在这篇博客中,我们将探索如何构建一个 RAG。
译自 Building RAG systems in Go with Ent, Atlas, and pgvector | ent,作者 Rotem Tamir。
在这篇博文中,我们将探讨如何使用 Ent, Atlas, 和 pgvector 构建一个 RAG (检索增强生成) 系统。
RAG 是一种通过结合检索步骤来增强生成模型能力的技术。我们不再仅仅依赖于模型内部的知识,而是可以从外部来源检索相关文档或数据,并使用这些信息来生成更准确、更符合上下文的响应。这种方法在构建诸如问答系统、聊天机器人或任何需要最新或特定领域知识的应用程序时特别有用。
让我们从初始化 Go 模块开始我们的教程,该模块将用于我们的项目:
go mod init github.com/rotemtam/entrag # Feel free to replace the module path with your own在这个项目中,我们将使用 Ent, 一个 Go 的实体框架,来定义我们的数据库 schema。数据库将存储我们想要检索的文档(分块为固定大小)和表示每个块的向量。通过运行以下命令来初始化 Ent 项目:
go run -mod=mod entgo.io/ent/cmd/ent new Embedding Chunk此命令为我们的数据模型创建占位符。我们的项目应该如下所示:
ent
├── generate.go
├── schema
│ ├── chunk.go
│ └── embedding.go
├── go.mod
└── go.sum
接下来,让我们定义 Chunk 模型的 schema。打开 ent/schema/chunk.go 文件并按如下方式定义 schema:
package schema
import (
"entgo.io/ent"
"entgo.io/ent/schema/edge"
"entgo.io/ent/schema/field"
)
// Chunk holds the schema definition for the Chunk entity.
type Chunk struct {
ent.Schema
}
// Fields of the Chunk.
func (Chunk) Fields() []ent.Field {
return []ent.Field{
field.String("path"),
field.Int("nchunk"),
field.Text("data"),
}
}
// Edges of the Chunk.
func (Chunk) Edges() []ent.Edge {
return []ent.Edge{
edge.To("embedding", Embedding.Type).StorageKey(edge.Column("chunk_id")).Unique(),
}
}这个 schema 定义了一个 Chunk 实体,具有三个字段:path、nchunk 和 data。path 字段存储文档的路径,nchunk 存储块号,data 存储分块的文本数据。我们还定义了一个到 Embedding 实体的边,它将存储块的向量表示。
在继续之前,让我们安装 pgvector 包。pgvector 是一个 PostgreSQL 扩展,它提供对向量运算和相似性搜索的支持。我们将需要它来存储和检索我们块的向量表示。
go get github.com/pgvector/pgvector-go接下来,让我们定义 Embedding 模型的 schema。打开 ent/schema/embedding.go 文件并按如下方式定义 schema:
package schema
import (
"entgo.io/ent"
"entgo.io/ent/dialect"
"entgo.io/ent/dialect/entsql"
"entgo.io/ent/schema/edge"
"entgo.io/ent/schema/field"
"entgo.io/ent/schema/index"
"github.com/pgvector/pgvector-go"
)
// Embedding holds the schema definition for the Embedding entity.
type Embedding struct {
ent.Schema
}
// Fields of the Embedding.
func (Embedding) Fields() []ent.Field {
return []ent.Field{
field.Other("embedding", pgvector.Vector{}).
SchemaType(map[string]string{
dialect.Postgres: "vector(1536)",
}),
}
}
// Edges of the Embedding.
func (Embedding) Edges() []ent.Edge {
return []ent.Edge{
edge.From("chunk", Chunk.Type).Ref("embedding").Unique().Required(),
}
}
func (Embedding) Indexes() []ent.Index {
return []ent.Index{
index.Fields("embedding").
Annotations(
entsql.IndexType("hnsw"),
entsql.OpClass("vector_l2_ops"),
),
}
}这个 schema 定义了一个 Embedding 实体,它有一个类型为 pgvector.Vector 的字段 embedding。embedding 字段存储块的向量表示。我们还定义了一个到 Chunk 实体的边,以及一个在 embedding 字段上的索引,使用 hnsw 索引类型和 vector_l2_ops 运算符类。这个索引将使我们能够对嵌入执行高效的相似性搜索。
最后,让我们通过运行以下命令来生成 Ent 代码:
go mod tidy
go generate ./...Ent 将根据 schema 定义为我们的模型生成必要的代码。
接下来,让我们设置 PostgreSQL 数据库。我们将使用 Docker 在本地运行 PostgreSQL 实例。由于我们需要 pgvector 扩展,我们将使用 pgvector/pgvector:pg17 Docker 镜像,该镜像预装了该扩展。
docker run --rm --name postgres -e POSTGRES_PASSWORD=pass -p 5432:5432 -d pgvector/pgvector:pg17我们将使用 Atlas, 一个与 Ent 集成的数据库 schema 即代码工具,来管理我们的数据库 schema。通过运行以下命令来安装 Atlas:
curl -sSfL https://atlasgo.io/install.sh | sh更多安装选项,请参阅 Atlas 安装文档。
由于我们将要管理扩展,因此我们需要一个 Atlas Pro 帐户。您可以通过运行以下命令注册免费试用版:
atlas login
如果您想跳过使用 Atlas,您可以直接使用此文件中的语句将所需的模式直接应用于数据库。
现在,让我们创建 Atlas 配置,该配置将 base.pg.hcl 文件与 Ent 模式组合在一起:
data "composite_schema" "schema" {
schema {
url = "file://base.pg.hcl"
}
schema "public" {
url = "ent://ent/schema"
}
}
env "local" {
url = getenv("DB_URL")
schema {
src = data.composite_schema.schema.url
}
dev = "docker://pgvector/pg17/dev"
}
此配置定义了一个复合模式,其中包括 base.pg.hcl 文件和 Ent 模式。我们还定义了一个名为 local 的环境,该环境使用我们将用于本地开发的复合模式。dev 字段指定了 Dev Database URL,Atlas 使用该 URL 来规范化模式并进行各种计算。
接下来,让我们通过运行以下命令将模式应用于数据库:
export DB_URL='postgresql://postgres:pass@localhost:5432/postgres?sslmode=disable'
atlas schema apply --env local
Atlas 将从我们的配置中加载数据库的所需状态,将其与数据库的当前状态进行比较,并创建一个迁移计划以使数据库达到所需状态:
Planning migration statements (5 in total):
-- create extension "vector":
-> CREATE EXTENSION "vector" WITH SCHEMA "public" VERSION "0.8.0";
-- create "chunks" table:
-> CREATE TABLE "public"."chunks" (
"id" bigint NOT NULL GENERATED BY DEFAULT AS IDENTITY,
"path" character varying NOT NULL,
"nchunk" bigint NOT NULL,
"data" text NOT NULL,
PRIMARY KEY ("id")
);
-- create "embeddings" table:
-> CREATE TABLE "public"."embeddings" (
"id" bigint NOT NULL GENERATED BY DEFAULT AS IDENTITY,
"embedding" public.vector(1536) NOT NULL,
"chunk_id" bigint NOT NULL,
PRIMARY KEY ("id"),
CONSTRAINT "embeddings_chunks_embedding" FOREIGN KEY ("chunk_id") REFERENCES "public"."chunks" ("id") ON UPDATE NO ACTION ON DELETE NO ACTION
);
-- create index "embedding_embedding" to table: "embeddings":
-> CREATE INDEX "embedding_embedding" ON "public"."embeddings" USING hnsw ("embedding" vector_l2_ops);
-- create index "embeddings_chunk_id_key" to table: "embeddings":
-> CREATE UNIQUE INDEX "embeddings_chunk_id_key" ON "public"."embeddings" ("chunk_id");
-------------------------------------------
Analyzing planned statements (5 in total):
-- non-optimal columns alignment:
-- L4: Table "chunks" has 8 redundant bytes of padding per row. To reduce disk space,
the optimal order of the columns is as follows: "id", "nchunk", "path",
"data" https://atlasgo.io/lint/analyzers#PG110
-- ok (370.25µs)
-------------------------
-- 114.306667ms
-- 5 schema changes
-- 1 diagnostic
-------------------------------------------
? Approve or abort the plan:
⸠Approve and apply
Abort
除了规划更改之外,Atlas 还将提供诊断和建议,以优化模式。在这种情况下,它建议重新排序 chunks 表中的列以减少磁盘空间。由于在本教程中我们不关心磁盘空间,因此我们可以通过选择 Approve and apply 来继续迁移。
最后,我们可以验证我们的模式是否已成功应用,我们可以重新运行 atlas schema apply 命令。Atlas 将输出:
Schema is synced, no changes to be made
现在我们的数据库模式已经设置好,让我们搭建我们的 CLI 应用程序。在本教程中,我们将使用 alecthomas/kong 库来构建一个小应用程序,该应用程序可以加载、索引和查询数据库中的文档。
首先,安装 kong 库:
go get github.com/alecthomas/kong
接下来,创建一个名为 cmd/entrag/main.go 的新文件,并按如下方式定义 CLI 应用程序:
package main
import (
"fmt"
"os"
"github.com/alecthomas/kong"
)
// CLI holds global options and subcommands.
type CLI struct {
// DBURL is read from the environment variable DB_URL.
DBURL string `kong:"env='DB_URL',help='Database URL for the application.'"`
OpenAIKey string `kong:"env='OPENAI_KEY',help='OpenAI API key for the application.'"`
// Subcommands
Load *LoadCmd `kong:"cmd,help='Load command that accepts a path.'"`
Index *IndexCmd `kong:"cmd,help='Create embeddings for any chunks that do not have one.'"`
Ask *AskCmd `kong:"cmd,help='Ask a question about the indexed documents'"`
}
func main() {
var cli CLI
app := kong.Parse(&cli,
kong.Name("entrag"),
kong.Description("Ask questions about markdown files."),
kong.UsageOnError(),
)
if err := app.Run(&cli); err != nil {
fmt.Fprintf(os.Stderr, "Error: %s\n", err)
os.Exit(1)
}
}创建一个名为 cmd/entrag/rag.go 的额外文件,内容如下:
package main
type (
// LoadCmd loads the markdown files into the database.
LoadCmd struct {
Path string `help:"path to dir with markdown files" type:"existingdir" required:""`
}
// IndexCmd creates the embedding index on the database.
IndexCmd struct {
}
// AskCmd is another leaf command.
AskCmd struct {
// Text is the positional argument for the ask command.
Text string `kong:"arg,required,help='Text for the ask command.'"`
}
)通过运行以下命令验证我们搭建的 CLI 应用程序是否正常工作:
go run ./cmd/entrag --help如果一切设置正确,您应该看到 CLI 应用程序的帮助输出:
Usage: entrag <command> [flags]
Ask questions about markdown files.
Flags:
-h, --help Show context-sensitive help.
--dburl=STRING Database URL for the application ($DB_URL).
--open-ai-key=STRING OpenAI API key for the application ($OPENAI_KEY).
Commands:
load --path=STRING [flags]
Load command that accepts a path.
index [flags]
Create embeddings for any chunks that do not have one.
ask <text> [flags]
Ask a question about the indexed documents
Run "entrag <command> --help" for more information on a command.
接下来,我们需要一些 markdown 文件来加载到数据库中。创建一个名为 data 的目录,并向其中添加一些 markdown 文件。对于此示例,我下载了 ent/ent 仓库并使用了 docs 目录作为 markdown 文件的来源。现在,让我们实现 LoadCmd 命令以将 markdown 文件加载到数据库中。打开 cmd/entrag/rag.go 文件并添加以下代码:
const (
tokenEncoding = "cl100k_base"
chunkSize = 1000
)
// Run is the method called when the "load" command is executed.
func (cmd *LoadCmd) Run(ctx *CLI) error {
client, err := ctx.entClient()
if err != nil {
return fmt.Errorf("failed opening connection to postgres: %w", err)
}
tokTotal := 0
return filepath.WalkDir(ctx.Load.Path, func(path string, d fs.DirEntry, err error) error {
if filepath.Ext(path) == ".mdx" || filepath.Ext(path) == ".md" {
chunks := breakToChunks(path)
for i, chunk := range chunks {
tokTotal += len(chunk)
client.Chunk.Create().
SetData(chunk).
SetPath(path).
SetNchunk(i).
SaveX(context.Background())
}
}
return nil
})
}
func (c *CLI) entClient() (*ent.Client, error) {
return ent.Open("postgres", c.DBURL)
}此代码定义了 LoadCmd 命令的 Run 方法。该方法从指定的路径读取 markdown 文件,将它们分成 1000 个 token 的块,并将它们保存到数据库中。我们使用 entClient 方法来使用 CLI 选项中指定的数据库 URL 创建一个新的 Ent 客户端。
有关 breakToChunks 的实现,请参见 完整代码 在 entrag 仓库 中,它几乎完全基于 Eli Bendersky's intro to RAG in Go。
最后,让我们运行 load 命令以将 markdown 文件加载到数据库中:
go run ./cmd/entrag load --path=data命令完成后,您应该看到块已加载到数据库中。要验证,请运行:
docker exec -it postgres psql -U postgres -d postgres -c "SELECT COUNT(*) FROM chunks;"您应该看到类似以下内容:
count
-------
276
(1 row)
现在我们已经将文档加载到数据库中,我们需要为每个块创建嵌入。我们将使用 OpenAI API 为块生成嵌入。为此,我们需要安装 openai 包:
go get github.com/sashabaranov/go-openai如果您没有 OpenAI API 密钥,您可以在 OpenAI Platform 上注册一个帐户并生成一个 API 密钥。
我们将从环境变量 OPENAI_KEY 中读取此密钥,因此让我们设置它:
export OPENAI_KEY=<your OpenAI API key>接下来,让我们实现 IndexCmd 命令以创建块的嵌入。打开 cmd/entrag/rag.go 文件并添加以下代码:
// Run is the method called when the "index" command is executed.
func (cmd *IndexCmd) Run(cli *CLI) error {
client, err := cli.entClient()
if err != nil {
return fmt.Errorf("failed opening connection to postgres: %w", err)
}
ctx := context.Background()
chunks := client.Chunk.Query().
Where(
chunk.Not(
chunk.HasEmbedding(),
),
).
Order(ent.Asc(chunk.FieldID)).
AllX(ctx)
for _, ch := range chunks {
log.Println("Created embedding for chunk", ch.Path, ch.Nchunk)
embedding := getEmbedding(ch.Data)
_, err := client.Embedding.Create().
SetEmbedding(pgvector.NewVector(embedding)).
SetChunk(ch).
Save(ctx)
if err != nil {
return fmt.Errorf("error creating embedding: %v", err)
}
}
return nil
}
// getEmbedding invokes the OpenAI embedding API to calculate the embedding
// for the given string. It returns the embedding.
func getEmbedding(data string) []float32 {
client := openai.NewClient(os.Getenv("OPENAI_KEY"))
queryReq := openai.EmbeddingRequest{
Input: []string{data},
Model: openai.AdaEmbeddingV2,
}
queryResponse, err := client.CreateEmbeddings(context.Background(), queryReq)
if err != nil {
log.Fatalf("Error getting embedding: %v", err)
}
return queryResponse.Data[0].Embedding
}我们已经为 IndexCmd 命令定义了 Run 方法。该方法查询数据库中没有 embedding 的 chunks,使用 OpenAI API 为每个 chunk 生成 embeddings,并将 embeddings 保存到数据库。
最后,让我们运行 index 命令来为 chunks 创建 embeddings:
go run ./cmd/entrag index你应该会看到类似的日志:
2025/02/13 13:04:42 Created embedding for chunk /Users/home/entr/data/md/aggregate.md 0
2025/02/13 13:04:43 Created embedding for chunk /Users/home/entr/data/md/ci.mdx 0
2025/02/13 13:04:44 Created embedding for chunk /Users/home/entr/data/md/ci.mdx 1
2025/02/13 13:04:45 Created embedding for chunk /Users/home/entr/data/md/ci.mdx 2
2025/02/13 13:04:46 Created embedding for chunk /Users/home/entr/data/md/code-gen.md 0
2025/02/13 13:04:47 Created embedding for chunk /Users/home/entr/data/md/code-gen.md 1
现在我们已经加载了文档并为 chunks 创建了 embeddings,我们可以实现 AskCmd 命令来提问关于索引文档的问题。打开 cmd/entrag/rag.go 文件并添加以下代码:
// Run is the method called when the "ask" command is executed.
func (cmd *AskCmd) Run(ctx *CLI) error {
client, err := ctx.entClient()
if err != nil {
return fmt.Errorf("failed opening connection to postgres: %w", err)
}
question := cmd.Text
emb := getEmbedding(question)
embVec := pgvector.NewVector(emb)
embs := client.Embedding.
Query().
Order(func(s *sql.Selector) {
s.OrderExpr(sql.ExprP("embedding <-> $1", embVec))
}).
WithChunk().
Limit(5).
AllX(context.Background())
b := strings.Builder{}
for _, e := range embs {
chnk := e.Edges.Chunk
b.WriteString(fmt.Sprintf("From file: %v\n", chnk.Path))
b.WriteString(chnk.Data)
}
query := fmt.Sprintf(`Use the below information from the ent docs to answer the subsequent question.
Information:
%v
Question: %v`, b.String(), question)
oac := openai.NewClient(ctx.OpenAIKey)
resp, err := oac.CreateChatCompletion(
context.Background(),
openai.ChatCompletionRequest{
Model: openai.GPT4o,
Messages: []openai.ChatCompletionMessage{
{
Role: openai.ChatMessageRoleUser,
Content: query,
},
},
},
)
if err != nil {
return fmt.Errorf("error creating chat completion: %v", err)
}
choice := resp.Choices[0]
out, err := glamour.Render(choice.Message.Content, "dark")
fmt.Print(out)
return nil
}这就是所有部分组合在一起的地方。在使用文档及其 embeddings 准备好数据库后,我们现在可以提问关于它们的问题。让我们分解 AskCmd 命令:
emb := getEmbedding(question)
embVec := pgvector.NewVector(emb)
embs := client.Embedding.
Query().
Order(func(s *sql.Selector) {
s.OrderExpr(sql.ExprP("embedding <-> $1", embVec))
}).
WithChunk().
Limit(5).
AllX(context.Background())我们首先使用 OpenAI API 将用户的问题转换为向量。使用这个向量,我们希望在数据库中找到最相似的 embeddings。我们查询数据库中的 embeddings,使用 pgvector 的 <-> 运算符按相似度排序,并将结果限制为前 5 个。
for _, e := range embs {
chnk := e.Edges.Chunk
b.WriteString(fmt.Sprintf("From file: %v\n", chnk.Path))
b.WriteString(chnk.Data)
}
query := fmt.Sprintf(`Use the below information from the ent docs to answer the subsequent question.
Information:
%v
Question: %v`, b.String(), question)接下来,我们准备来自前 5 个 chunks 的信息,以用作问题的上下文。然后,我们将问题和上下文格式化为单个字符串。
oac := openai.NewClient(ctx.OpenAIKey)
resp, err := oac.CreateChatCompletion(
context.Background(),
openai.ChatCompletionRequest{
Model: openai.GPT4o,
Messages: []openai.ChatCompletionMessage{
{
Role: openai.ChatMessageRoleUser,
Content: query,
},
},
},
)
if err != nil {
return fmt.Errorf("error creating chat completion: %v", err)
}
choice := resp.Choices[0]
out, err := glamour.Render(choice.Message.Content, "dark")
fmt.Print(out)然后,我们使用 OpenAI API 生成对问题的响应。我们将问题和上下文传递给 API 并接收响应。然后,我们使用 glamour 包渲染响应,以在终端中显示它。
在运行 ask 命令之前,让我们安装 glamour 包:
go get github.com/charmbracelet/glamour最后,让我们运行 ask 命令来提问关于索引文档的问题:
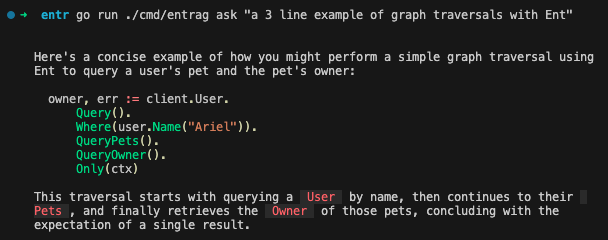
go run ./cmd/entrag ask "tl;dr What is Ent?"
我们的 RAG 系统响应:
Ent is an open-source entity framework (ORM) for the Go programming language. It
allows developers to define data models or graph-structures in Go code. Ent
emphasizes principles such as schema as code, a statically typed and explicit
API generated through codegen, simple queries and graph traversals, statically
typed predicates, and storage agnosticism. It supports various databases,
including MySQL, MariaDB, PostgreSQL, SQLite, and Gremlin-based graph databases,
and aims to enhance productivity in Go development.
太棒了!我们已经成功地使用 Ent、Atlas 和 pgvector 构建了一个 RAG 系统。我们现在可以询问有关加载到数据库中的文档的问题,并获得具有上下文感知的响应。
在这篇博文中,我们探讨了如何使用 Ent、Atlas 和 pgvector 构建 RAG 系统。特别感谢 Eli Bendersky 的内容丰富的博文以及多年来他出色的 Go 写作!