
译自:Kubernetes Troubleshooting: A Step-by-Step Guide | Devtron
作者:Vishu Goyal
本指南重点介绍开发人员常遇到的三个关键 Kubernetes 错误:容器 CRASHLOOPBACKOFF 问题(OOM Killed 和 CPU 限制)、环境变量/密钥挂载问题以及数据库连接问题。在本博文中,我们将探讨每个问题的实用解决方案。
在现代软件行业,微服务架构和Kubernetes已成为全球范围内组织寻求可扩展性和运营效率的普遍解决方案。一方面,这些尖端技术帮助组织大规模运营;另一方面,应对其复杂性可能具有挑战性,您可能会遇到阻碍生产服务器部署速度的错误和错误配置。这篇博文将讨论最常见的Kubernetes错误及其解决方案。
- 容器CRASHLOOPBACKOFF问题(OOM Killed和CPU限制)。
- 环境变量/密钥挂载问题。
- 数据库连接问题。
首先让我们了解这个问题,CRASHLOOPBACKOFF问题通常发生在容器由于内部代码故障而崩溃,或者无法连接到其所需的依赖项时。Kubelet负责创建Pod并在其中启动容器。由于容器不断崩溃,Kubelet会不断尝试重新启动容器,从而导致崩溃循环。在这个崩溃循环中,容器崩溃和容器重启的过程中存在一些时间延迟,这就是回退时间,并且回退时间会随着每次重启而增加。
为了理解CRASHLOOPBACKOFF的流程,让我们举个例子:假设我们要在Kubernetes Pod中部署一个容器化应用程序,一旦我们启动部署管道,流程将如下所示:容器 > 容器运行 > 容器停止(原因:CRASHLOOPBACKOFF)。现在容器启动失败,Kubelet将在固定的时间延迟(例如3秒)后尝试重新启动容器。3秒后,容器将重新启动,但是,由于存在错误配置,容器将再次失败。再次,在容器重新启动之前将会有延迟,这次延迟将在循环继续之前为6秒。
现在我们知道了什么是CRASHLOOPBACKOFF,让我们来看看常见原因:
- OOM Killed
- CPU限制
CRASHLOOPBACKOFF错误最常见的原因是应用程序内存不足,通常称为OOM Killed。这可能是由于代码中的内存泄漏或特定节点上缺乏运行应用程序的资源造成的,即分配的内存少于应用程序实际需求的节点。
OOMKilled错误的故障排除包括根据应用程序的要求修复分配的资源。如果错误的原因是内存泄漏等问题,可以通过在应用程序代码级别进行优化来解决。
由OOM Killed引起的CRASHLOOPBACKOFF故障排除:
步骤1:将应用程序部署到Kubernetes
- 在将我们的Java应用程序部署到Kubernetes集群时,我们遇到了CRASHLOOPBACKOFF问题,让我们调查并尝试找到解决方案。
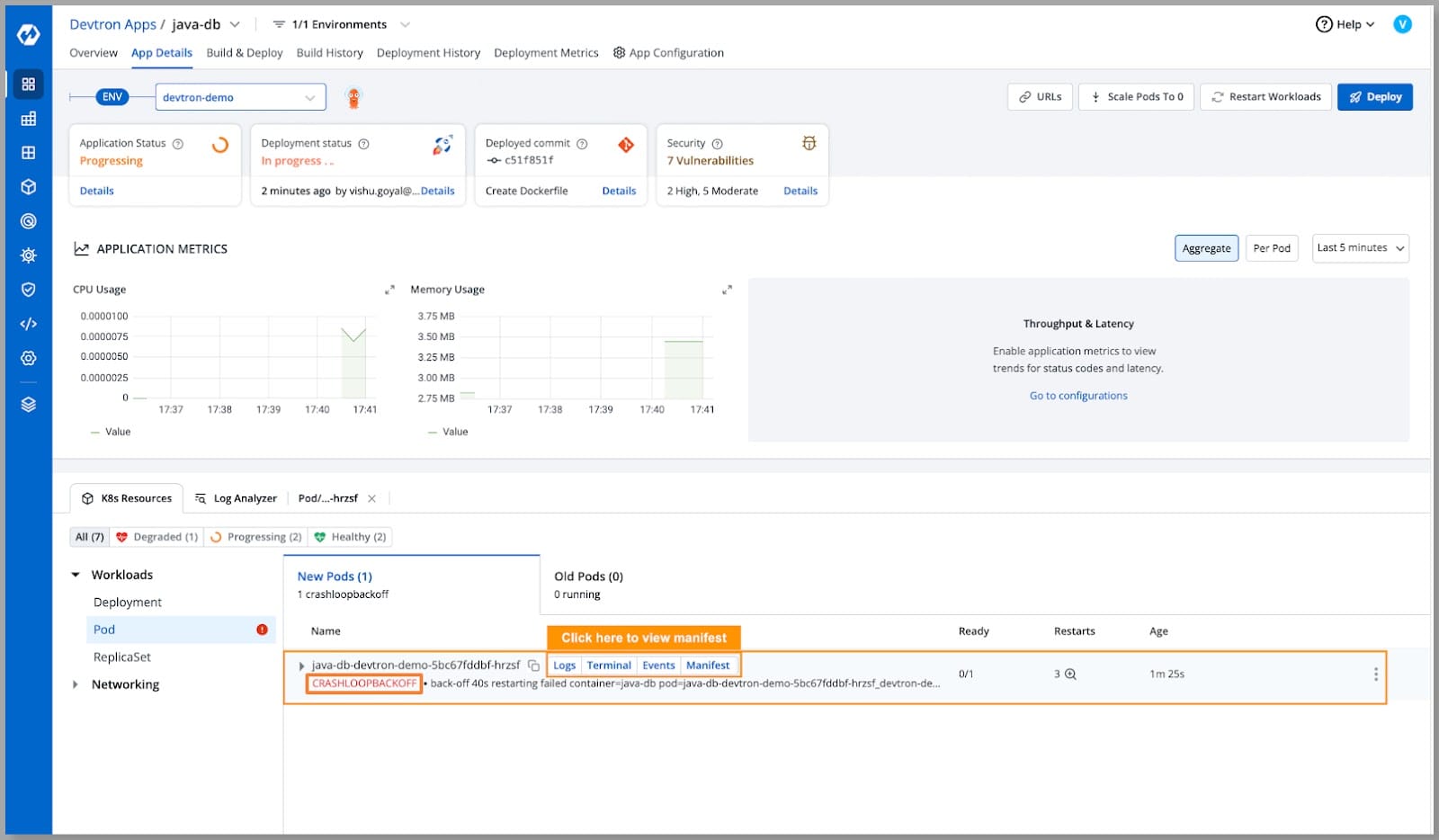
[Fig.1] Pod in Crashloopbackoff
步骤2:了解原因
- 任何错误的故障排除第一步都是了解问题背后的真正原因。让我们看看运行容器的Pod的清单。
- 通过点击Pod操作中的清单查看清单。
- 查看清单后,我们可以看到原因是OOM Killed,下面我们可以看到容器无法启动,并且当前的回退时间为40秒。
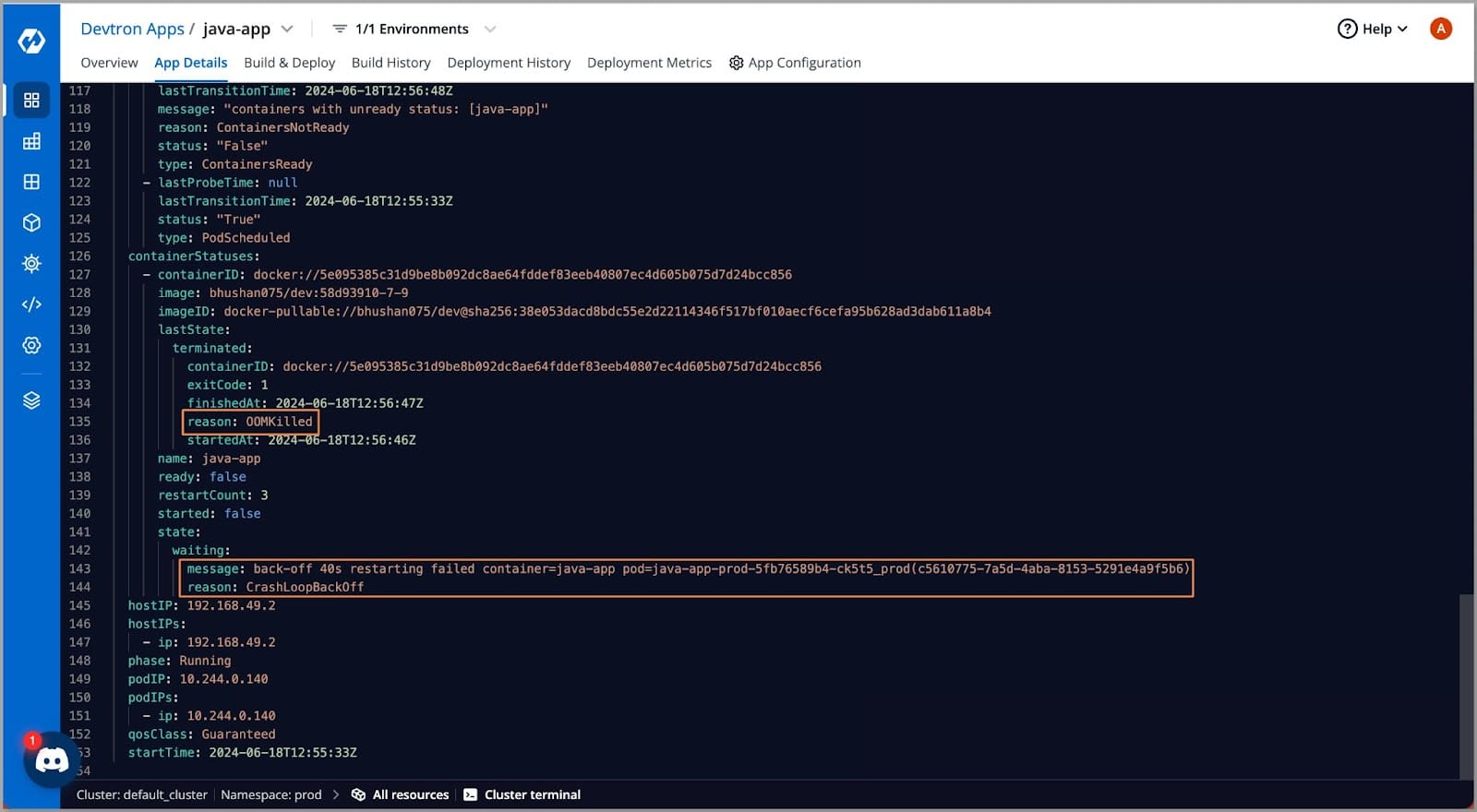
[Fig.2] Crashloopbackoff error message
- 我们遇到的CRASHLOOPBACKOFF错误的原因是OOM Killed。让我们看看如何排除此错误。
步骤3:排除错误
- OOM Killed错误是由于内存不足引起的。这意味着应用程序需要的内存比分配的内存更多。让我们尝试增加应用程序部署模板中分配的资源。
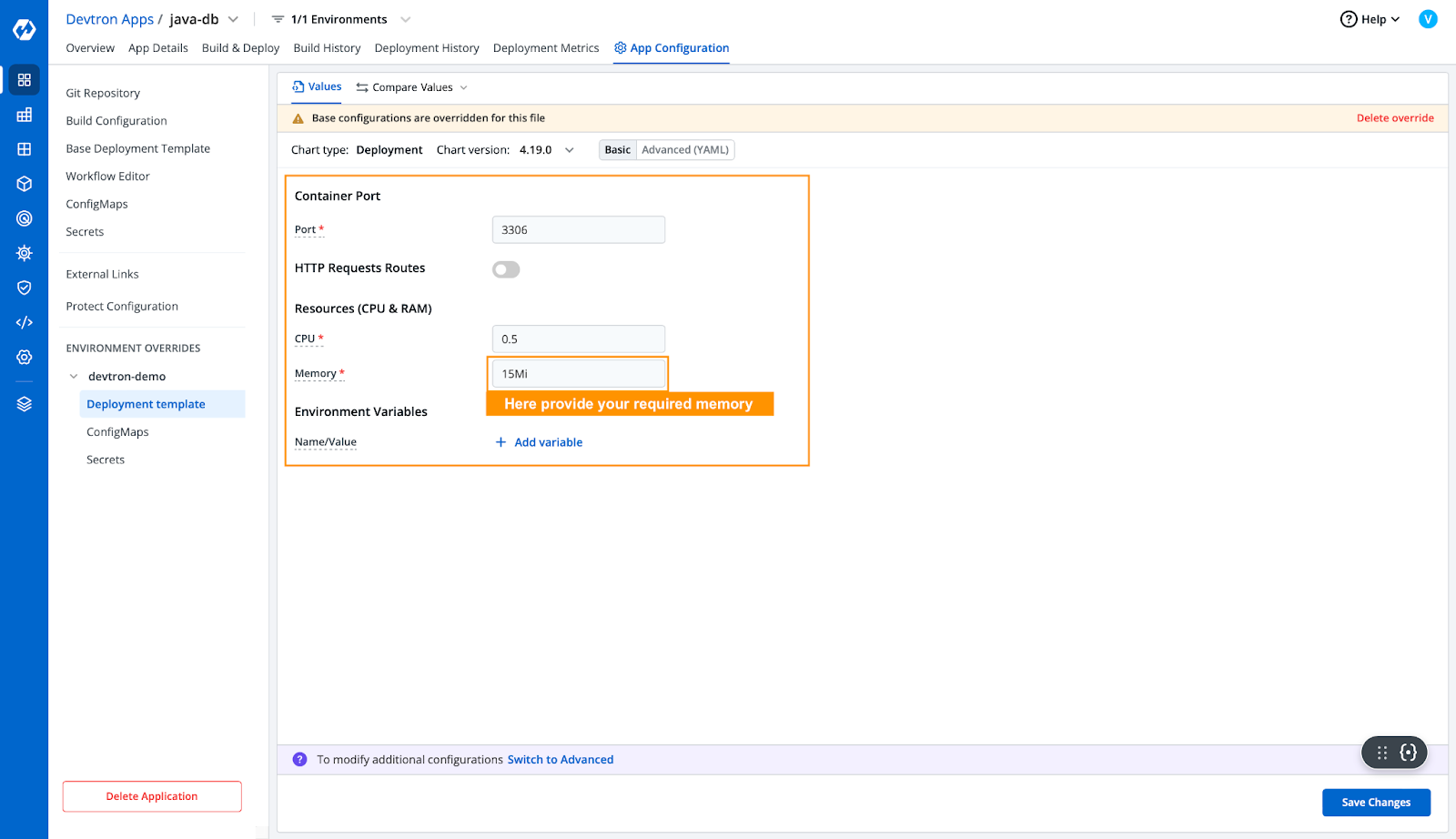
[Fig.3] Update Memory Limits
- 更新部署模板中的所需资源后,为确保我们将在高级yaml部署模板中检查资源是否已更新。
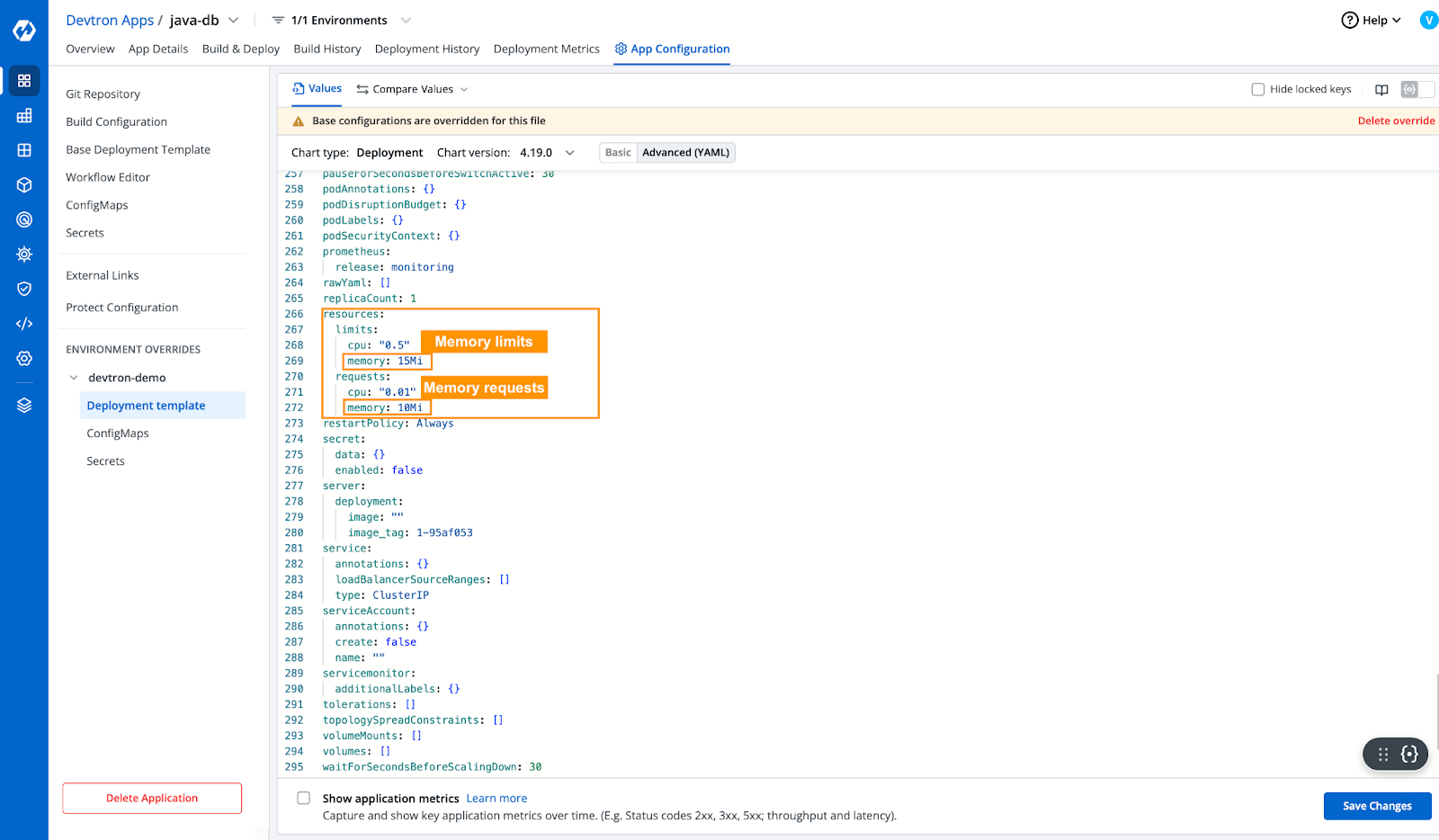
[Fig.4] Update Memory requests in YAML
- 现在我们已经增加了应用程序的资源,让我们部署应用程序并查看它是否平稳运行。
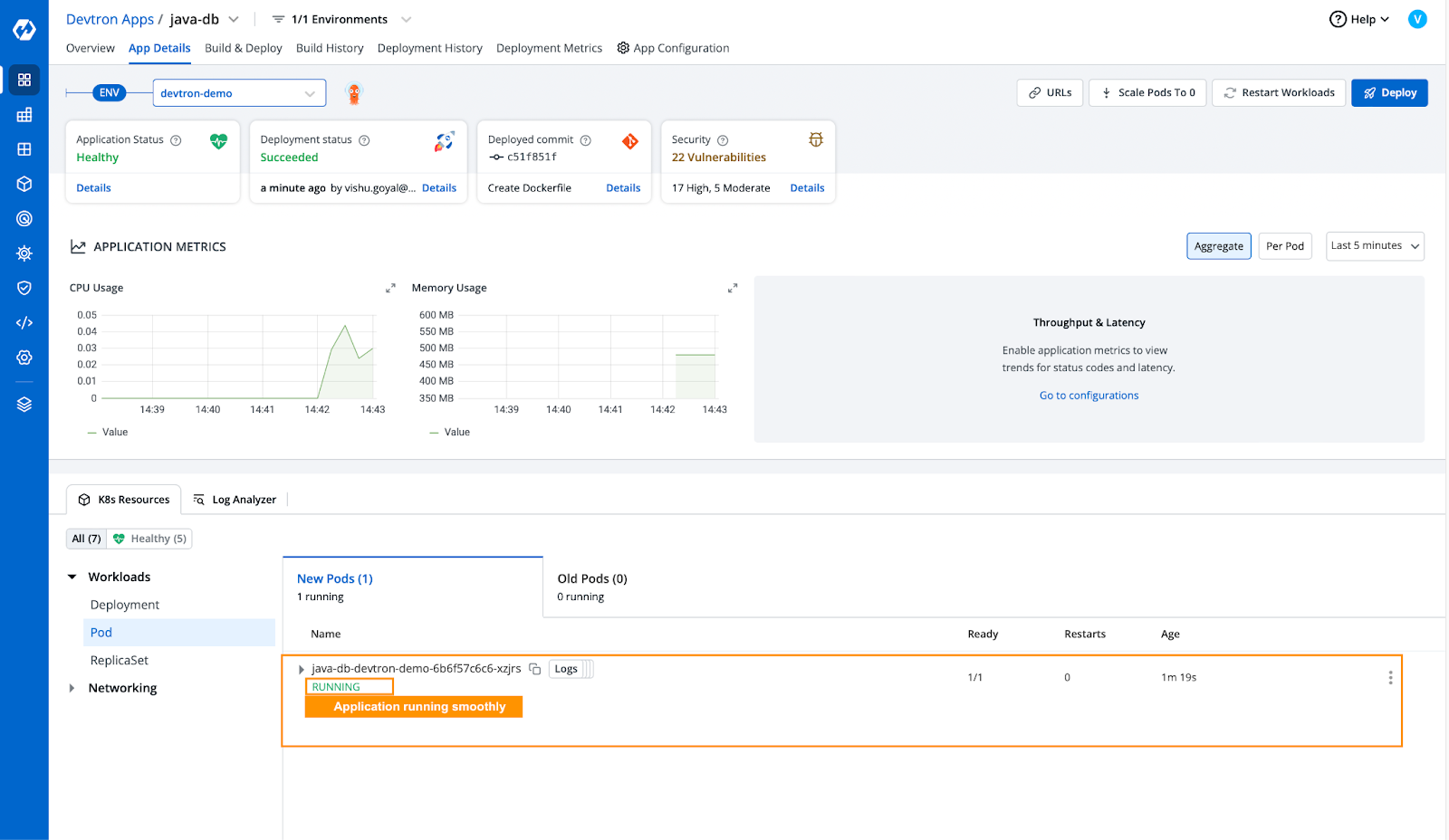
[Fig.5] Application successfully running
- 我们的应用程序已成功部署并平稳运行。
解决OOMKilled问题后,通过增加pod的内存分配,我们的应用程序已经启动并运行。但是,我们面临一个新的挑战:性能低于预期,并且pod正在重启。这可能是由于分配给应用程序的CPU不足,即应用程序正在以最大容量利用分配的CPU。这种情况也称为CPU节流。让我们寻找一个快速的解决方案:
步骤1:识别CPU节流
为了跟踪应用程序的资源利用率,我们实现了一个监控堆栈,如下图所示。使用Grafana仪表板,我们观察到应用程序正在以最大CPU容量运行,导致CPU节流。
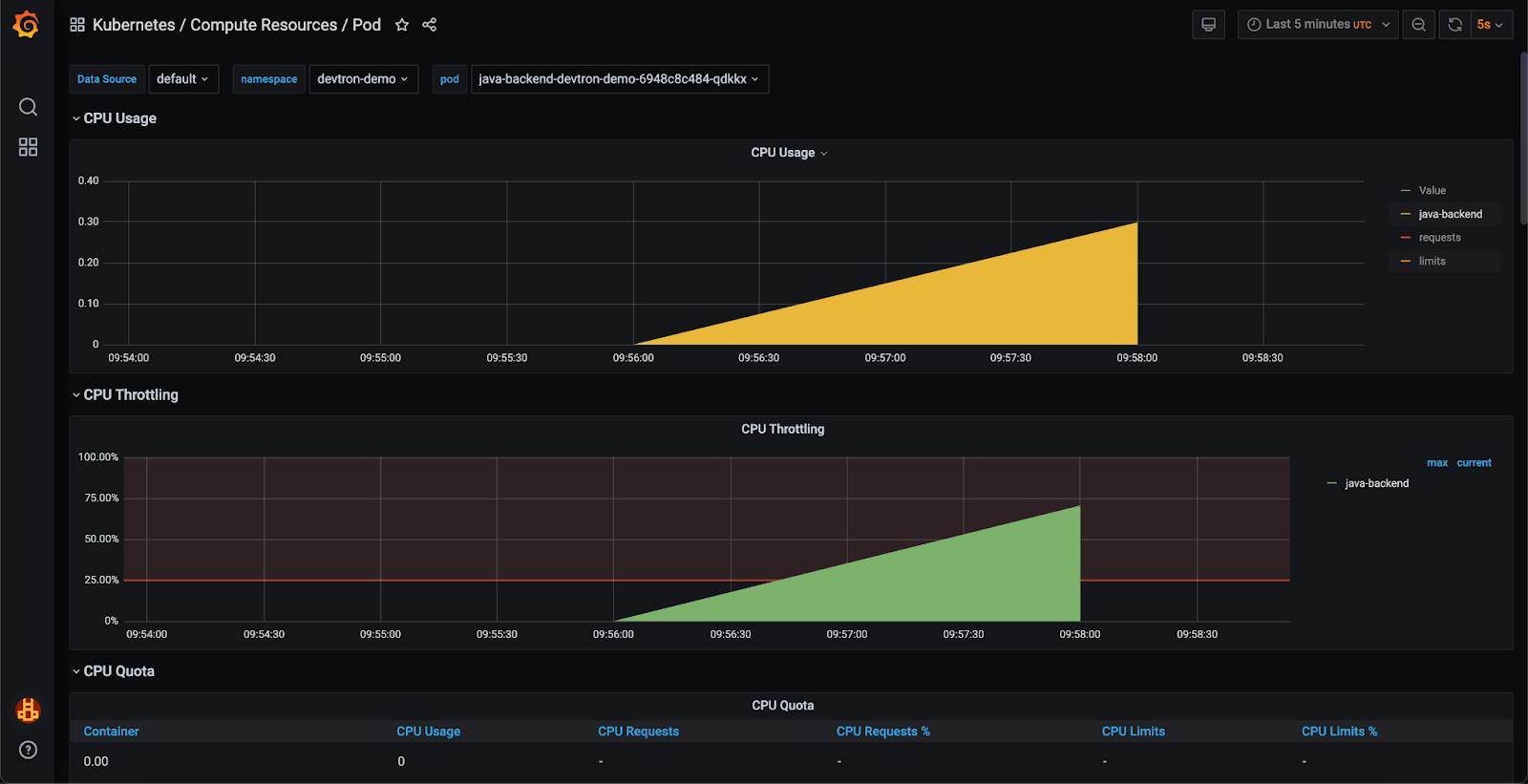
[Fig.6] Resource utilization in Grafana Dashboard
步骤2:增加CPU分配
为了解决这个问题,我们将增加应用程序的CPU分配。我们将遵循与上一节步骤3中调整内存分配类似的步骤。我们将在应用程序的部署模板中修改CPU分配。修改后的部署模板,增加了CPU分配,如下所示:
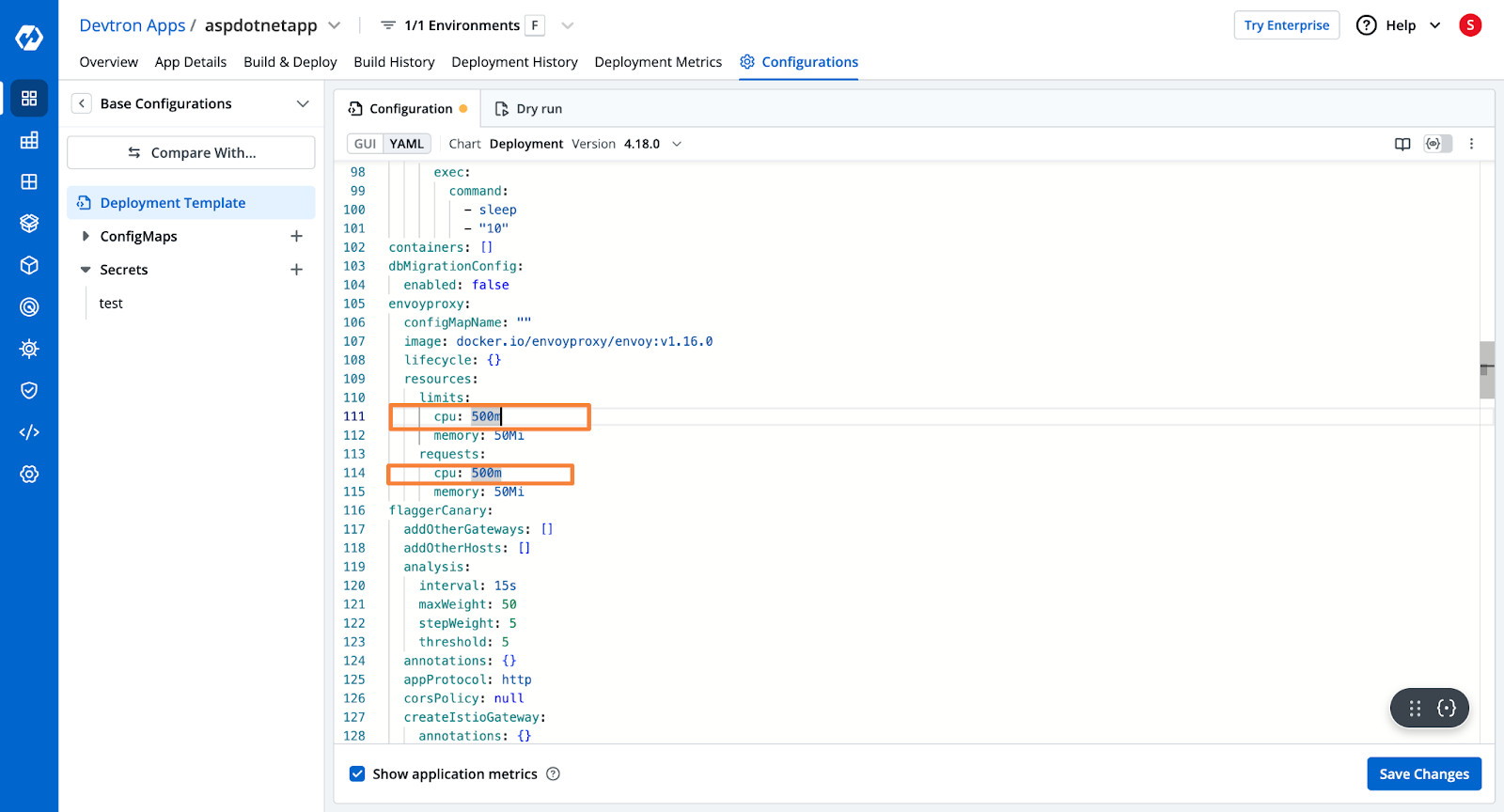
[Fig.7] Increase CPU Allocation
步骤3:验证解决方案
让我们重新部署应用程序,并在Grafana仪表板查看性能指标。
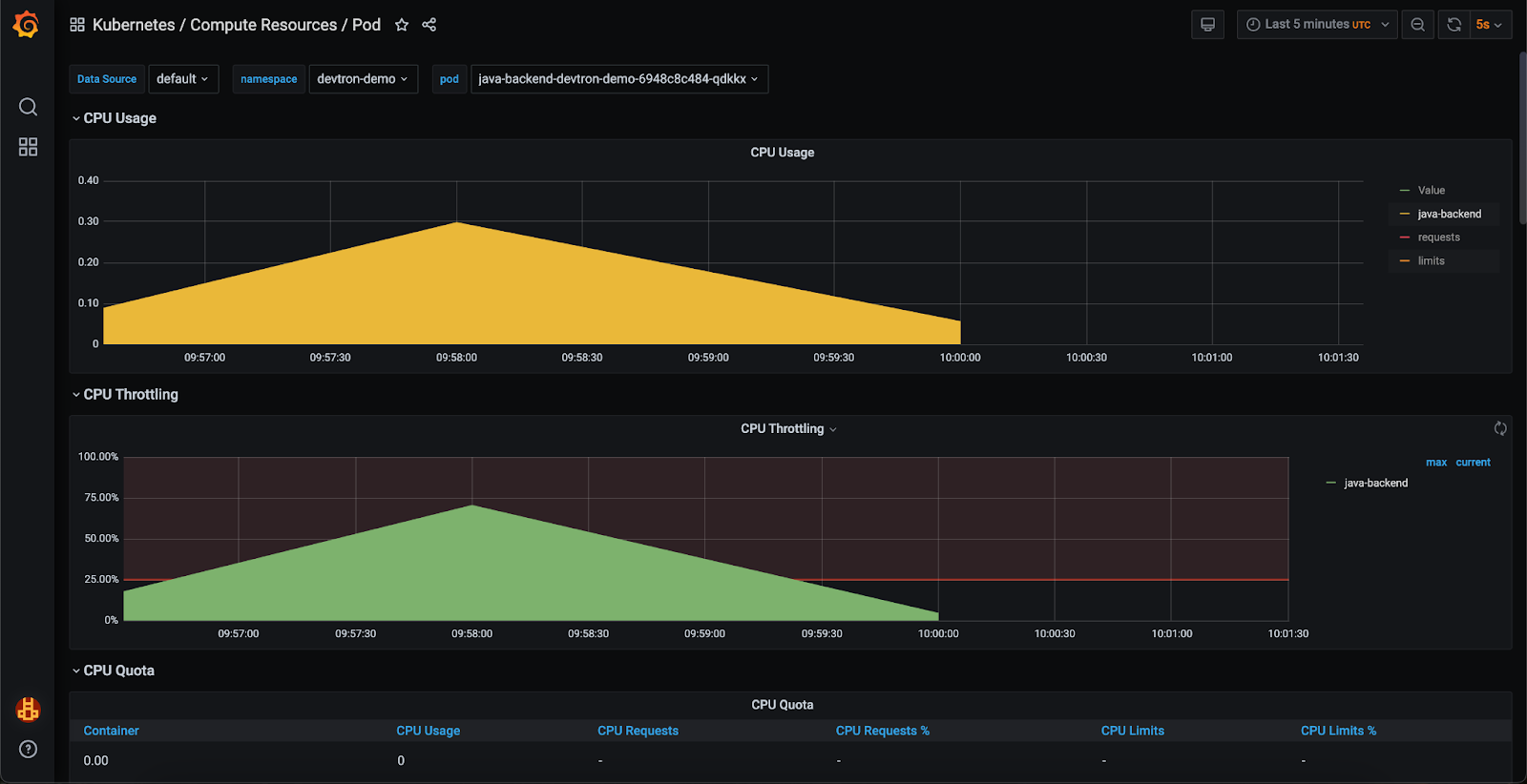
[Fig.8] Resource Utilization in Grafana
复查后,我们可以确认应用程序的CPU利用率已经恢复正常,并且不再发生节流。
错误配置的环境变量和不正确挂载的密钥可能导致Kubernetes环境中出现重大问题。这些问题可能导致应用程序故障、安全漏洞或难以诊断的意外行为。让我们看看devtron如何帮助我们诊断和修复这些问题。
在Kubernetes上部署应用程序时,我们会处理多个环境变量和密钥。在我们的案例中,我们遇到一个pod错误,导致502 Bad Gateway。
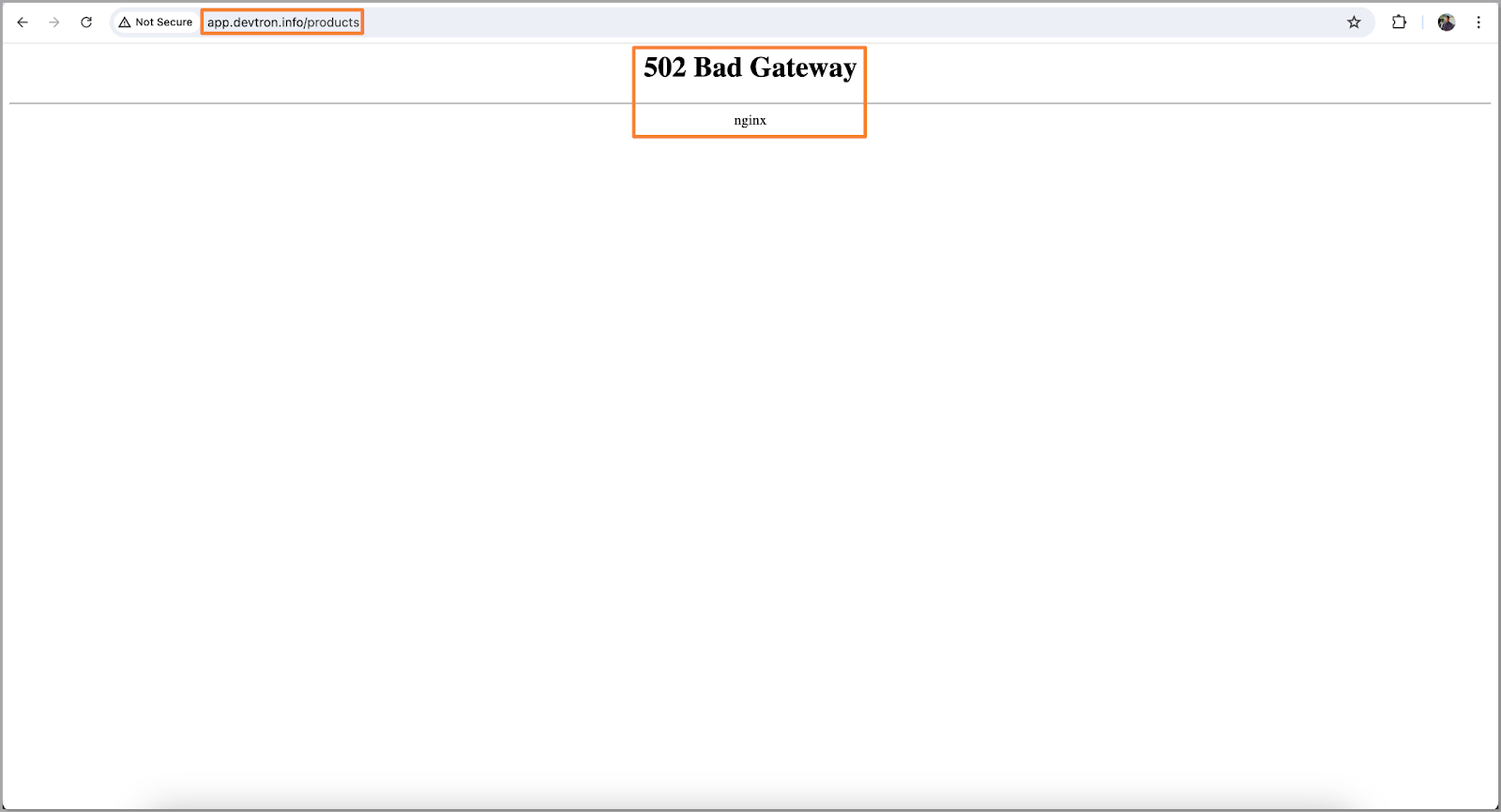
[Fig.9] Error Accessing Application
为了调查,我们的初始故障排除步骤将是检查pod的清单。
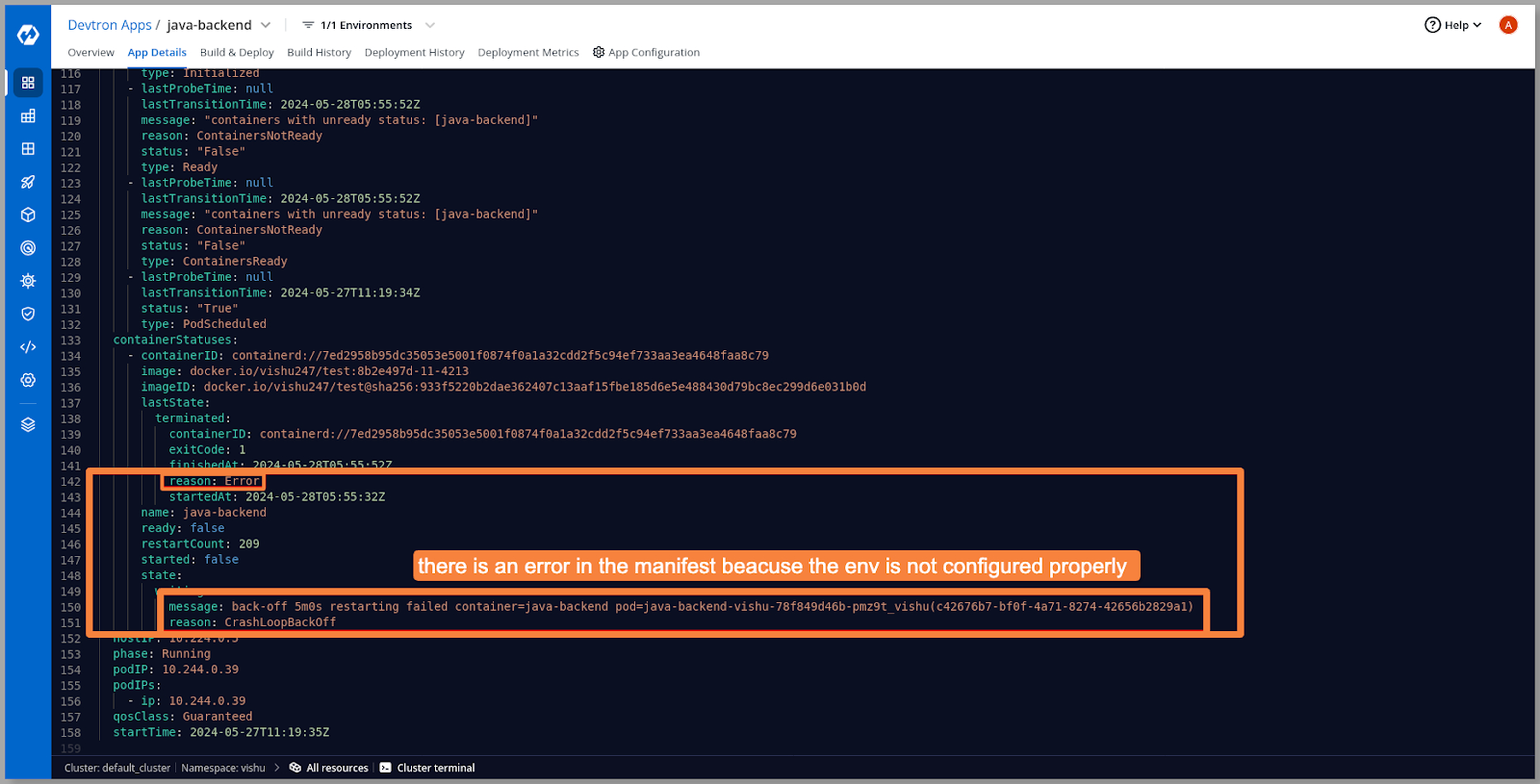
[Fig.10] Error Message in YAML Manifest
分析pod清单显示错误的环境变量和密钥触发了错误。让我们看看我们的配置和密钥,并交叉验证它们。
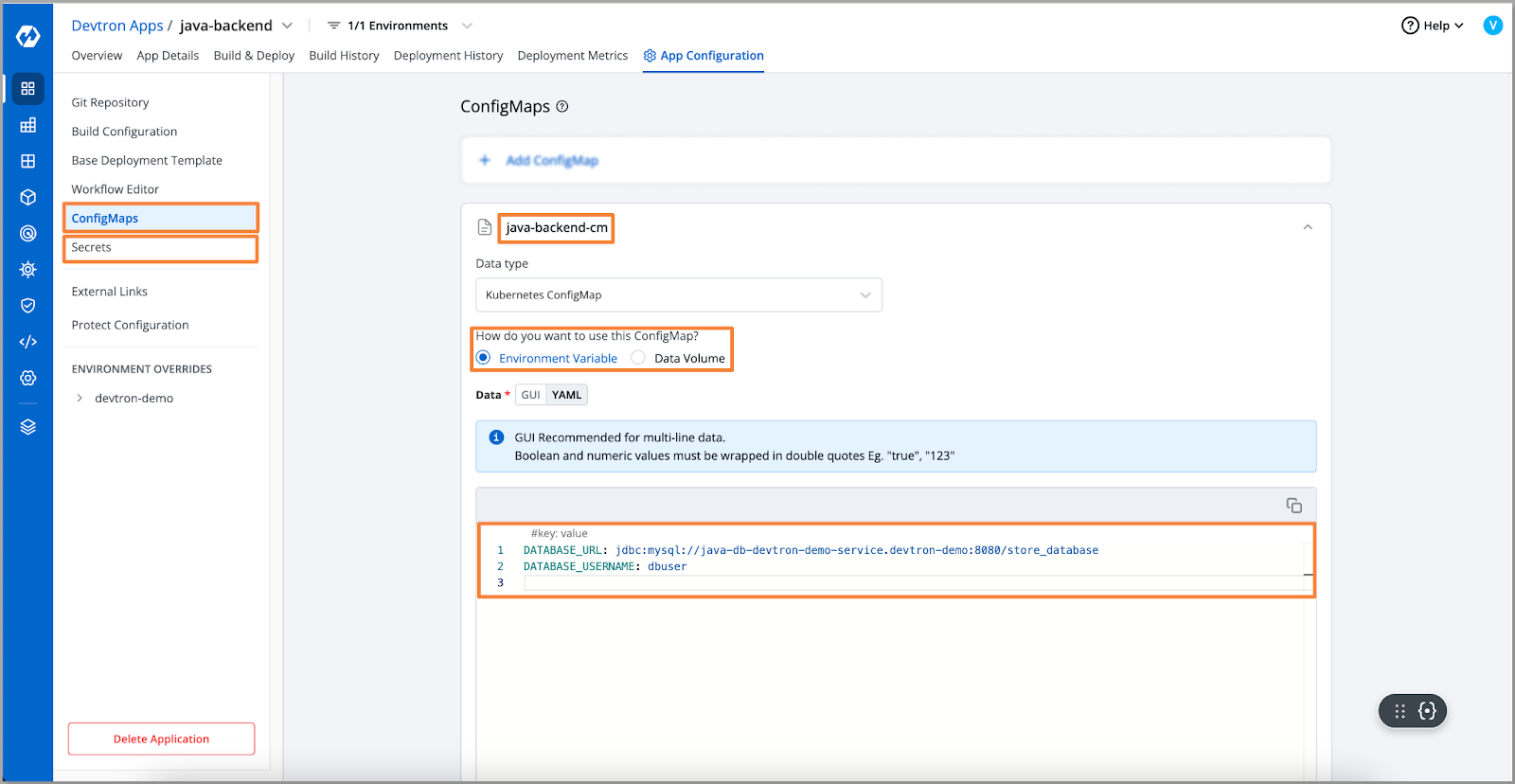
[Fig.11] Update ConfigMap and Secret Data
交叉验证后,我们发现数据库URL配置错误。让我们替换正确的URL。
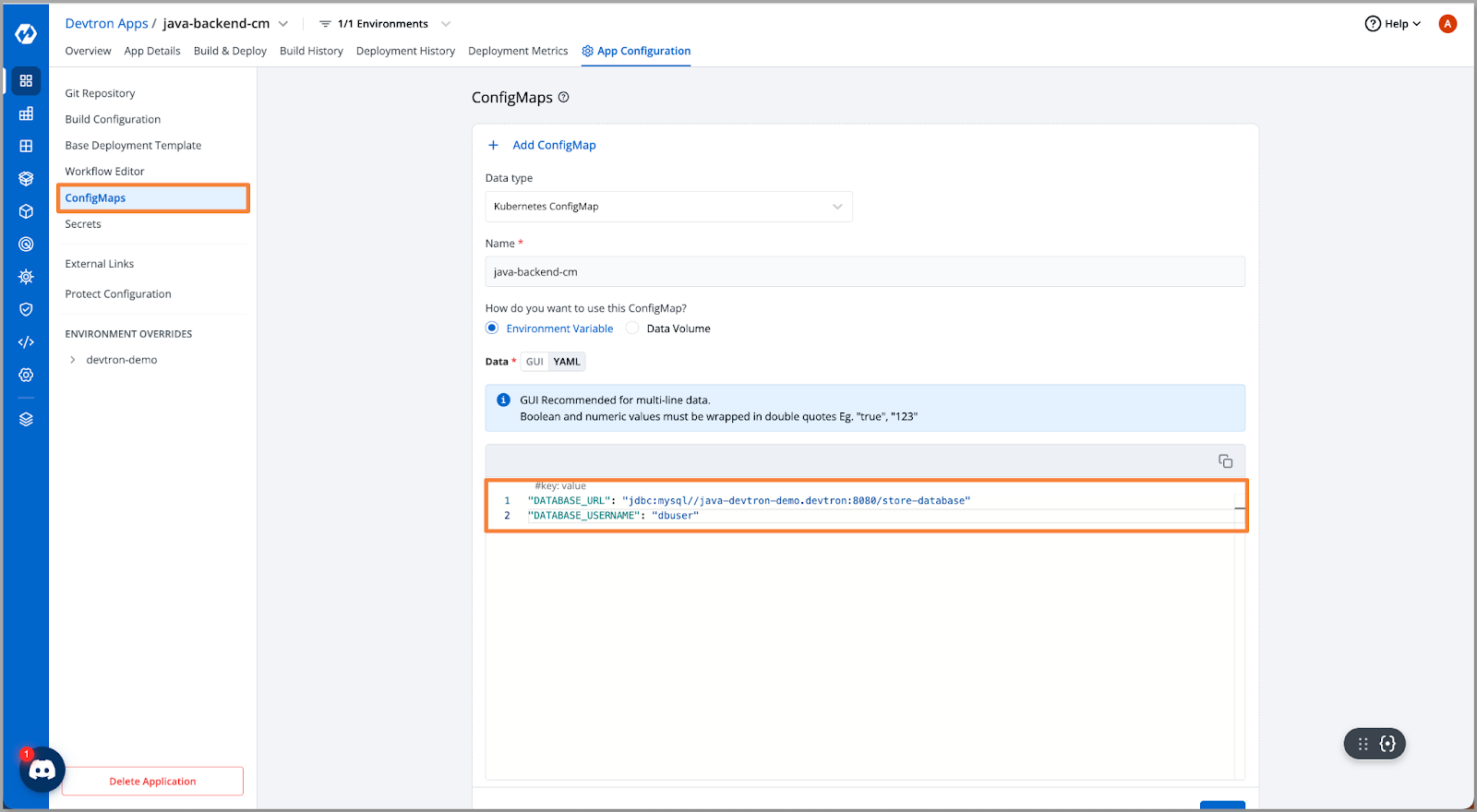
[Fig.12] Update ConfigMap
更新ConfigMap中的值后,我们重新部署了应用程序以验证修复。
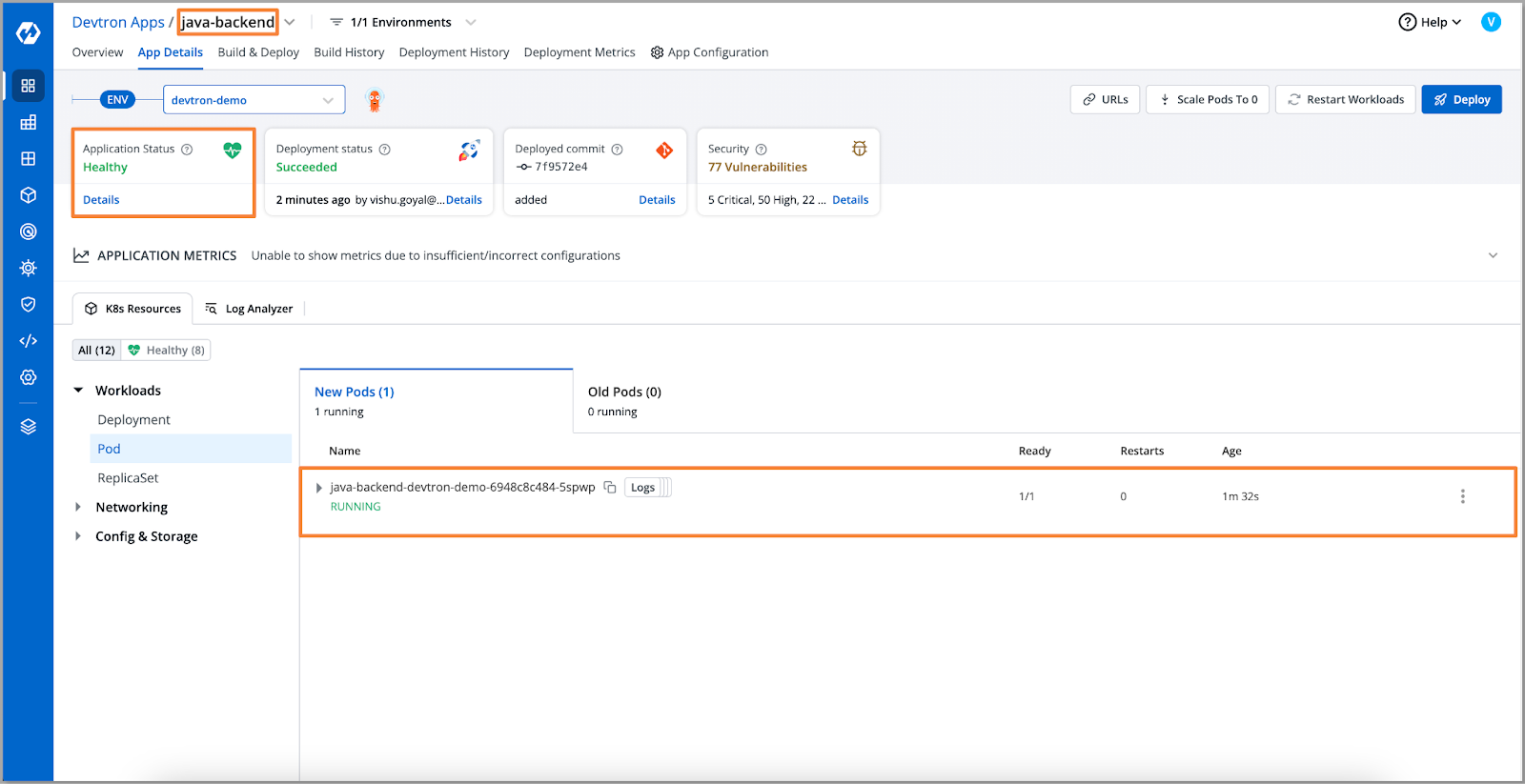
[Fig.13] Application in Running State
现在应用程序已启动并运行,让我们检查是否可以访问我们的数据。
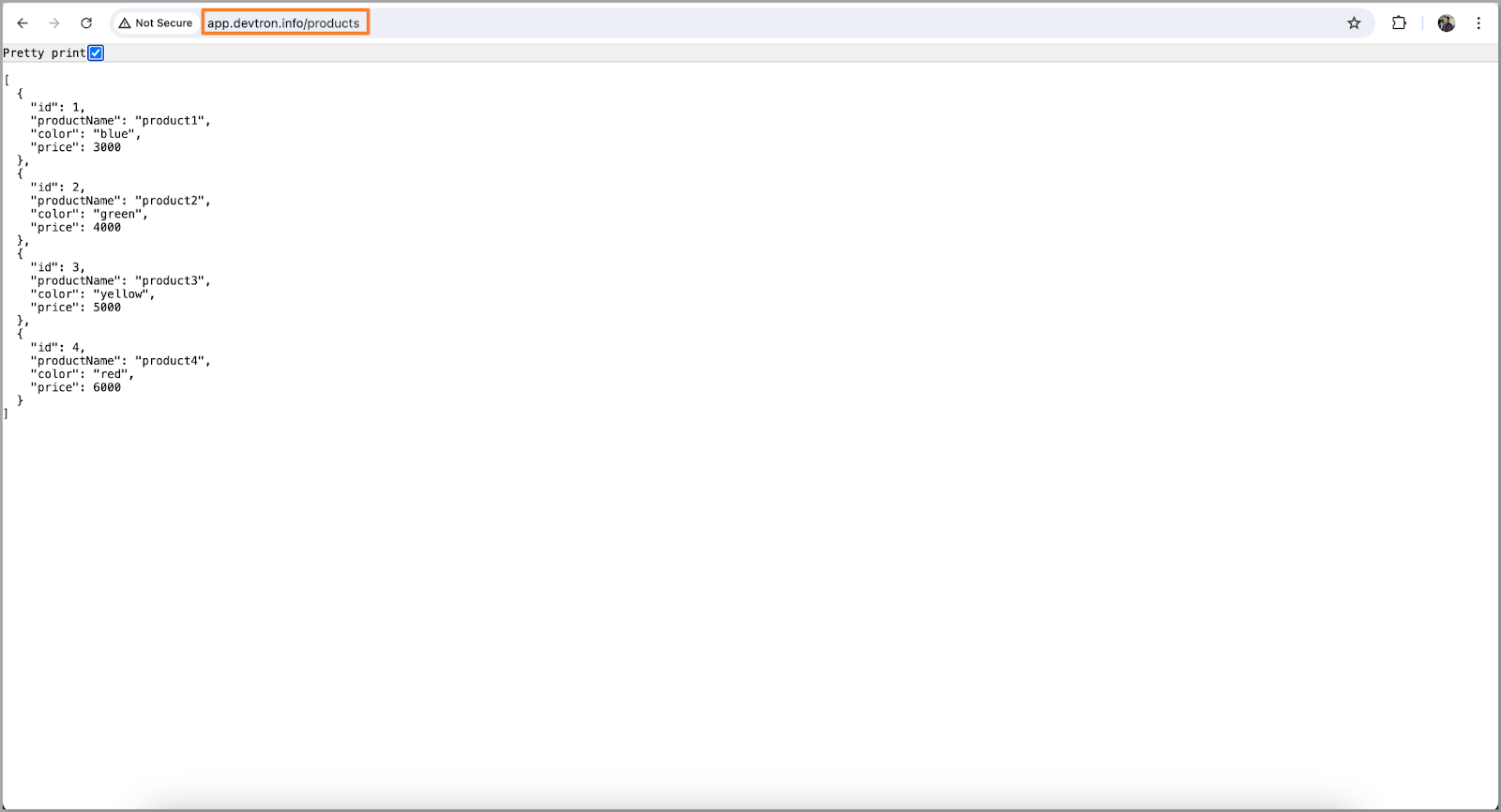
[Fig.14] Successfully deployed application
“数据库连接问题”是指建立或维护与数据库连接的问题。此问题可能由于各种原因发生,例如数据库凭据错误、网络问题、数据库服务器停机或数据库设置错误配置。
让我们看看如何在Devtron中为我们的应用程序排除数据库连接问题:
- 为了调查数据库连接问题,我们将在应用程序pod上通过Devtron部署一个临时容器。启动后,我们将使用telnet命令测试数据库连接。
- 要启动临时容器,请导航到 Pod > 终端 > 启动临时容器
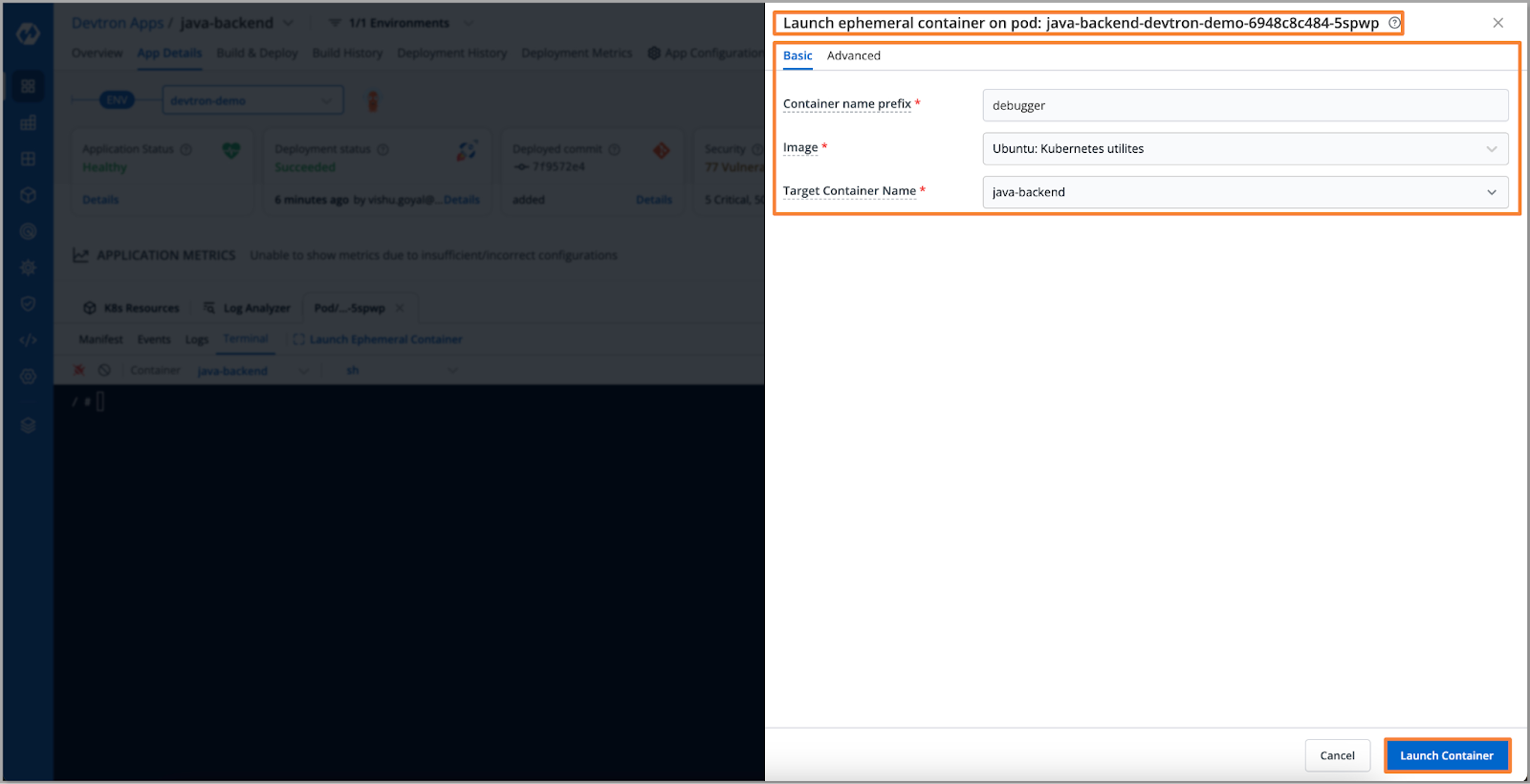
[Fig.15] Launch Ephemeral Container
执行telnet命令后,我们收到“连接被拒绝”错误,表明无法连接到远程主机(我们的数据库)。

[Fig.16] Check Database connectivity
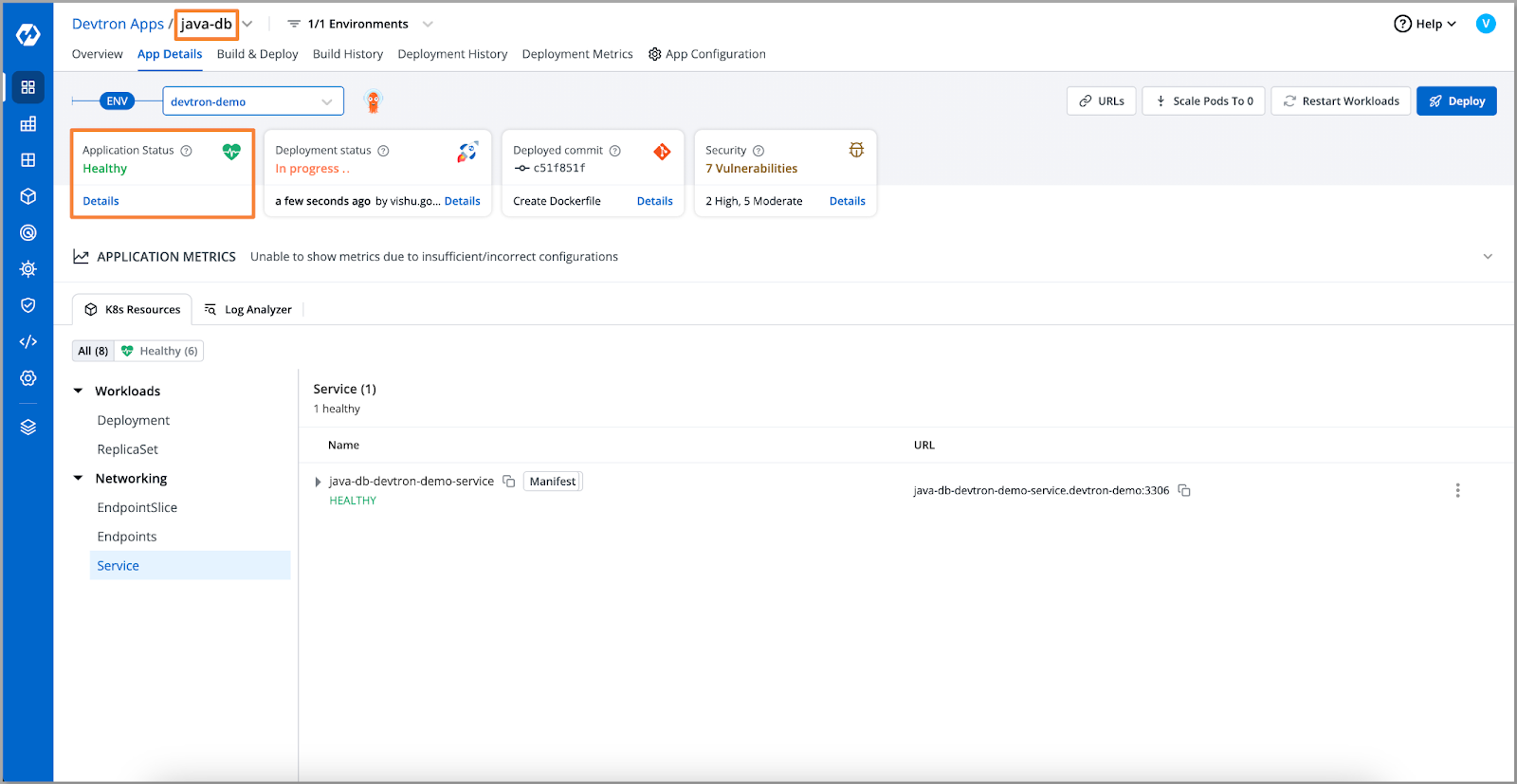
让我们看看我们的数据库,在这里我们可以看到我们的应用程序的数据库处于休眠状态。因此,连接被拒绝的原因是数据库休眠。
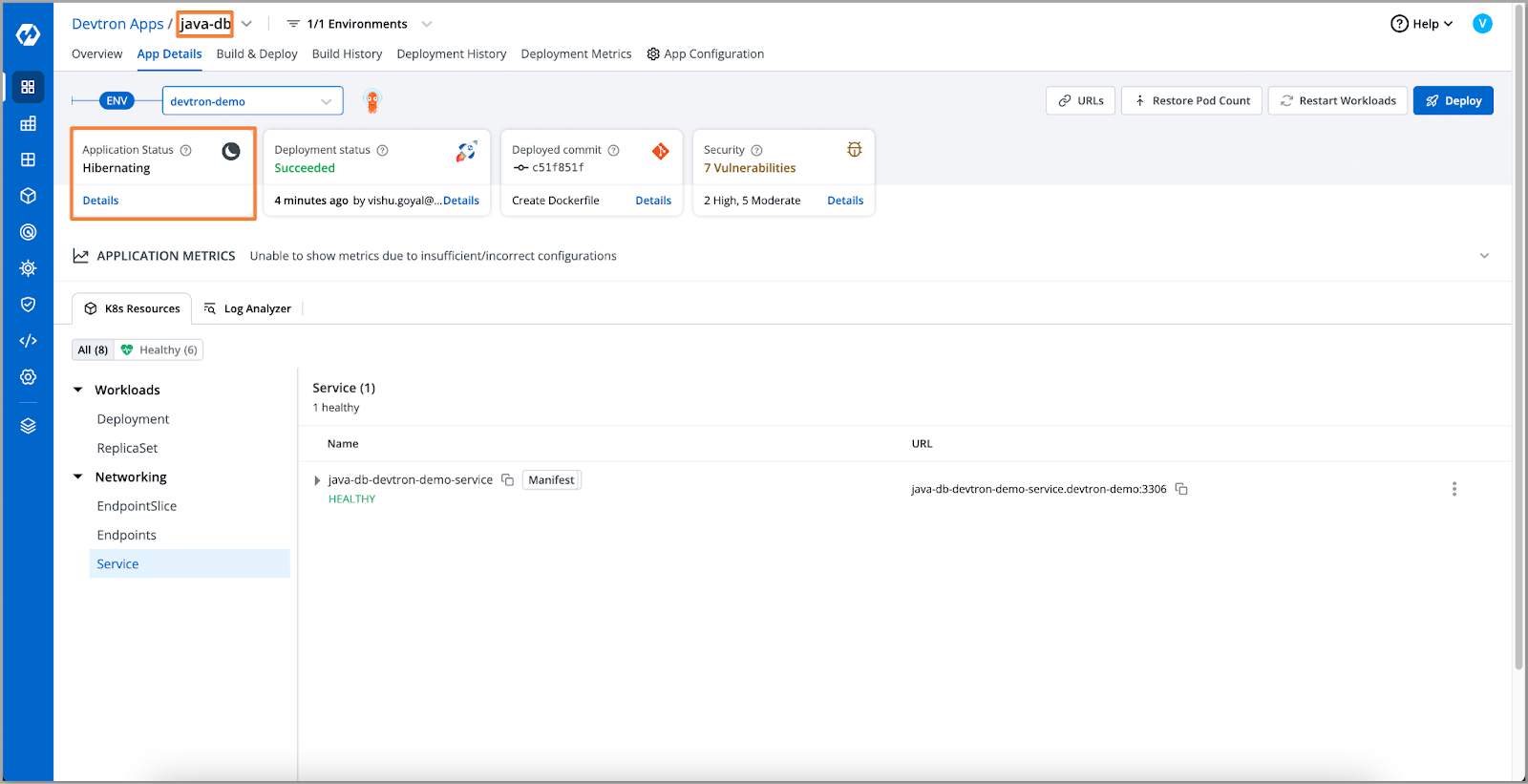
[Fig.17] Application in Hibernation
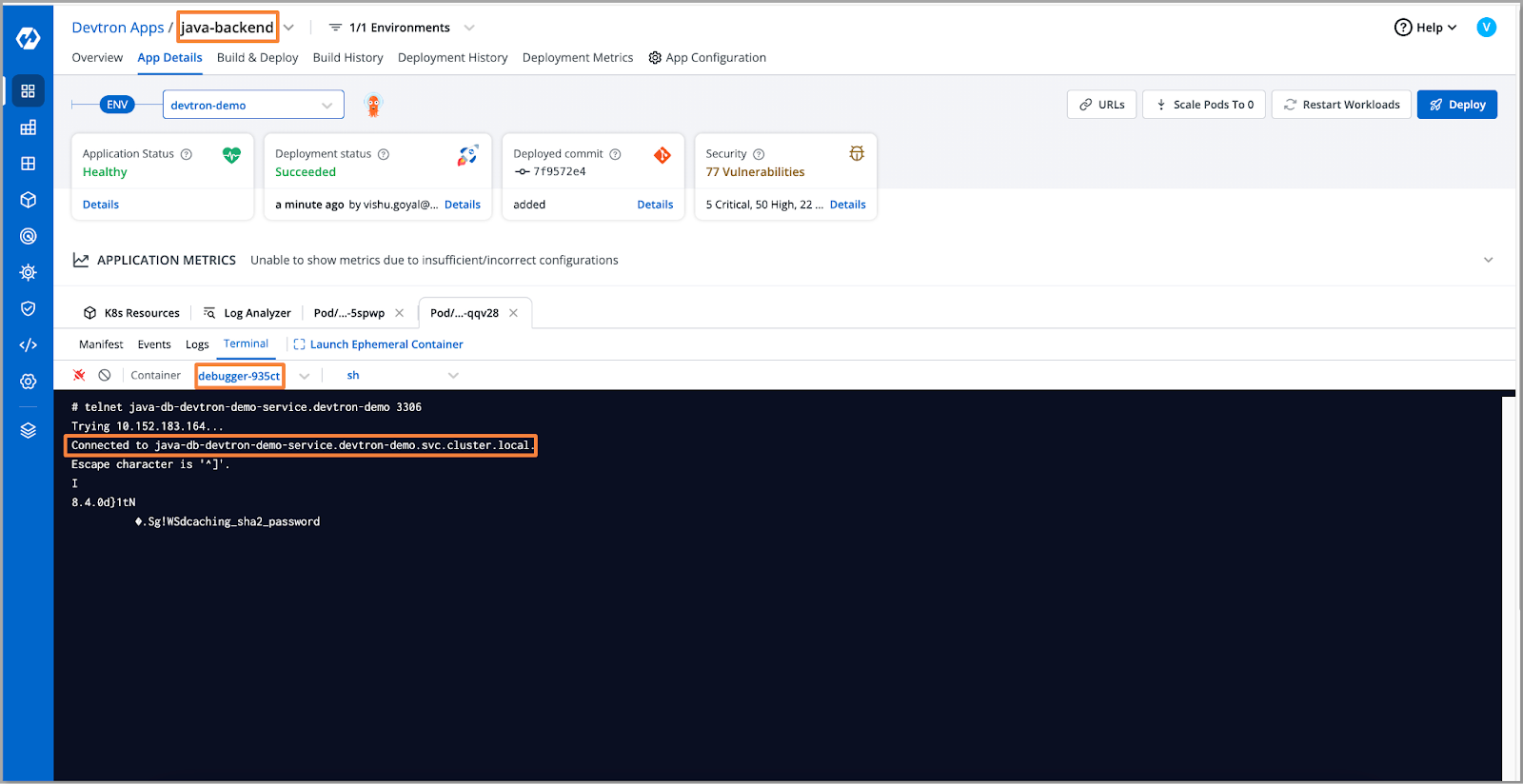
为了解决这个问题,我们将扩展数据库pod。我们将使用临时容器上的telnet命令重新测试连接。
[Fig.18] Application in Healthy State
重新测试数据库连接后,我们可以看到它已成功连接。
[Fig.19] Checking Database Connectivity
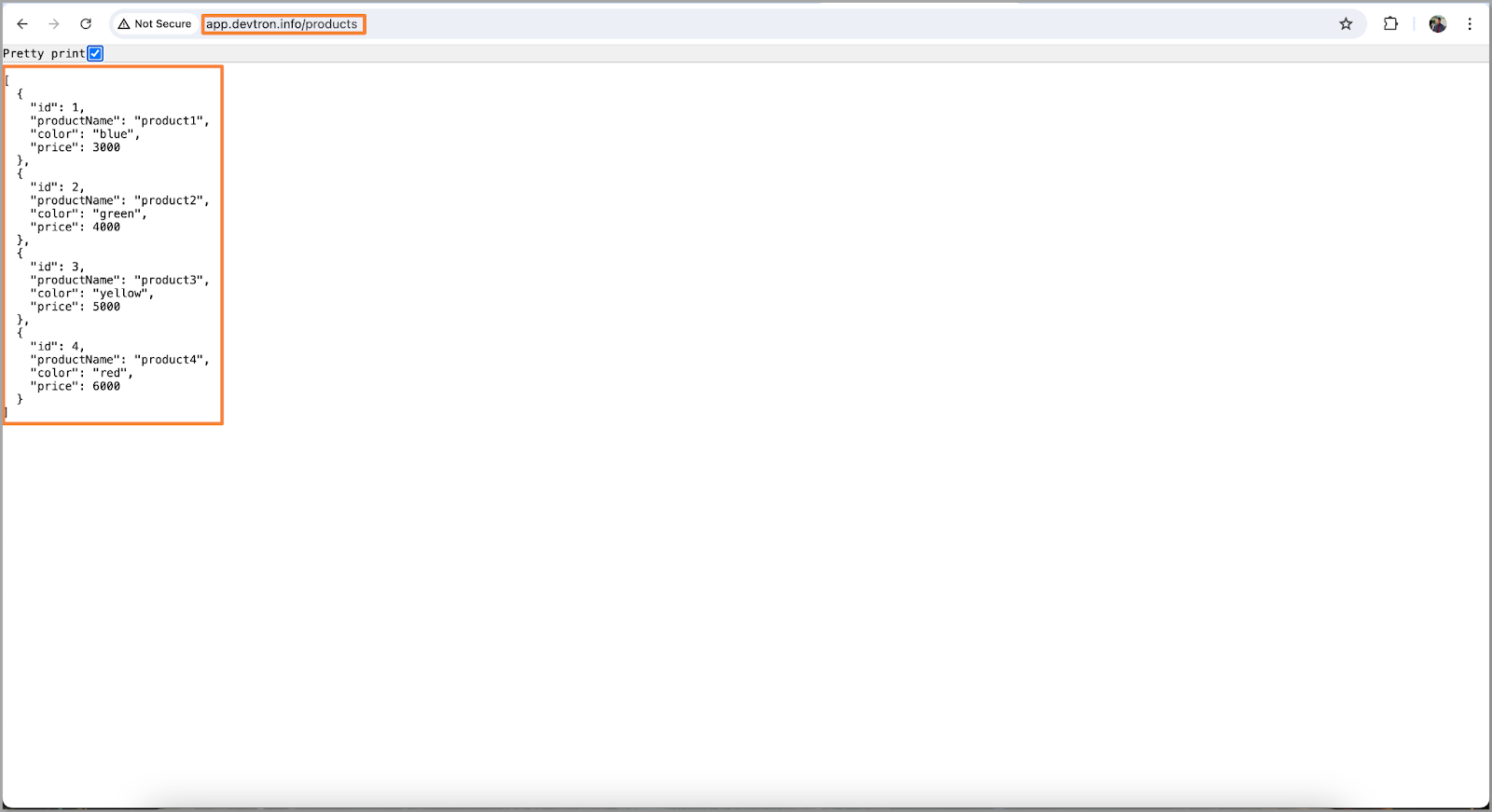
数据库连接问题也已解决,我们的应用程序也已启动并运行。我们应该能够获取数据。
[Fig.20] Successfully accessing application
调试 Kubernetes 一直是一项复杂的任务,涉及多个上下文切换和复杂的命令导航。Devtron 简化了此过程,通过直观的仪表板提供 Kubernetes 环境的全面视图,使调试和管理 Kubernetes 更轻松。Devtron 充当 Kubernetes 生态系统的中心枢纽,以及大多数事情都在其中处理的直观仪表板,Devtron 提供对集群和 Pod 终端的访问,用户可以在其中执行各种操作,例如编辑实时清单、查看当前清单、检查事件、下载文件和监控日志。借助 Devtron,Kubernetes 的故障排除变得更加直接,因为与命令行工具作斗争的繁琐过程被抽象化了。为了进一步增强故障排除功能,Devtron 的一个功能 Resource Watcher 会自动修复 Kubernetes 问题,从而提供额外的优势。在即将发布的关于 Kubernetes 系列故障排除的博客中,我们将探讨 Kubernetes 世界中的一些更常见的问题以及如何通过 Devtron 来处理这些问题。