PostgreSQL 是物联网数据及其经常需要的实时分析的绝佳选择。阅读我们如何构建和基准测试物联网流水线的文章。
译自 How to Build an IoT Pipeline for Real-Time Analytics in PostgreSQL,作者 Team Timescale。
物联网(IoT)通过连接设备和实现实时数据共享来改变行业。对于进行预测性维护、实现智慧城市和工业自动化的应用程序,有效管理物联网数据是确保平稳运行和及时决策的关键。
虽然许多组织选择使用不同的数据库来管理大量传感器数据并为其实时分析提供动力,但我们一直青睐PostgreSQL。借助TimescaleDB等扩展,它是PostgreSQL的底层,并为PostgreSQL添加了自动数据分区、始终最新的物化视图和强大的混合行列存储引擎,这个关系数据库成为了一个强大的物联网数据库。
通过这些补充,PostgreSQL 将您的关系数据和时间序列数据保存在一个地方,随着数据的不断增长,简化您的操作,并为实时分析提供速度和规模。
为了演示这一点,在本博文中,我们将探讨以下内容:
- 如何将PostgreSQL(使用TimescaleDB)与Kafka集成以实现高效的数据摄取。
- 我们将评估数据流水线的性能,测量从数据生成到存储的吞吐量和延迟。
- 最后,我们将在Grafana中设置监控查询并创建一个仪表板,以实现对物联网系统的实时监控,帮助您做出明智的数据驱动决策。
在我们深入教程之前,让我们花一点时间解释一些关键概念。
物联网数据挑战
物联网(IoT)是一个日常物体的网络——例如智能手表、冰箱、汽车和工业传感器——它们连接到互联网,可以收集、共享和处理数据。健身追踪器和智能手表等设备收集的物联网数据带来许多挑战。其高容量、高速度和多样性需要可扩展的存储和实时处理能力。此外,确保跨不同设备和系统的可靠性、安全性和数据集成增加了相当大的复杂性。为了应对这种复杂性,我们将使用增强的PostgreSQL(TimescaleDB 是PostgreSQL的底层)添加以下工具来构建物联网流水线并实现实时监控。
Kafka
Apache Kafka是一个开源的分布式事件流平台,用于构建实时数据流水线和流应用程序。它旨在实时处理大量数据,并在系统之间高效地传输数据。它允许您以容错和可扩展的方式发布、订阅、存储和处理记录(事件)流。Kafka广泛用于处理高吞吐量数据的行业,例如日志聚合、实时分析和流处理。
可以将Kafka想象成一个消息应用程序,其中消息或数据就像短信,而Kafka是管理这些消息的发送和接收的平台。
- 生产者就像通过应用程序发送消息(数据)的用户。这些可能是生成需要共享的数据的不同系统或应用程序。
- Kafka中的主题就像应用程序中的不同聊天组或线程。每个主题都是一个类别或一个通道,其中存储相关的消息。例如,一个线程可能是“订单”,另一个是“支付”,另一个是“传感器读数”。
- 消费者就像接收和读取聊天组中消息的用户或应用程序。这些可能是需要处理数据的其他应用程序或系统,例如分析工具、数据库或警报系统。
- Kafka中的队列或登录就像消息收件箱,消息在那里等待消费者读取。Kafka确保消息按正确的顺序传递,并且消费者可以随时访问它们,即使他们需要稍后处理消息。
Grafana
Grafana是一个用于监控和可视化数据的开源平台。它通过将数据转换为交互式和可自定义的仪表板来帮助您理解和分析数据。Grafana连接到各种数据源,例如数据库、云服务和应用程序日志,并允许您根据要监控的数据创建图、表和警报。
使用Grafana,您可以跟踪系统的运行状况,查看实时指标,并轻松发现问题。它广泛用于监控基础设施、应用程序性能和业务指标,在DevOps和IT运营中尤其受欢迎。Grafana还允许您设置警报,以便在满足某些条件时收到通知,这使其成为确保一切顺利运行的重要工具。
目标是将数据流式传输到 Kafka 主题,发送连续的记录(或事件)流。此数据可以表示各种类型的信息,例如实时生成的传感器读数、日志或事务数据。当数据流式传输到 Kafka 主题时,它会通过 Kafka Connect 同时被摄取到 PostgreSQL 的 Timescale 数据库中。
Kafka Connect 是一个框架,旨在将 Kafka 与不同的数据源和接收器(例如数据库或分析平台)集成。它简化了将数据发送到 TimescaleDB 的过程,无需自定义代码。Kafka Connect 自动从 Kafka 主题中提取数据并将其写入 TimescaleDB,确保数据已存储并可用于进一步处理或分析。
为了速度和方便,我们在成熟的 PostgreSQL 云平台 Timescale Cloud(30 天免费试用,无需信用卡) 中使用了 TimescaleDB,但您也可以始终使用开源扩展。安装方法。要将 Kafka 与 Timescale Cloud 集成,您可以查看另一篇优秀的博文,其中提供了详细说明 此处。
我使用了相同的示例将 Timescale Cloud 实例与 Kafka 集成。下面,我将概述我在集成过程中所做的更改。
获取最新的 Kafka 源代码:
sudo mkdir /usr/local/kafka
sudo chown -R $(whoami) /usr/local/kafka
wget https://downloads.apache.org/kafka/3.9.0/kafka_2.13-3.9.0.tgz && tar -xzf kafka_2.13-3.9.0.tgz -C /usr/local/kafka --strip-components=1并继续使用 此处 使用的脚本。
替换 timescale-sink.properties 文件中的以下行:
"camel.kamelet.postgresql-sink.query":"INSERT INTO accounts (name,city) VALUES (:#name,:#city)",使用此行:
"camel.kamelet.postgresql-sink.query":"INSERT INTO metrics (ts, sensor_id, value) VALUES (CAST(:#ts AS TIMESTAMPTZ), :#sensor_id, :#value)",此行告诉系统如何将数据从传感器保存到 metrics 表中。对于每条新记录,它都会保存以下内容:
- 时间 (
:ts) - 传感器的 ID (
:sensor_id) - 读数或测量值 (
:value)
:# 语法用于表示查询中的参数。这是一种告诉系统这些占位符的值将由执行查询的系统或应用程序动态提供的方式。
此外,请确保在以下属性中插入有效的凭据:
"camel.kamelet.postgresql-sink.databaseName":"tsdb",
"camel.kamelet.postgresql-sink.password":"password",
"camel.kamelet.postgresql-sink.serverName":"service_id.project_id.tsdb.cloud.timescale.com",
"camel.kamelet.postgresql-sink.serverPort":"5432",
"camel.kamelet.postgresql-sink.username":"tsdbadmin"在本博文中,我将使用 Timescale 提供的数据集,可在 此处 找到。
在此数据集中,我们有一个名为 metrics 的表。此表用于存储物联网 (IoT) 或监控系统中常用的时间序列数据。以下是其结构和它保存的数据类型的细分:
tsdb=> \d metrics
Table "public.metrics"
Column | Type | Collation | Nullable | Default
-----------+--------------------------+-----------+----------+---------
ts | timestamp with time zone | | |
sensor_id | integer | | |
value | numeric | | |列及其作用
-
ts(带时区的 timestamp):表示记录数据的确切时间。 -
sensor_id(integer):标识生成数据的传感器。 -
value(numeric):表示传感器测量的读数或测量值。
示例记录
- 时间戳 (ts):2023-05-31 21:48:41.234187+00
- 传感器 ID (sensor_id):21
- 值 (value):0.68
此记录表示在指定的时间戳处,传感器 21 记录了 0.68 的测量值。
tsdb=> select * from metrics limit 1;
ts | sensor_id | value
-------------------------------+-----------+-------
2023-05-31 21:48:41.234187+00 | 21 | 0.68
(1 row)下载并解压缩数据集。
wget https://assets.timescale.com/docs/downloads/metrics.csv.gz -O metrics.csv.gz将数据集转换为 JSON 格式,以便我们可以轻松地将此数据流式传输到 Kafka 主题。
echo "[" > metrics.json
awk -F',' '{print "{\"ts\": \""$1"\", \"sensor_id\": "$2", \"value\": "$3"},"}' metrics.csv | sed '$ s/,$//' >> metrics.json
echo "]" >> metrics.json数据集准备就绪后,将数据流式传输到 Kafka 主题。
要将数据流式传输到 Kafka 主题,我们将使用名为 kcat 的实用程序,以前称为 kafkacat。
kcat
实用程序是一个灵活的工具,可以根据其配置充当生产者(发送数据)或消费者(接收数据),并且可以轻松地在这些角色之间切换。
在我们的示例中,通过使用-p开关,我们将kcat配置为生产者,以将数据发送到使用-t开关指定的Kafka主题。一旦数据开始出现在Kafka主题中,就可以使用Kafka Connect之类的工具读取数据并将其流式传输到Timescale数据库中进行永久存储。
-b开关用于指定Kafka代理地址。Kafka代理就像一个服务器,用于存储和管理消息,这些消息保存在主题分区中。这些分区充当单独的存储区域,消息按发送顺序保存在其中。
当像示例中的kcat这样的生产者想要发送数据时,它们会将其发送到Kafka代理。代理将数据存储在不同的分区中。
然后,诸如Kafka Connect之类的消费者连接到Kafka代理,并从它们感兴趣的主题中获取数据。即使在系统故障的情况下,Kafka代理也能确保数据保持可访问和可用,从而保持系统的可靠性。
kcat -P -b localhost:9092 -t mytopic -l metrics.json
✨ 注意: Timescale实例和Kafka主机位于同一个AWS区域。
重要时间线
- 数据流式传输到Kafka主题开始于:2024年12月2日星期一 01:44:40 UTC
- 数据流式传输到Kafka主题结束于:2024年12月2日星期一 01:44:58 UTC
- 要摄取的总行数:2523726
- 数据摄取到Timescale实例开始于:2024年12月2日星期一 01:44:40 UTC
- 数据摄取到Timescale实例结束于:2024年12月2日星期一 02:15:38 UTC
- 将数据摄取到Timescale所需总时间:30分钟58秒。
统计数据
- 流式传输到Kafka主题的速度:总行数 / 总时间 = 2523726 / 18 = 140207 行/秒
- 数据摄取到Timescale实例的速度:摄取时间 / 总行数 = 2523726 / 1858 = ~1358 行/秒
- 将数据摄取到Timescale Cloud的总延迟:Timescale中摄取结束的时间 - Timescale中摄取开始的时间 = 2024年12月2日星期一 02:15:38 UTC — 2024年12月2日星期一 01:44:40 UTC = 1858 秒
要将Timescale与Grafana集成,我建议阅读以下博文,其中提供了集成过程的分步指南 此处。
完成Grafana集成后,下一步是创建您的第一个Grafana仪表板。为此,请按照以下步骤操作:
- 从左侧面板中选择“仪表板”。
- 然后,创建一个新的仪表板以进行可视化。
接下来,选择您的PostgreSQL数据源。
在此阶段,您的第一个仪表板几乎完成了。只需单击右上角的“返回仪表板”选项即可返回到它,您可以在其中开始创建自定义变量和查询以进行数据可视化。
成功创建了一个新的仪表板:
这是我们的初始数据在Grafana中的样子:
Grafana中的自定义变量是用户定义的占位符,允许根据用户输入(例如下拉选择)进行动态数据过滤和可视化。它们通过启用灵活的、可重用的查询和定制的见解来增强仪表板,而无需修改底层查询。
在物联网用例中,Grafana中的自定义变量可用于监控特定设备的位置。例如,一个变量可以通过选择安装在建筑物不同房间或楼层的设备来过滤温度数据。此过滤允许仪表板显示所选位置的实时温度趋势,从而实现有针对性的监控和分析。
要创建自定义变量,请导航到您的仪表板并从右上角选择“设置”菜单。
在“设置”中,单击“变量”选项卡,然后单击“添加变量”。
在下一个屏幕上,我们需要添加创建新变量所需的所有信息:
- 选择变量类型:选择变量类型,例如查询、自定义或常量,以定义变量值的生成方式。由于我们正在创建一个后端查询将填充的下拉列表,因此我选择了“查询”选项。
- 名称:为变量分配一个唯一的标识符,用于在查询或表达式中引用它。
- 标签:为变量提供一个显示名称,该名称显示在仪表板上以提高用户清晰度。
- 说明:添加对变量用途的简要说明,帮助仪表板用户了解其功能。
- 在仪表板上显示:决定如何在仪表板上显示此下拉列表,是应该带有标签以更好地理解还是不带标签。
- 数据源:指定变量从中检索其值的数 据源(例如,Prometheus、PostgreSQL)。
- 查询:根据所选数据源定义获取变量动态值的逻辑或查询。
您可以将其余选项保留为默认值。
底部,我们可以看到 Grafana 提供了它从数据库表成功获取的数据预览,这些数据将用于填充下拉菜单。
创建自定义变量后,下一步是设置仪表板监控查询以进行实时数据可视化。
创建自定义变量后,导航到仪表板,单击面板中的三个点,然后选择“编辑”。
在下一个屏幕上,选择“运行查询”旁边的“代码”选项。我们将使用代码模式而不是“查询构建器”模式,因为这允许您编写自己的查询来生成可视化效果。
检索特定传感器在特定日期内的值范围对于检测异常(例如异常高或低读数)、评估传感器在预期限值内的性能以及确保传感器正常运行非常有用。
查询
SELECT
MIN(value) AS min_value,
MAX(value) AS max_value
FROM metrics
WHERE
ts BETWEEN $__timeFrom() AND $__timeTo()
AND sensor_id = $sensor_id;理解查询
- 以上查询从
metrics表中检索指定时间范围和特定传感器 ID 内value列的最小值和最大值。 - 它动态地使用
$__timeFrom()、$__timeTo()和$sensor_id变量以无缝集成到 Grafana 仪表板中。
✨ 注意: 我们可以轻松地从左上角的下拉菜单中选择传感器 ID,并使用日期范围过滤器指定所需的日期范围。仪表板将自动更新以显示所选传感器和所需日期范围的最小值和最大值。
结果
该图表显示传感器 ID 23 在 2023 年 5 月 29 日至 2023 年 5 月 31 日的日期范围内,最小值为 0.265,最大值为 0.999。
这是将高频数据下采样到固定时间间隔的理想用例,从而简化趋势分析和数据可视化。它确保统一的时间段,防止图表因过多的数据点而变得混乱,并保留关键读数。
查询
SELECT
series.time AS time,
m.value AS value
FROM
generate_series(
$__timeFrom()::timestamp,
$__timeTo()::timestamp,
'10 seconds'::interval
) AS series(time)
LEFT JOIN LATERAL (
SELECT value
FROM metrics
WHERE sensor_id = $sensor_id
AND ts >= series.time
AND ts < series.time + interval '10 seconds'
ORDER BY ts
LIMIT 1
) m ON true
ORDER BY series.time;理解查询
- 该查询创建一系列时间间隔,从所选日期范围的开始到结束(
$__timeFrom()to$__timeTo()),步长为 10 秒。 - 对于每个时间间隔,它从
metrics表中检索所选sensor_id的相应值,确保数据的 timestamps (ts) 位于该特定间隔内。为每个间隔选择最接近的匹配项。
结果
上图显示了传感器 ID 4 从 2023 年 5 月 29 日 06:07:48 到 2023 年 5 月 29 日 06:40:00 的读数。该图表显示了五分钟间隔的数据,我们观察到从 06:10 到 06:15 的读数一致,然后从 06:15 到 06:20 出现峰值。读数再次稳定,在 06:30 和 06:34 出现另外两个峰值,然后恢复正常。这些峰值表明传感器在此期间经历了三个不同的意外事件。
获取传感器的平均数据或值有助于了解其全天或数月的整体性能或行为。它对于监控应该保持特定平均范围的传感器特别有用,允许您评估数据的总体趋势。
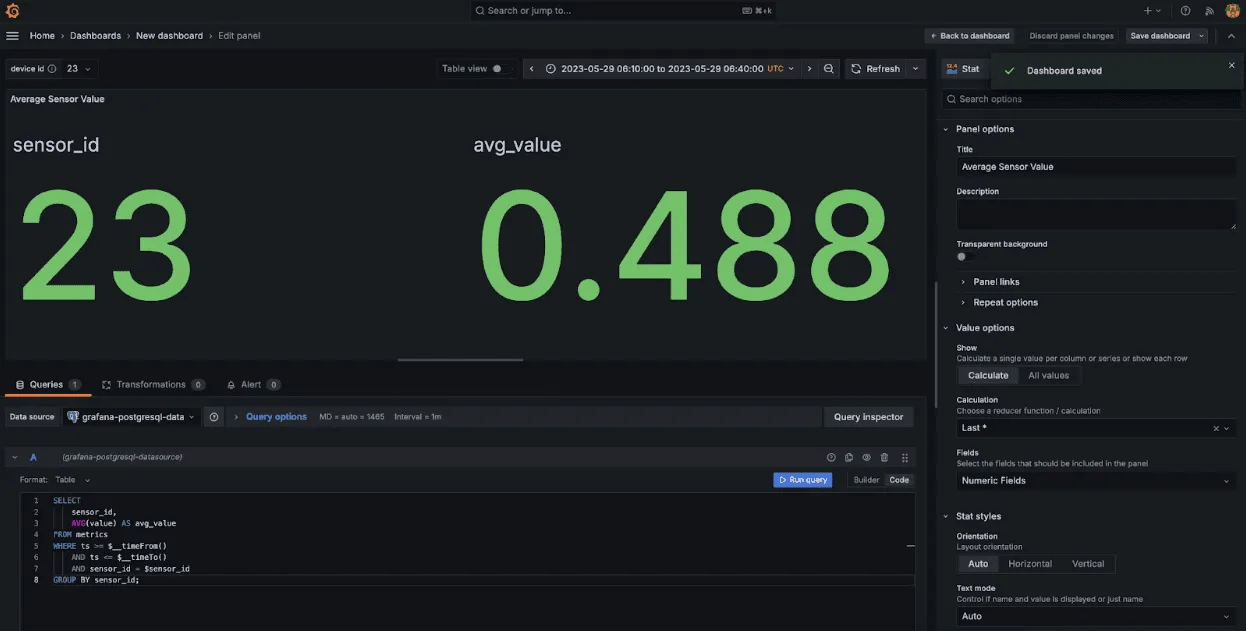
查询
SELECT
sensor_id,
AVG(value) AS avg_value
FROM metrics
WHERE ts >= $__timeFrom()
AND ts <= $__timeTo()
AND sensor_id = $sensor_id
GROUP BY sensor_id;理解查询
- 此查询计算给定
sensor_id在由 Grafana 的$__timeFrom()和$__timeTo()变量定义的时间范围内value列的平均值 (AVG)。 - 它按
sensor_id分组结果,并在所选时间范围内检索该特定传感器的平均读数。
结果
上图显示了所选时间范围内(从 2023 年 5 月 29 日 06:10:00 到 2023 年 5 月 29 日 06:40:00)传感器 ID 23 的平均读数。
通过并排比较传感器读数,您可以识别两个传感器数据之间可能存在的相关性、趋势或问题,这对于诊断问题或确保设备之间的数据一致性至关重要。
查询
SELECT
a.ts AS time,SELECT
a.value AS sensor_a_value,
b.value AS sensor_b_value
FROM metrics a
JOIN metrics b ON a.ts = b.ts
WHERE
a.sensor_id = $sensor_a
AND b.sensor_id = $sensor_b
AND a.ts >= $__timeFrom()
AND a.ts <= $__timeTo()
ORDER BY
a.ts;理解查询
- 首先,我们选择时间戳 (a.ts) 作为时间,以及来自
sensor_a和sensor_b的值。连接允许比较同一时间戳 (a.ts = b.ts) 中来自两个不同传感器的數據。 - 最后,我们使用 Grafana 变量过滤选定的
sensor_a和sensor_bID 的数据,将数据限制在指定的时间范围内,并按时间戳排序结果以按时间顺序显示值。
✨ 注意: 为此查询创建了一个新的仪表板,我们还创建了两个自定义变量来比较传感器 A 和传感器 B。
结果
上图比较了指定时间间隔内(2023-05-29 06:00:00 至 2023-05-29 07:30:00)的两个传感器,传感器 ID 1 和传感器 ID 11。图表以五分钟的间隔显示了这两个传感器的值变化。从数据可以看出,传感器 1 保持一致且稳定的读数,而传感器 11 在同一时间段内出现了一些峰值。这些峰值表明传感器 11 可能需要进一步关注或调查。
以下是仪表板的最终外观:
一个用于比较传感器的单独仪表板:
仪表板的最终设计确保所有关键信息都集中在一个地方。这种集中化意味着您不必转到不同的部分或工具来查找所需的统计数据。通过井然有序地组织所有内容,用户可以轻松监控关键指标、发现趋势并快速做出决策,这使得这个基于 PostgreSQL 的、由 Kafka 和 Grafana 驱动的物联网流水线成为预测性维护和警报的理想解决方案。实时分析易于获取,从而提供及时的见解并促使快速行动。
虽然在许多行业中很常见,但这些用例与通用分析相比,提出了不同的挑战。
与您可以等待数据并执行批量插入的更通用的分析用例不同,实时分析需要高数据摄取速度以及能够立即提供数据以进行查询和分析的能力。
TimescaleDB 凭借其混合行列存储引擎在这两方面都表现出色。它可以以最有效的格式摄取和存储数据,使您可以透明地跨行存储和列存储查询它。此转换在后台自动发生,无需额外开销。
在这篇博文中,我们了解了如何轻松地将 Kafka 和 Kafka Connect 连接起来,将物联网数据流式传输到基于 PostgreSQL 的 TimescaleDB 实例中,并驱动实时分析仪表板。TimescaleDB 非常适合处理大量物联网数据,这要归功于其强大的时间序列功能,确保它既可扩展又高效。
一旦您的流水线与 Timescale 和 Kafka 顺利运行,接下来我们应该关注的是监控,因此 Grafana 是一个很好的工具,可以实时可视化您的数据,帮助您跟踪性能并做出更好、更数据驱动的决策。
如果您的用例需要实时洞察,例如Trebellar 的,请尝试使用 TimescaleDB。您可以自行托管它或免费试用我们的托管 PostgreSQL 选项 Timescale Cloud。这将使您可以专注于您的应用程序,而不是您的数据库。