
我们对 DeepSeek 的模型进行了正面测试,以对抗行业领导者,从而解决现实世界中的 Kubernetes 挑战。
译自 The AI Model Showdown - LLaMA 3.3-70B vs. Claude 3.5 Sonnet v2 vs. DeepSeek-R1/V3,作者 Itiel Shwartz; CTO; Co-Founder。
在 DeepSeek 进入 AI 领域并引起广泛关注之后,它有能力在一夜之间让 AI 领域的领头羊(英伟达)的股票价值暴跌。我们 Komodor 希望对其进行严格的评估。我们对 DeepSeek 的模型进行了正面测试,以解决实际的 Kubernetes 挑战,并与行业领导者进行了比较。
结果非常引人入胜,并且具有启发性,特别是关于 DeepSeek 在生产环境中的当前能力。
简单介绍一下实验的背景。对于那些不熟悉的人来说,我们在 Komodor 一直试图解决的领域之一是真正实用的 AIOps,它可以解决实际问题,而不仅仅是炒作。我已经在 LinkedIn 和我们的博客上对此进行了广泛的撰写。
我们投入了大量的时间进行研究和开发,以构建一个 AI 故障排除代理,特别关注简化根本原因分析。我们发现,AI 代理的版本越来越复杂,能够以更大的细微差别进行推理,并提供真正惊人的结果。
我们在 Komodor 实验室环境中的评估涵盖了四个关键维度:
- 生产场景:我们的基准测试包括几个不同的 Kubernetes 事件,范围从基本的 pod 故障到复杂的跨服务问题。
- 系统框架:每个 AI 模型都面临相同的场景,测量:
- 识别问题的时间
- 根本原因准确性
- 修复质量
- 复杂故障处理
- 数据集成:AI 代理利用复杂的 RAG 系统访问:
- 实时 Kubernetes 集群数据
- Komodor 的平台见解
- 云基础设施状态
- 结构化提示:一种上下文感知的指令框架,可根据环境、事件类型和可用数据进行调整,从而确保有条不紊的故障排除和标准化输出
评估的模型
为了评估 AI 辅助 Kubernetes 故障排除的有效性,我们选择了来自不同生态系统的模型:
- Claude 3.5 Sonnet v2(via AWS Bedrock)
- LLaMA 3.3-70B(via AWS Bedrock)
- DeepSeek-R1(via Hugging Face)
- DeepSeek-V3(via Hugging Face)
测试场景最终导致 DeepSeek 崩溃,因此它被排除在更高级的测试场景之外。
测试用例:Traefik 部署中的无效 ConfigMap
在此场景中,由于依赖的 ConfigMap 中的 YAML 缩进不正确,服务 (Traefik) 无法启动。
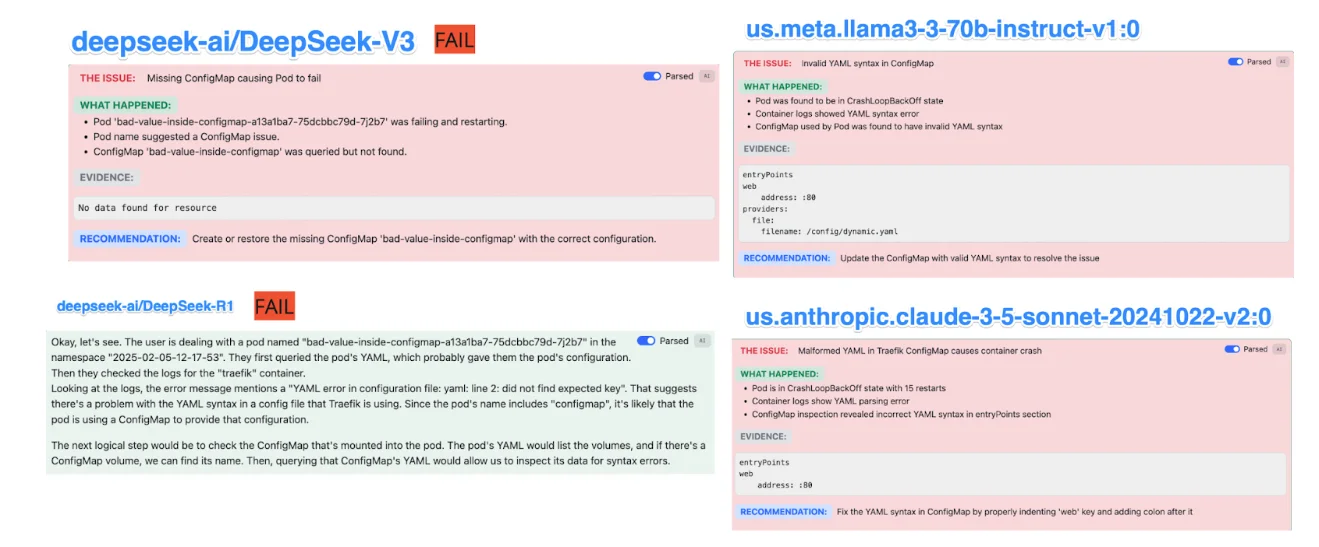
每个模型的观察结果:
- Claude 3.5 和 LLaMA 3.3-70B 快速识别出根本原因:由于 YAML 语法错误导致的 ConfigMap 格式错误,并查明了错误的键缩进。
- DeepSeek-V3 完全失败,误诊了问题。
- DeepSeek-R1 无法完成分析,使用户无法获得可操作的见解。
您可以在场景 #1 的图像中看到 DeepSeek 完全失败,而 Claude 和 LLaMA 正确诊断了 YAML 问题。无论如何,Claude 给出了更好的建议。
结论: YAML 验证对于 Kubernetes 调试至关重要,Claude 和 LLaMA 都表现出卓越的理解。
测试用例:Pod 正在运行,但应用程序失败
在此测试中,服务已正确部署,但由于缺少请求参数,应用程序不断抛出 HTTP 400 错误。
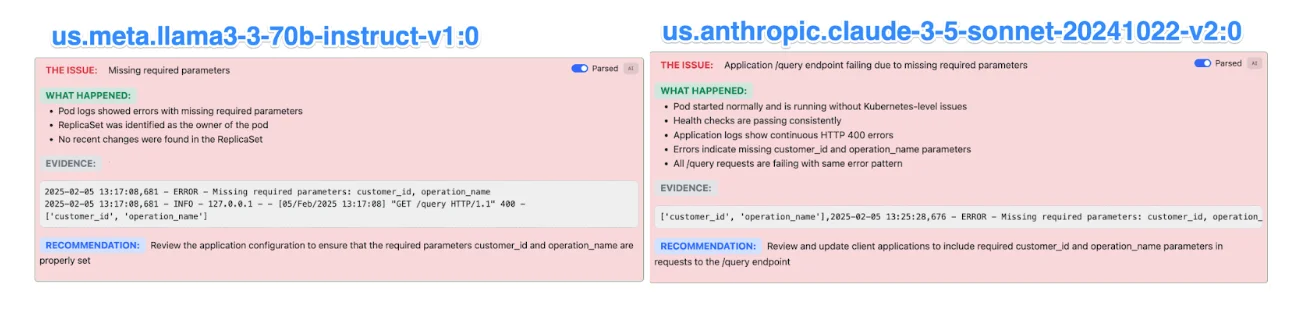
每个模型的观察结果:
-
Claude 3.5 和 LLaMA 3.3-70B 正确分析了 pod 日志,确定应用程序缺少
customer_id和operation_name在 API 调用中,并建议修复请求参数。
您可以在场景 #2 的图像中看到 Claude 和 LLaMA 同样诊断出缺少参数的问题,其中 Claude 稍微准确一些。
测试用例:部署请求的资源过多,导致 pod 处于 pending 状态
此测试涉及一个正在运行的部署,该部署已修改为具有极端的资源请求(1K CPU,128GB RAM),从而无法进行调度。
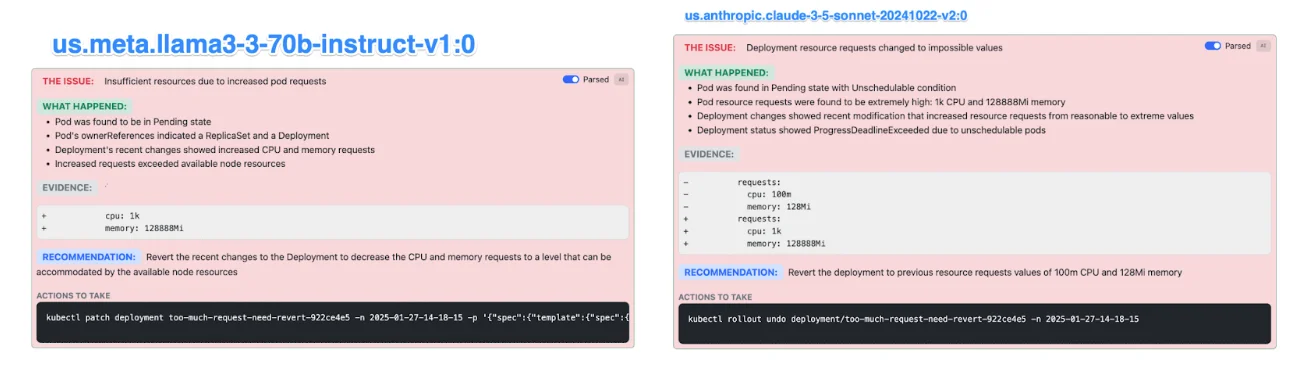
每个模型的观察结果:
- Claude 3.5 和 LLaMA 3.3-70B 正确地诊断了问题,识别出过多的资源请求,并建议回滚到先前的值。
您可以在场景 #3 的图像中看到,Claude 和 LLaMA 正确地诊断出过多的 CPU/内存请求,尽管 Claude 给出了更好的解释和行动号召
结论: Kubernetes 资源调度问题很复杂,人工智能不容易诊断。
成本分析:开源颠覆和 DeepSeek 因素
DeepSeek 崛起最引人注目的方面之一是围绕它的开源炒作。与 OpenAI 的专有模型或亚马逊紧密集成的 Bedrock 产品不同,DeepSeek 代表着一种日益增长的趋势,即完全开放和社区驱动的人工智能。许多人认为,像 DeepSeek 这样的模型可能是彻底颠覆人工智能生态系统的关键,提供一种既可访问又具有成本效益的替代方案。
这种论点不仅仅是理论上的。开源人工智能已经以多种方式改变了格局,从 Hugging Face 的 LLM 民主化到 Meta 发布的 LLaMA 模型,这些模型将生成式人工智能推向了企业和研究环境,而无需锁定供应商定价。
DeepSeek 作为一个开源模型,最终可能胜过 OpenAI、Claude 和其他封闭解决方案的想法并非牵强。如果它达到性能对等,那么在定制、成本和部署灵活性方面的优势将使其成为许多企业的默认选择。
为了评估这一因素,我们将 DeepSeek 与其他开放解决方案进行了比较,特别是 LLaMA 3.3-70B,由于其良好的性价比,该模型已被广泛采用。
在规模化部署人工智能驱动的故障排除时,一个关键的考虑因素是定价:
- Claude 3.5 Sonnet: $0.003 (input) / $0.015 (output)
- LLaMA 3.3 Instruct (70B): $0.00072 (both input/output)
LLaMA 以极低的成本提供了良好的性能,使其成为生产规模 Kubernetes 故障排除的一个选择。然而,DeepSeek 尽管是开源的,但在我们的基准测试中并没有表现出相同的准确性或故障排除能力。
- Claude 3.5 保持了其领先地位,提供了最准确和可操作的结果。
- LLaMA 3.3 显示出令人印象深刻的能力,在准确性和效率方面几乎与 Claude 相媲美。
- DeepSeek-V3 表现不佳,在大多数测试用例中都失败了。
- DeepSeek-R1 无法完成分析,使其无法用于实际的 Kubernetes 故障排除。
主要结论
目前的 DeepSeek 实现尚未准备好用于 Kubernetes 中的生产故障排除,因为它们难以与更成熟的模型在准确性和可靠性方面相匹配。相比之下,LLaMA 3.3-70B 已经显示出非常有希望的结果,以显着降低的成本提供了与 Claude 几乎相同的性能。
人工智能辅助故障排除正在迅速发展,随着这些模型的不断改进,它们对 Kubernetes 运营的影响只会越来越大。在 Komodor,我们不断改进 Klaudia 的人工智能驱动的诊断,以使 Kubernetes 故障排除更快、更可靠且更具成本效益。我们很想听听其他人的意见——您在使用这些模型方面的经验如何?您依赖哪种 AI 助手进行 Kubernetes 故障排除?