假设集群自动缩放器 ( https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler ) 为新 Pod 添加了一个新节点。如果这些 pod 是由于创建新的 Deployment 或 ReplicaSet 而导致的,那么如果现有节点上没有足够的空间,它们可能会全部落在新节点上。
根据 Borg 的经验,我们知道 Kubernetes 项目一开始就需要调度器。我认为在讨论添加活性和就绪探针时首先提到了这一点: https ://github.com/kubernetes/kubernetes/issues/620#issuecomment-50110653。
这使我们能够在 pod 创建和工作负载控制器替换、HPA 水平扩展、调度程序放置以及 descheduler 跨节点和故障域重新平衡之间建立明确的关注点分离,这将尊重 PDB。
在设计无响应节点的驱逐时( https://github.com/kubernetes/kubernetes/issues/3885#issuecomment-71984989 )以及 issues.k8s.io/12140 中讨论了这种划分。设计文档可以在https://github.com/kubernetes/community/blob/master/contributors/design-proposals/scheduling/rescheduler.md和https://github.com/kubernetes/community/blob/master找到/contributors/design-proposals/scheduling/rescheduling.md 。
需要注意的是,如果集群中的流失率足够高,并且由于 PodDisruptionBudgets 的限制,驱逐受到很大限制,则 descheduler 可能无法跟上。这就是为什么可能无法实现“最佳”布局的原因之一。
Kubernetes Borg/Omega 历史主题 13: 优先级和抢占。某些工作比其他工作更重要和/或更紧急。Borg 将其表示为一个整数值:优先级。值越高意味着任务越重要,并且应该能够取代优先级较低的任务。
在为任务选择机器时,调度程序会忽略优先级较低的任务来确定任务是否/在何处适合,但会将必须抢占的任务数量作为选择最佳机器的排名函数的一部分来考虑。
中断预算从未添加到调度程序中,这本来就很难,但也存在对性能和优先级反转的担忧。高优先级任务可以指定它们等待低优先级任务正常终止的时间。
优先级用于确保生产/关键服务工作负载始终能够获得所需的资源。这对于使混合工作负载能够在同一集群中一起运行至关重要。批处理和实验性工作负载以较低优先级运行,基础架构以较高优先级运行。
有一段时间,用户尝试将他们的工作负载分散到多个优先级频段,以便对其他租户友好——在资源紧缺的情况下这是一种粗略的公平性。这导致了高优先级任务抢占低优先级任务的抢占级联。
批处理工作负载(其中许多是自动连续提交的)主要抢占其他批处理任务,导致大量工作丢失。因此,优先级被“折叠”成频段,以便将同一频段中的所有内容视为相同的优先级。
折叠减少了抢占,但需要其他机制来确保及时有效的调度。重新调度程序通过选择要取代的其他任务来确保挂起的生产优先级任务可以调度。它验证了两个任务都将被调度,以避免级联。
批处理任务组在有足够的资源可用于调度它们时排队并被准入集群。按优先级的资源配额防止了优先级随时间的膨胀。频段之间留有空间,以防需要新的频段——就像 BASIC 行号一样。
最终,几乎所有任务的优先级值都更改为通过一个艰苦的过程在其配置文件中与新方案合理化,跨越数千个作业。这重申了抽象操作意图的重要性。
Borg 的方法在 Borg 论文中有描述:https://ai.google/research/pubs/pub43438。K8s 设计方案在 https://github.com/kubernetes/design-proposals-archive/blob/main/scheduling/pod-preemption.md 和 https://github.com/kubernetes/design-proposals-archive/blob/main/scheduling/pod-priority-api.md。资源配额中的优先级:https://github.com/kubernetes/enhancements/blob/master/keps/sig-scheduling/20190409-resource-quota-ga.md。协同调度:https://github.com/kubernetes/enhancements/blob/master/keps/sig-scheduling/34-20180703-coscheduling.md。
Kubernetes 中的优先级相对较新,并且仍在发展中。例如,有一个开放的提案要添加抢占策略,https://github.com/kubernetes/enhancements/pull/1096,主要是为了避免抢占其他 pod。Borg 也有类似的机制。我将在介绍 QoS 时讨论原因。
在启动新调度的 pod 之前等待被抢占的 pod 正常终止会在设计中造成很大的复杂性。然后,调度程序需要对未来状态进行建模,并且某些控制器需要在启动新 pod 之前观察空间是否可用。
优先级和抢占的复杂性主要是推动 DaemonSet 控制器依赖默认调度程序将 pod 绑定到节点以及调度程序框架提案 https://github.com/kubernetes/enhancements/issues/624 的更改的原因,因此代码可以在自定义调度程序中重用。
接下来我将介绍服务质量 (QoS) 和超额订阅。随着时间的推移,Borg 中的优先级波段(特定的硬编码整数值)开始被用于确定 QoS 级别,具体原因我会在该主题中解释。
Kubernetes Borg/Omega 历史主题 14:计算服务质量 (QoS) 和超额订阅。它们是什么,为什么需要它们,以及 QoS 与优先级有何不同?关于最后一点,它区分了重要性和紧急性。如果每个主机系统只运行一个进程,或者所有进程都稳定地使用恒定数量的 CPU、内存和其他资源,那么 QoS 就无关紧要了。因为它们是可变的,为每个进程预留所需的最大容量会导致系统利用率低下。
超额订阅通过在系统中打包比峰值需求更多应用程序来缓解这种情况。这有点像银行:并非每个人都可以同时取款。接下来的问题是:当应用程序需要的资源超过它们所能获得的资源时会发生什么?
通过时分复用,可以交错多个 CPU 线程。它们可以被操作系统阻塞和排队,通常以上下文切换和等待几个时间片为代价。因此,可以打包到一台机器上的线程数量没有固定限制。CPU 是可压缩的。
另一方面,交换内存页面,即使是到本地 SSD,代价也非常高昂。这就是为什么托管需要亚秒级延迟响应的服务的系统要禁用交换的原因。内存被认为是不可压缩的资源。
为简单起见,我将忽略 CPU 和内存以外的资源。内核可以快速提供像 CPU 这样的可压缩资源,并且对被中断的线程影响很小,前提是它知道哪些线程紧急需要资源,哪些线程不需要。我们分别称之为延迟敏感型和延迟容忍型。
Borg 使用了一个名为 appclass 的显式属性来指示这一点,Borg 论文对此进行了描述:https://ai.google/research/pubs/pub43438。这在 LMCTFY 中转换为调度延迟:https://github.com/google/lmctfy/blob/master/include/lmctfy.proto#L142。
在 Kubernetes 中,它是根据资源请求和限制推断出来的。为了快速重新分配不可压缩资源,需要终止线程,这显然不是低影响的。(对于内存,在 Linux 中这是由 OOM killer 完成的。)这就是 Borg 使用优先级(生产优先级与非生产优先级)来做出内存超额订阅决策的原因。
该论文描述了 Borg 的资源回收方法:计算基于观察使用情况的预留,并将超额订阅的资源(延迟容忍型 CPU 和非生产内存)与预留进行比较,而保证的资源则使用限制。很复杂。垂直自动缩放 (VA) 增加了更多复杂性。VA 更改了限制,但留下了自己的填充,以便为反应时间和需求观察提供余量。添加了临时机制来禁用每种资源的限制执行,从而创建了类似于 K8s 中请求的概念。
在 K8s 中,我想要更简单的东西,可以直接表达对超额订阅和突发灵活性的渴望。讨论早在 issues.k8s.io/147 和 issues.k8s.io/168 中就开始了。我们确定的模型是通过查看限制和请求来确定的。
-
Request == Limit意味着保证资源(非超额订阅)。 -
Request < Limit意味着可突发的(超额订阅)。 - 零请求意味着尽力而为。Borg 使用预留来调度尽力而为的 pod,但在实践中无法做出吞吐量保证。
资源模型设计 (https://github.com/kubernetes/design-proposals-archive/blob/main/scheduling/resources.md) 和 QoS 建议 (https://github.com/kubernetes/design-proposals-archive/blob/main/node/resource-qos.md) 中描述了这一点,包括到 OOM 分数的映射。pod 资源设计 (https://github.com/kubernetes/community/blob/master/contributors/design-proposals/node/pod-resource-management.md) 中描述了到 cgroup cpu shares 的映射。
针对 Kubernetes 的 Vertical Pod Autoscaler 已经开始了一些工作:Vertical Pod Autoscaler design proposal。也有人提议实施超额订阅(#355 - Overcommitting resources)。至于水平扩展,资源监控基础设施是先决条件。
如果使用 ResourceQuota 和 LimitRange 管理集群级别的共享,则也可以在该级别进行超额订阅。最初的设计描述在 Admission Control: LimitRange 和 Admission Control: ResourceQuota 中,并在 Resource Quota Scope 中进行了改进。
好的,这个主题不太适合 Twitter 的格式。也许有一天我会抽出时间更详细地把它写出来。目前,我的时间就这么多,但欢迎提问。