探索带过滤器的语义搜索,并学习如何使用 pgvector 和 Python 实现它。
译自 What Is Semantic Search With Filters and How to Implement It With Pgvector and Python,作者 Team Timescale。
如果您正在使用搜索驱动的应用程序,在大量非结构化数据中找到所需内容可能会感觉像大海捞针。传统上,使用BM25等算法的关键词搜索一直是首选解决方案,但说实话——它常常达不到目标。为什么?因为它专注于匹配精确的词语,而不是理解其背后的实际上下文或含义。这就是语义搜索发挥作用的地方。语义搜索通过使用向量嵌入来捕捉词语的含义和上下文,从而提供更智能、更相关的结果。
更棒的是:当您向语义搜索添加过滤器时,您可以微调这些结果。想要按位置、类别或自定义字段缩小范围?很容易。过滤器允许您对数据进行切片和切块,以精确找到您要查找的内容。
在本指南中,我们将向您展示如何通过在PostgreSQL数据库中设置带有过滤器的语义搜索来增强您的搜索功能。我们将使用诸如pgvector(用于存储和查询向量嵌入)之类的工具,
让我们开始吧!
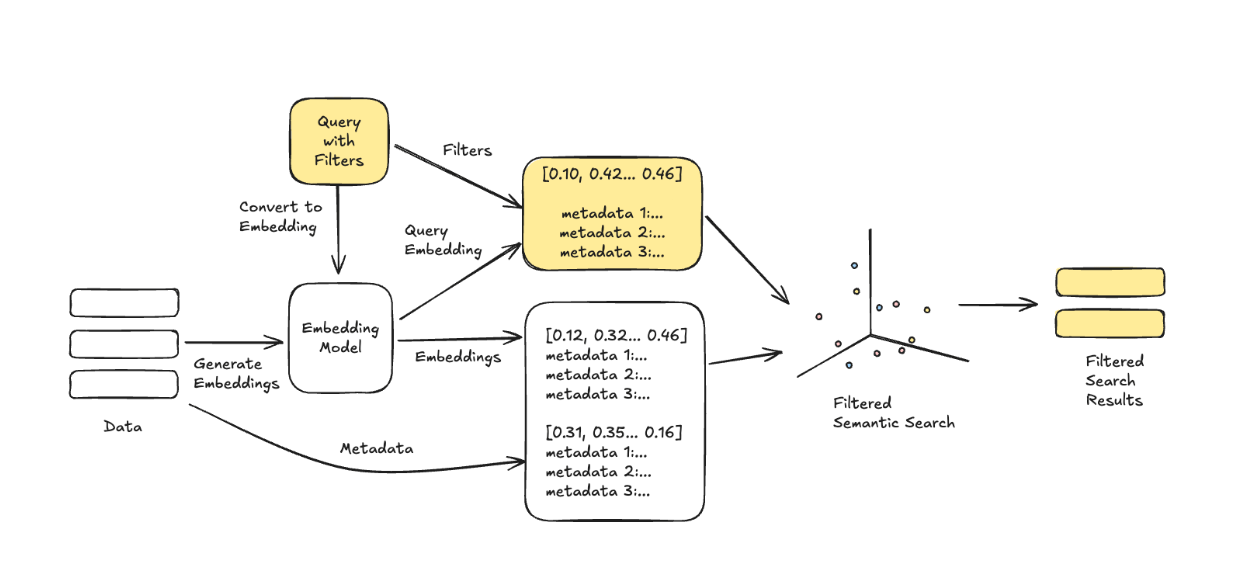
语义搜索允许您去除噪音,超越基本的关键词匹配。它不仅仅查找精确的词语匹配,而是捕捉查询背后的意图和上下文。如何做到?通过使用向量嵌入—高维数值表示,将数据的本质打包成机器可以理解的格式。
它是这样工作的:您的数据被转换为向量表示。如果您正在处理文档,它通常会被分解成更小的块,每个块都被映射为高维向量空间中的一个唯一点。在这个空间中,具有相似含义的数据彼此更靠近。这意味着当您搜索时,系统会根据含义检索结果,而不仅仅是您键入的词语。
语义搜索使用余弦相似度或欧几里得距离等相似性度量来确定这些向量点有多接近。这些度量计算查询向量与潜在匹配之间的“距离”,帮助您找到最相关的结果。
为了提高速度,尤其是在大型数据集的情况下,近似最近邻搜索 (ANN) 或分层可导航小世界 (HNSW) 等算法发挥了作用。它们使查找相似向量变得快速有效,使您的搜索保持相关性和闪电般的速度。

无过滤器的语义搜索
在搜索应用程序中,过滤器是使结果更相关和更有用的武器。语义搜索在基于含义查找结果方面做得很好,但是当您添加过滤器时,您可以真正专注于重要内容。过滤器允许您根据特定条件(例如位置、类别、日期或自定义字段)缩小结果范围,以便用户获得他们想要的确切内容。
假设您正在构建产品搜索。语义搜索可能会调出与用户描述匹配的项目,但过滤器可以细化这些结果,仅显示某些品牌、价格范围或库存项目。语理解和基于属性的过滤相结合,有助于您创建高度定向且可操作的搜索算法。
从技术角度来看,过滤器通过限制搜索发生的向量空间来工作。算法不是扫描所有内容,而是只查看满足您条件的向量。结果?搜索速度更快,更相关。

语义搜索带筛选
当您实现带有过滤器的语义搜索时,您可能会遇到处理大型数据集或复杂过滤条件的情况。选择正确的索引方法是保持搜索速度和准确性的关键。您会遇到两个突出的选项:层次可导航小世界(HNSW)算法是一种流行的索引算法,还有 pgvector 中的 StreamingDiskANN。让我们来分析一下,以便你可以决定哪一个更适合你过滤后的语义搜索需求。
HNSW indexing
HNSW 是一种基于图的算法,旨在进行高效的近似最近邻搜索。它的工作原理是构建一个多层图,其中每个节点代表一个数据点,边根据节点的邻近性连接节点。这种结构允许快速遍历和检索相似的向量。
优势:
- 高召回率:HNSW 提供高召回率,确保检索最相关的向量。
- 快速查询时间:图结构能够进行快速搜索,这对于实时应用程序非常有益。
局限性:
- 内存密集型:HNSW 需要大量的内存存储,这对于大型数据集来说可能是一个限制。
- 过滤搜索挑战:应用基于属性的过滤器效率可能较低,因为可能需要遍历整个图来强制执行过滤器,从而导致查询时间增加。
要了解有关HNSW 算法的更多信息,请查看我们的深入探讨。
在 pgvector 中的 StreamingDiskANN
StreamingDiskANN 是 pgvectorscale 中引入的一种先进的索引方法。它解决了 HNSW 的一些关键限制,并且速度显著更快。
在过滤搜索方面优于 HNSW 的优势:
- 高效过滤:StreamingDiskANN 支持流式过滤,即使在相似性搜索过程中应用了二级过滤器,也能实现准确检索。
- 基于磁盘的存储:与内存密集型的 HNSW 不同,StreamingDiskANN 将部分索引存储在磁盘上。这减少了对 RAM 的依赖,并且随着向量工作负载的增长,运行和扩展起来更具成本效益。
换句话说,HNSW能够提供高召回率和快速查询,但它占用大量内存,并且在过滤搜索方面表现不佳。而StreamingDiskANN则提供了一种可扩展、成本效益高的解决方案,具有增强的过滤功能,非常适合需要复杂过滤语义搜索的大型数据集。你可以在这篇博客文章中了解更多关于StreamingDiskANN和pgvectorscale的功能。
在 Stack Overflow 2024 年开发者调查中,PostgreSQL 连续第二年被评为最受欢迎的数据库。DB - Engines 也将 PostgreSQL 评为年度数据库。当与 pgvector、pgai 和 pgvectorscale 等开源扩展一起使用时,PostgreSQL 在性能和简洁性方面轻松超越其他向量搜索引擎。在构建 AI 解决方案时,PostgreSQL 就足够了。
本教程将演示如何使用 PostgreSQL 和 Python 轻松构建带过滤器的语义搜索。让我们开始吧。
步骤1:安装带有 pgai、pgvector 和 pgvectorscale 的 PostgreSQL
首先,你需要一个安装好的 PostgreSQL,并且安装了必要的扩展。你可以手动安装它们,或者使用预构建的 Docker 容器。另外,你也可以选择 Timescale Cloud,它提供了带有预安装的 pgai、pgvector 和 pgvectorscale 的免费 PostgreSQL 实例。在这里,我们将使用 Docker 容器。
运行以下命令来拉取 TimescaleDB 镜像:
docker pull timescale/timescaledb-ha:pg16此镜像在默认的 PostgreSQL 数据库中预装了扩展。现在,运行该容器:
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=password timescale/timescaledb-ha:pg16您现在可以使用以下命令连接到您的 PostgreSQL:
psql -d "postgres://<username>:<password>@<host>:<port>/<database-name>"默认的用户名和数据库名称都是postgres。使用运行Docker容器时设置的密码。
现在,启用扩展:
CREATE EXTENSION IF NOT EXISTS ai CASCADE;
CREATE EXTENSION IF NOT EXISTS vectorscale CASCADE;CASCADE 选项会自动安装 pgvector 和 plpython3u 扩展。您可以验证这些扩展是否已启用:
\dx
CASCADE 选项会自动安装 pgvector 和 plpython3u 扩展。您可以验证这些扩展是否已启用:
postgres=# \dx
List of installed extensions
Name | Version | Schema | Description
---------------------+---------+------------+---------------------------------------------------------------------------------------
ai | 0.6.0 | ai | helper functions for ai workflows
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
plpython3u | 1.0 | pg_catalog | PL/Python3U untrusted procedural language
timescaledb | 2.17.2 | public | Enables scalable inserts and complex queries for time-series data (Community Edition)
timescaledb_toolkit | 1.19.0 | public | Library of analytical hyperfunctions, time-series pipelining, and other SQL utilities
vector | 0.8.0 | public | vector data type and ivfflat and hnsw access methods
vectorscale | 0.5.1 | public | pgvectorscale: Advanced indexing for vector data
(7 rows)
步骤2:验证OpenAI功能是否可访问
本教程使用 OpenAI 的 GPT 4o 模型作为 LLM。不过,你也可以选择 Cohere、Anthropic 的模型,或者使用 Ollama 部署的任何 LLM。
前往 platform.openai.com 获取你的 OpenAI API 密钥。拿到之后,创建一个 .env 文件,并将 API 密钥设置为环境变量。同时,添加数据库的连接字符串。
OPENAI_API_KEY="your_secret_openai_api_key"
DB_URL="postgres://postgres:password@127.0.0.1:5432/postgres"
创建一个Python虚拟环境,安装JupyterLab,并启动它。
$ pip install jupyterlab
$ jupyter lab你现在可以安装所需的库了:
!pip install psycopg2-binary
!pip install python-dotenv由于我们使用的是基于本地 Docker 的安装,我们还应该安装 pgai Vectorizer Python 包来自动化嵌入生成。如果您使用的是 Timescale Cloud 上的 PostgreSQL 集群,则无需安装此包,因为向量化器会自动创建并每五分钟运行一次。
!pip install pgai你现在应该运行矢量化后台工作程序,以便它稍后能够生成嵌入向量。你可以这样操作:
$ pgai vectorizer worker -d "postgres://postgres:password@127.0.0.1:5432/postgres"现在,让我们检查一下你是否能够成功连接到OpenAI并检索出所有可用模型的列表:
import os
from dotenv import load_dotenv
load_dotenv()
OPENAI_API_KEY = os.environ["OPENAI_API_KEY"]
DB_URL = os.environ["DB_URL"]
import psycopg2
with psycopg2.connect(DB_URL) as conn:
with conn.cursor() as cur:
# pass the API key as a parameter to the query. don't use string manipulationscur.execute("SELECT * FROM ai.openai_list_models(api_key=>%s) ORDER BY created DESC", (OPENAI_API_KEY,))
records = cur.fetchall()
print(records)如果您的设置正常工作,这将返回可用 OpenAI 模型的列表。
步骤3:加载数据
本教程将使用一个酒店评论数据集。每条评论包括评论全文、物业类型、位置、评论者位置、评分、卧室和浴室数量以及评论日期。有些评论是积极的,而另一些是消极的。
以下是我们的数据集示例。为简洁起见,我们只显示了七行:
[
{
"review_text": "The hotel was a haven of comfort and luxury. Impeccably clean rooms, friendly staff, and a prime location made our stay unforgettable. The delicious breakfast spread was an added bonus. Highly recommend this gem!",
"date": "2025-01-01",
"category": "hotels",
"name": "Yates, Gonzalez and Mack",
"rating_score": 5,
"location": {
"city": "Cooktown",
"country": "Canada"
},
"customer_location": {
"city": "South Staceyburgh",
"country": "Bahamas"
},
"bedrooms": 3,
"bathrooms": 1
},
{
"review_text": "This hotel is exceptional! The rooms are pristine and beautifully decorated. Staff are incredibly welcoming and attentive. The amenities, including the luxurious pool and spa, are top-notch. An unforgettable stay with stunning views and a delightful atmosphere. Highly recommend!",
"date": "2025-01-02",
"category": "hotels",
"name": "Hill-Hatfield",
"rating_score": 3,
"location": {
"city": "Rachelland",
"country": "Benin"
},
"customer_location": {
"city": "Dorothyview",
"country": "Cayman Islands"
},
"bedrooms": 3,
"bathrooms": 2
},
{
"review_text": "The room was filthy, with stained sheets and a persistently foul odor. Staff was rude and unresponsive to complaints. The so-called \"breakfast\" was inedible. Worst hotel experience I've ever had. Not recommended at all.",
"date": "2025-01-06",
"category": "hotels",
"name": "Rocha, Robinson and Ellis",
"rating_score": 1,
"location": {
"city": "Holmesstad",
"country": "Benin"
},
"customer_location": {
"city": "New Joshua",
"country": "Senegal"
},
"bedrooms": 2,
"bathrooms": 3
},
{
"review_text": "The hostel offers a convenient location with friendly staff and basic amenities. Rooms are clean but can be cramped. Communal areas are lively, though sometimes noisy. Good for budget travelers seeking a social atmosphere.",
"date": "2025-01-11",
"category": "hostels",
"name": "Lane-Kidd",
"rating_score": 2,
"location": {
"city": "North Sarahton",
"country": "Portugal"
},
"customer_location": {
"city": "Port Manuelburgh",
"country": "Philippines"
},
"bedrooms": 5,
"bathrooms": 3
},
{
"review_text": "The hotel was a nightmare—musty room, stained sheets, and a bathroom that screamed for cleaning. Unhelpful staff and paper-thin walls made sleep impossible. The only thing five-star about this place is the regret. Don't stay here.",
"date": "2025-01-11",
"category": "hotels",
"name": "Love Group",
"rating_score": 5,
"location": {
"city": "Mackville",
"country": "New Zealand"
},
"customer_location": {
"city": "East Cole",
"country": "Pitcairn Islands"
},
"bedrooms": 5,
"bathrooms": 2
},
{
"review_text": "These apartments are fantastic! The spacious, modern design and top-notch amenities create a luxurious living experience. The friendly staff and well-maintained facilities make it a pleasure to call this place home. Highly recommended!",
"date": "2025-01-05",
"category": "apartments",
"name": "Jordan LLC",
"rating_score": 1,
"location": {
"city": "Lake Meganview",
"country": "Nepal"
},
"customer_location": {
"city": "Williebury",
"country": "Mexico"
},
"bedrooms": 5,
"bathrooms": 2
},
{
"review_text": "I had an amazing stay at the downtown hostel! The staff was incredibly friendly and helpful, the rooms were clean and cozy, and the communal areas were perfect for meeting fellow travelers. Highly recommend!",
"date": "2025-01-08",
"category": "hostels",
"name": "Torres-Branch",
"rating_score": 2,
"location": {
"city": "Davidsonchester",
"country": "Romania"
},
"customer_location": {
"city": "Wallaceberg",
"country": "Chile"
},
"bedrooms": 5,
"bathrooms": 2
}
]让我们首先创建一个名为hotel_reviews的表:
conn = psycopg2.connect(DB_URL)
conn.autocommit = True
with conn.cursor() as cur:
cur.execute('''
CREATE TABLE IF NOT EXISTS hotel_reviews (
id BIGINT PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY,
review_text TEXT,
embedding vector(1536),
category TEXT,
rating_score INTEGER,
location_city TEXT,
location_country TEXT,
customer_city TEXT,
customer_country TEXT,
name TEXT,
date DATE,
bedrooms INTEGER,
bathrooms INTEGER
);
''')每个表列对应于我们评论数据中的一个属性。现在,让我们插入我们的数据集并在过程中创建嵌入。方法如下:
with conn.cursor() as cur:
for review in hotel_reviews:
print("Inserting review:")
print(review)
cur.execute('''
INSERT INTO hotel_reviews (
review_text, category, rating_score,
location_city, location_country,
customer_city, customer_country, name,
date, bedrooms, bathrooms
)
SELECT
%s,
%s,
%s,
%s,
%s,
%s,
%s,
%s,
%s,
%s,
%s
''', (
review['review_text'],
review['category'],
review['rating_score'],
review['location']['city'],
review['location']['country'],
review['customer_location']['city'],
review['customer_location']['country'],
review['name'],
review['date'],
review['bedrooms'],
review['bathrooms']
))步骤4:使用pgai向量化器自动生成嵌入向量
Pgai Vectorizer 可以在 PostgreSQL 内部直接自动化创建和维护向量嵌入。它允许你指定用于生成嵌入的文本列,自动创建和维护可搜索的嵌入表,并同步嵌入与源数据。
以下是你可以如何设置它来自动生成嵌入的方法。
with conn.cursor() as cur:
cur.execute('''
SELECT ai.create_vectorizer(
'Reviews'::regclass,
destination => 'hotel_reviews_embeddings',
embedding => ai.embedding_openai('text-embedding-3-small', 1536),
chunking => ai.chunking_recursive_character_text_splitter('review_text'),
formatting => ai.formatting_python_template('$chunk - Category: $category'),
indexing => ai.indexing_hsnw(min_rows => 50000, opclass => 'vector_l2_ops')
);
''')向量化器使用 OpenAI 的模型自动从review_text列生成嵌入。嵌入存储在单独的表中(hotel_reviews_embeddings_store),并自动创建一个视图(hotel_reviews_embeddings)以将原始数据与其嵌入连接起来,从而方便查询和使用嵌入数据。
在上面的代码中,我们还创建了一个分层可导航小世界 (HSNW) 索引以加快相似性搜索速度。对于更大的数据集,StreamingDiskANN 是推荐的方法。创建向量化器时,您可以按以下方式设置:
with conn.cursor() as cur:
cur.execute('''
SELECT ai.create_vectorizer(
'Reviews'::regclass,
destination => 'hotel_reviews_embeddings',
embedding => ai.embedding_openai('text-embedding-3-small', 1536),
chunking => ai.chunking_recursive_character_text_splitter('review_text'),
formatting => ai.formatting_python_template('$chunk - Category: $category'),
indexing => ai.indexing_diskann(min_rows => 100000, storage_layout => 'memory_optimized')
);
''')步骤5:使用过滤器进行语义搜索
现在,我们将创建一个函数来执行带有过滤器的语义搜索。以下是函数的代码:
def semantic_search(query_text, category=None, min_rating=None, max_rating=None,
min_bedrooms=None, max_bedrooms=None,
min_bathrooms=None, max_bathrooms=None,
location_city=None, location_country=None, limit=5):
"""
Perform semantic search with optional filters on ratings, rooms, and location
"""
with conn.cursor() as cur:
# Build the SQL query with filters
sql = '''
WITH query_embedding AS (
SELECT ai.openai_embed('text-embedding-3-small', %s, api_key=>%s) as embedding
)
SELECT review_text, category, rating_score,
location_city, location_country,
bedrooms, bathrooms,
embedding <=> (SELECT embedding FROM query_embedding) as distance
FROM hotel_reviews
WHERE 1=1
'''
params = [query_text, OPENAI_API_KEY]
if category:
sql += ' AND category = %s'
params.append(category)
if min_rating:
sql += ' AND rating_score >= %s'
params.append(min_rating)
if max_rating:
sql += ' AND rating_score <= %s'
params.append(max_rating)
if min_bedrooms:
sql += ' AND bedrooms >= %s'
params.append(min_bedrooms)
if max_bedrooms:
sql += ' AND bedrooms <= %s'
params.append(max_bedrooms)
if min_bathrooms:
sql += ' AND bathrooms >= %s'
params.append(min_bathrooms)
if max_bathrooms:
sql += ' AND bathrooms <= %s'
params.append(max_bathrooms)
if location_city:
sql += ' AND location_city = %s'
params.append(location_city)
if location_country:
sql += ' AND location_country = %s'
params.append(location_country)
sql += ' ORDER BY embedding <-> (SELECT embedding FROM query_embedding) LIMIT %s'
params.append(limit)
cur.execute(sql, params)
results = cur.fetchall()
return [
{
'review_text': r[0],
'category': r[1],
'rating_score': r[2],
'location_city': r[3],
'location_country': r[4],
'bedrooms': r[5],
'bathrooms': r[6],
'similarity_score': 1 - r[7] # Convert distance to similarity
}
for r in results
]在 semantic_search 函数中,query_text 通过 ai.openai_embed 程序转换为嵌入向量。然后应用过滤器来在语义搜索过程中细化结果。该函数还会返回相似度得分,该得分是通过余弦距离计算得出的。
我们现在可以执行带有过滤器的语义搜索了。以下是如何使用示例查询调用该函数的方法:
results = semantic_search(
"private pool",
category="villas",
limit=3
)
for i, result in enumerate(results, 1):
print(f"\nResult {i}:")
print(f"Review: {result['review_text']}")
print(f"Category: {result['category']}")
print(f"Rating: {result['rating_score']}")
print(f"Location: {result['location_city']}, {result['location_country']}")
print(f"Rooms: {result['bedrooms']} bedrooms, {result['bathrooms']} bathrooms")
print(f"Similarity Score: {result['similarity_score']:.2f}")这将返回如下所示的结果:
Result 1:
Review: This villa is a stunning oasis of tranquility, offering breathtaking views, elegant interiors, and a serene private pool. It's the perfect blend of luxury and comfort, providing an unforgettable escape filled with beauty and relaxation.
Category: villas
Rating: 4
Location: New Craig, Christmas Island
Rooms: 3 bedrooms, 1 bathrooms
Similarity Score: 0.39
Result 2:
Review: This villa is a paradise! Stunning views, luxurious amenities, and impeccable service. The infinity pool and lush gardens create a serene escape. Perfect for relaxation and rejuvenation. A true gem for anyone seeking an unforgettable retreat!
Category: villas
Rating: 2
Location: Port Ashleyhaven, Reunion
Rooms: 3 bedrooms, 3 bathrooms
Similarity Score: 0.35
Result 3:
Review: The villas exude luxury and tranquility, with stunning ocean views, plush interiors, and a private infinity pool. Impeccable service and lush gardens make this a dreamy getaway. Truly a paradise retreat!
Category: villas
Rating: 5
Location: Hoffmanfort, South Africa
Rooms: 5 bedrooms, 3 bathrooms
Similarity Score: 0.35
就是这样!我们已经成功地在 PostgreSQL 中使用 pgai 和 pgvector 扩展实现了带有过滤器的语义搜索。此外,我们还利用 pgvectorscale 的 StreamingDiskANN 索引来实现高性能的嵌入式搜索和存储效率。
我们刚刚构建了一个功能强大的带有过滤功能的 PostgreSQL 语义搜索引擎,它结合了 pgai 和 pgvector 的简单性和 pgvectorscale 的性能提升。
立即开始构建您自己的带过滤器的语义搜索!有关 Timescale 的 AI 堆栈 的更多信息,请浏览
以下是一些相关的博文和指南,可帮助您扩展知识并了解有关语义搜索及其他内容的更多信息:
- Semantic Search With OpenAI and PostgreSQL in 10 Minutes
- Combining Semantic Search and Full-Text Search in PostgreSQL (With Cohere, Pgvector, and Pgai)
- Implementing Filtered Semantic Search Using Pgvector and JavaScript
- PostgreSQL Hybrid Search Using Pgvector and Cohere
- How We Made PostgreSQL as Fast as Pinecone for Vector Data