Kubernetes 非常适合各种类型的容器化工作负载,从服务到作业再到有状态应用程序。但是 AI 和需要 GPU 的机器学习工作负载呢?是的,Kubernetes 也支持这些,但有很多细微差别。
译自 Optimizing AI and Machine Learning Workloads in Kubernetes,作者 Eugene Burd 。
本文将介绍 Kubernetes 如何支持 GPU,包括调度、过度订阅和时间共享以及安全性/隔离。此外,我们将讨论三大公共云提供商如何支持这些功能,以及如何确保您的 GPU 节点仅由 GPU 工作负载使用。
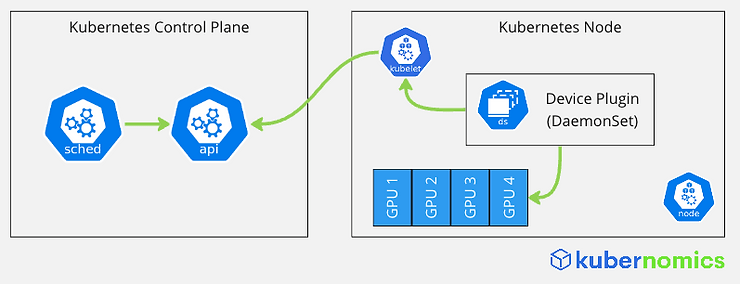
让我们首先看一下 Kubernetes 支持 GPU 的机制。Kubernetes 本身不知道任何关于 GPU 的信息。相反,它提供了一个扩展机制,称为设备插件。设备插件框架允许第三方广告节点上可用的其他功能,如 GPU、InfiniBand 适配器等。
设备插件,通常以守护进程集实现,向节点的 kubelet 注册自己,并向 kubelet 广告节点上可调度的资源。Kubelet 将此信息传递给 API 服务器,然后由 Kubernetes 调度程序使用,以调度请求每个容器的资源的工作负载到节点上。

既然我们了解了 Kubernetes 如何知道 GPU,那么让我们来讨论容器如何请求一个 GPU。工作负载可以以类似请求 CPU 或内存的方式请求 GPU,但有些不同。与 Kubernetes 本身支持的 CPU 不同,GPU(和设备插件一般)仅支持限制(您可以提供请求,但如果这样做,您也必须提供限制,并且两个值必须相等)。限制还必须是整数(不允许使用小数限制)。
让我们看一个示例 pod。在本例中,pod 正在请求 1 个 Nvidia gpu。调度程序将尝试找到一个具有可用 Nvidia gpu 且尚未分配的节点,并继续在该节点上放置 pod。
apiVersion: v1
kind: Pod
metadata:
name: my-gpu-pod
spec:
containers:
- name: my-gpu-container
image: nvidia/cuda:11.0.3-runtime-ubuntu20.04
command: ["/bin/bash", "-c", "--"]
args: ["while true; do sleep 600; done;"]
resources:
requests:
cpu: 100m
memory: 500Mi
limits:
memory: 1000Mi
nvidia.com/gpu: 1CPU 时间共享由 CNI 使用 linux cgroups 本地处理。它受您的请求和限制的影响 - 请参阅有关如何设置 CPU 请求和限制的文章(以及为什么要避免限制)。
GPU 时间共享对于 Nvidia GPU 通过两种机制支持:
- 多实例 GPU(Nvidia A100、H100)支持多个计算和内存单元。在这种情况下,您可以配置要公开的分区数量。此配置驱动设备插件显示每个物理 GPU 的多个“虚拟 GPU”。这由 AWS、Azure 和 GCP 支持。
- 对于单实例 GPU,Nvidia 的 GPU 调度程序通过对 GPU 上的工作负载进行时间分片来支持时间共享。这只有 AWS 和 GCP 支持。
虽然这种方法意味着可以过度订阅 GPU,但您必须小心,因为您的工作负载可能会被饿死,与 CPU 不同,没有完全公平的调度程序(CFS),也没有 cgroup 优先级,因此时间只能由工作负载平等划分。
与 CPU 不同,当前 GPU 内没有进程或内存隔离。这意味着调度到 GPU 上的所有工作负载共享其内存,因此您只应在互相信任的工作负载之间共享 GPU。
既然我们已经知道如何请求 GPU,您可能想知道如何创建具有 GPU 的节点以及如何安装设备插件。这根据您使用的 kubernetes 提供商而有所不同,我们将在下面介绍 3 大提供商。
AWS 支持使用任何 EC2 GPU 实例类型创建节点组。您可以从两个选项中进行选择:
- 运行预装了 Nvidia 驱动程序的 EKS 加速的 Amazon Linux AMI 。在这种情况下,您需要自行单独安装 Nvidia 设备插件。
- 在节点组上运行 Nvidia 的 GPU Operator。在这种情况下,升级是手动的。
Azure 支持使用三种选项创建节点池:
- 创建 GPU 节点池,其中自动包括 GPU 驱动程序,但需要您自己安装 Nvidia 设备插件。
- 使用 AKS GPU 镜像预览,其中包括 GPU 驱动程序和 Nvidia 设备插件。在这种情况下,升级是手动的。
- 在节点组上运行 Nvidia 的 GPU Operator,它为您处理所有事项。
GKE 支持使用两种选项创建节点池。
- 让 google 管理 GPU 驱动程序安装以及设备插件。使用此选项还允许 GKE 自动升级节点。
- 自己管理 GPU 驱动程序和设备插件
最后,既然您已经创建了 GPU 节点,您会希望这些节点免受集群上运行的任何非 GPU 工作负载的影响。您可以通过污点和容忍来实现这一点。在创建节点池和组时,您会想要应用污点。 如果集群具有非 GPU 节点池,GKE 会自动为您执行此操作。其他提供商不会,所以您需要确保这样做。
对于 pod,您会希望为污点提供容忍,以便它们可以调度到 GPU 节点上。下面的示例为名为“nvidia.com/gpu”的污点创建了一个容忍,这允许此 pod 在 nvidia GPU 节点上运行。
apiVersion: v1
kind: Pod
metadata:
name: my-gpu-pod
spec:
containers:
- name: my-gpu-container
image: nvidia/cuda:11.0.3-runtime-ubuntu20.04
command: ["/bin/bash", "-c", "--"]
args: ["while true; do sleep 600; done;"]
resources:
requests:
cpu: 100m
memory: 500Mi
limits:
memory: 1000Mi
nvidia.com/gpu: 1
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"随着 AI 和机器学习工作负载的不断增长,希望您考虑在 Kubernetes 上运行它们,而不是更昂贵的云提供商专有选项。
您是否已经尝试在 Kubernetes 上运行 GPU 工作负载?哪些方面效果好?遇到哪些问题?