
Anthropic开发了一种保护AI语言模型免受操纵尝试的新方法。然而,在他们的安全挑战启动仅仅六天后,所有防御措施都被绕过了。
译自 Claude Jailbreak results are in, and the hackers won,作者 Maximilian Schreiner。
2025年2月15日更新 :Anthropic的Claude越狱挑战赛结果出来了。经过五天紧张的探测——涉及超过30万条消息,Anthropic估计总共花费了3700小时的集体努力——AI系统的防御最终被攻破。
Anthropic研究员Jan Leike在X上分享称,四位参与者成功通过了所有挑战关卡。一位参与者成功发现了一种通用越狱方法——基本上是绕过Claude安全防护的万能钥匙。Anthropic向获胜者总共支付了55,000美元。Leike表示,这项挑战表明,安全分类器虽然有用,但本身不足以提供足够的保护。这与我们从其他近期AI安全研究中了解到的情况一致——很少有万能的解决方案,而且这些模型的概率性质使得保护它们尤其具有挑战性。
Leike强调,随着模型变得越来越强大,抵御越狱攻击的能力成为防止滥用与化学、生物、放射性和核风险相关的关键安全要求。
2025年2月11日更新 :
在挑战启动仅仅六天内,就有人成功绕过了旨在保护Anthropic AI模型的所有安全机制。
Jan Leike,前OpenAI对齐团队成员,现就职于Anthropic,在X上宣布,一位参与者成功突破了挑战赛的所有八个关卡。集体努力涉及参与者大约3700小时的测试和30万条消息。然而,Leike指出,还没有人发现能够一次性解决所有挑战关卡的通用越狱方法。
随着AI模型变得越来越强大,保护它们变得越来越重要——而通用越狱方法也变得更有价值。这种动态表明,语言模型最终可能会发展出自己的安全生态系统,类似于当今操作系统所拥有的安全生态系统。
2025年2月4日原始文章
AI公司Anthropic开发了一种方法来保护语言模型免受操纵尝试。
Anthropic开发了一种名为“宪法分类器”的新安全方法,以防止人们诱骗AI模型给出有害的回应。这项技术专门针对通用越狱——旨在系统地绕过所有安全措施的输入。
为了对系统进行测试,Anthropic招募了183人,在两个月内尝试突破其防御。参与者试图让AI模型Claude 3.5回答十个禁止的问题。即使有15,000美元的奖金和大约3,000小时的测试,也没有人能够绕过所有安全措施。
初始版本有两个主要缺点:它将过多的无害请求标记为危险,并且需要过多的计算能力。虽然改进后的版本解决了这些问题,如使用10,000次越狱尝试的自动化测试所示,但仍然存在一些挑战。
测试显示,虽然未受保护的Claude模型允许86%的操纵尝试通过,但受保护的版本阻止了95%以上的操纵尝试。该系统仅错误地标记了额外0.38%的无害请求,尽管它仍然需要23.7%的额外计算能力才能运行。
安全系统的工作原理是使用预定义的规则来确定允许或禁止的内容。使用此“宪法”,它会创建各种语言和风格的合成训练示例。然后,这些示例训练分类器来发现可疑输入。
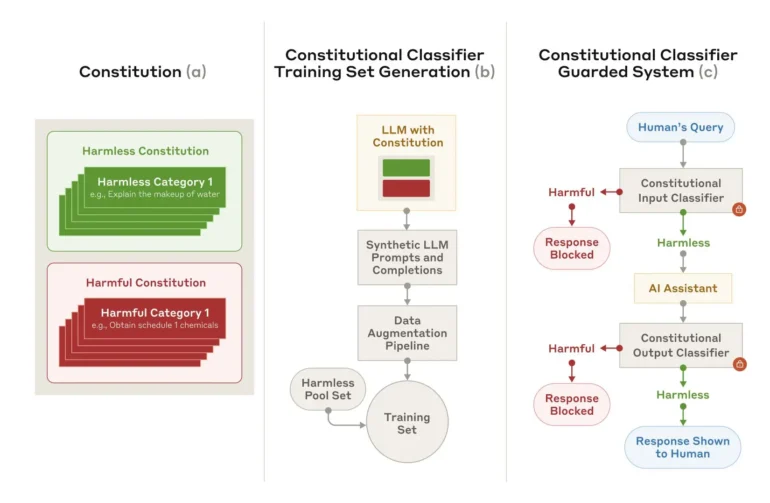
研究人员承认,该系统并非万无一失,无法抵御所有通用越狱攻击,并且可能出现它无法处理的新攻击方法。这就是为什么Anthropic建议将其与其他安全措施一起使用。
为了进一步测试系统的强度,Anthropic发布了一个公开演示版本。安全专家可以从2025年2月3日至10日尝试击败它,结果将在更新中分享。