当您学会使用 eBPF 性能分析解锁详细洞察时,不可靠的数据将成为过去。了解如何细粒度且高效地监控 CPU、内存和网络数据。
译自 Unlock detailed insights with eBPF profiling. Monitor CPU, memory, and network data granularly. Say goodbye to unreliable data.,作者 Aviv Zohari。
传统的监控和可观测性工具就像估计手机剩余电池时间的算法:它们擅长跟踪手机(或服务器)总共使用了多少资源。它们还可以提供一些基本预测,比如您何时可能耗尽资源,并建议您可以进行的更改(例如关闭手机上的空闲应用,或者在可观测性的情况下将工作负载移动到不同的节点)以提高资源消耗效率。
但它们并不擅长提供详细、具体、细粒度的的数据。您的手机无法告诉您它将在何时何分耗尽电量。在大多数情况下,它甚至无法准确地告诉您哪些应用消耗了最多的电量。同样,传统的可观测性工具只会让您大致了解系统中发生的情况;它们不会生成详细的性能分析数据或见解。
幸运的是,有一种更好的方法:eBPF 性能分析。使用 eBPF,一种内置于现代 Linux 内核中的简洁小巧的技术,您可以对各种资源执行持续的性能分析。更好的是,基于 eBPF 的性能分析对您的应用程序施加的开销很小,因此您不会浪费大量内存和 CPU 来弄清楚内存和 CPU 发生了什么。
让我们通过引导您了解如何通过 eBPF 进行性能分析、为什么它有益以及如何开始使用 eBPF 作为传统性能分析工具的替代品来解释一下。
eBPF 性能分析是使用 eBPF 框架来收集有关 CPU、内存、网络数据和其他资源使用情况的细粒度数据。(如果您不熟悉 eBPF,请查看我们的博客文章,其中回答了“什么是 eBPF?”)
为了更详细地理解这意味着什么,让我们退一步来谈谈一般的性能分析。在监控和可观测性领域,性能分析是一种确定哪些资源被各个应用程序或进程消耗的方法。
因此,与其仅监控系统的总内存使用量或 CPU 利用率(您可以使用 Linux 工具(如 free 和 mpstat)来做到这一点),性能分析允许您确定特定进程或应用程序使用了多少内存、CPU 或其他资源。如果您想弄清楚某个应用或进程是否占用了超出其应有资源,或者识别出您应该迁移到不同节点以释放更多资源的工作负载,这些数据将派上用场——仅举两个您可能希望执行性能分析的示例。
大多数监控和可观测性工具默认情况下不会对应用程序和进程进行性能分析;它们只跟踪总资源消耗。但可以通过传统工具执行性能分析。例如,您可以在 Linux 中使用 top 命令来获取一些性能分析见解:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
74369 user 20 0 32.6g 76888 40264 S 6.0 0.5 25:43.84 slack
74393 user 20 0 1131.1g 254600 63572 S 4.7 1.6 17:06.80 slack
3392 root 20 0 4761140 59104 19700 S 2.3 0.4 115:59.39 kubelet
如您所见,在这种情况下,top 的输出报告了正在系统上运行的特定进程(在本例中为 slack 和 kubelet)的内存和 CPU 利用率级别。
top 等工具通过查看 Linux 文件系统的 /proc 目录来获取性能分析见解,操作系统在其中报告有关正在运行进程的数据。因此,它们不会对工作负载进行性能分析,而是提取 Linux 内核默认情况下提供的有关活动进程的有限数据。它们完全依赖于用户空间堆栈中可用的数据。
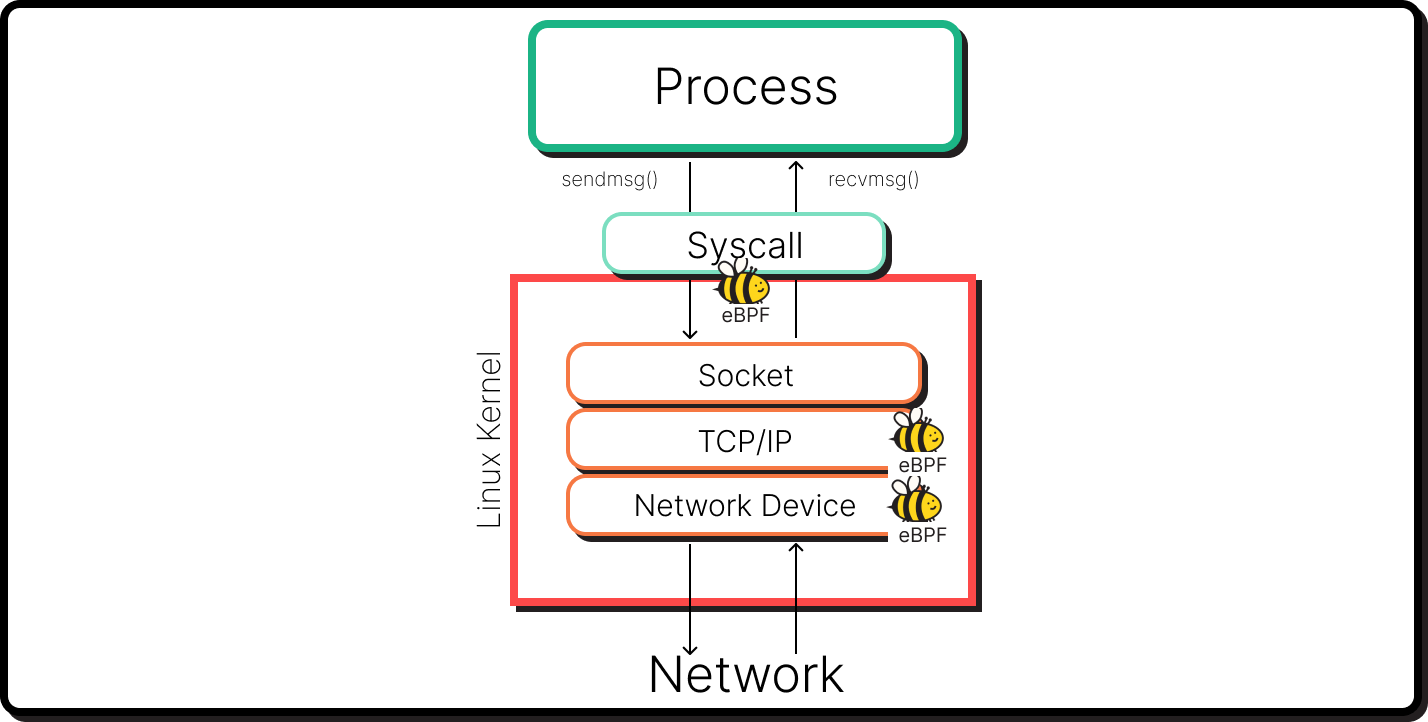
然而,使用 eBPF,一种不同的方法变得可行。eBPF 实际上可以通过监视堆栈跟踪直接对系统上运行的任何应用程序或进程执行性能分析。它可以通过在内核空间中运行的特殊程序来做到这一点,这使得性能分析比依赖于在用户空间中执行的请求要快得多。
eBPF 以低级方式与内核交互的能力意味着您可以使用eBPF 跟踪 框架来执行多种类型的性能分析。
下面是翻译并整理为 markdown 表格的内容:
| 描述 | eBPF如何做 | |
|---|---|---|
| CPU profiling | 监控个别进程的 CPU 使用情况。 | 分析堆栈跟踪进行性能分析。 |
| Memory profiling | 跟踪个别进程的内存分配和使用情况。 | 追踪内存事件和分配请求。 |
| Network profiling | 将网络流量映射到进程。 | 将数据包与进程关联。 |
作为一种 CPU 性能分析解决方案,eBPF 允许您监视堆栈跟踪以观察各个进程或应用程序的 CPU 利用率级别。如果您想跟踪哪些工作负载(或工作负载的哪些部分)消耗了最多的 CPU,并且可能剥夺了其他工作负载高效运行所需的计算资源,这将很有用。您还可以使用 CPU 性能分析来找出由于错误而消耗大量 CPU 的进程。
同样,您可以使用 eBPF 来分析单个进程或工作负载的内存分配和利用率。内存分析可帮助您确保内存正确分配到不同的工作负载之间。它还有助于解决内存泄漏等问题,当应用程序随着时间的推移消耗越来越多的内存时,通常是由于应用程序或微服务中的内存管理不善造成的。
您不仅可以使用 eBPF 分析内部资源。您还可以通过将进程或应用程序映射到各个数据包来跟踪与网络的连接。这种精细的网络可见性级别为解决网络性能问题(如高延迟率或丢包)提供了巨大的好处。它还可以帮助发现恶意网络请求,并让您了解工作负载如何对它们做出反应。
既然您知道了如何将 eBPF 用作分析工具,那么让我们来讨论一下为什么您要执行 eBPF 分析。
简单的答案是,基于 eBPF 的分析和堆栈跟踪监控是一种获取操作系统和工作负载内部发生情况的精细可见性的高效方式。通过分析各个进程和应用程序的资源消耗,您可以回答以下问题:
- 我的应用程序中哪个进程消耗的资源最多?
- 特定进程的资源消耗激增是否与我注意到的应用程序中的性能问题相关?
- 我是否有足够的 CPU、内存和其他资源来保持工作负载平稳运行?
- 我刚刚向集群添加了更多节点,并希望将一些应用程序迁移到这些节点。根据其资源消耗水平,哪些应用程序是迁移的最佳候选者?
当然,这只是 eBPF 分析有用的原因中的一部分。使用 eBPF,您可以回答您可能遇到的有关任何应用程序或进程的资源利用率状态或趋势的几乎任何问题。
我们在上面提到,您可以使用其他类型的监控和可观测性工具(例如,同样古老的 top 命令)来分析应用程序。那么,为什么您要使用 eBPF 进行分析呢?
答案是,使用 eBPF,您可以获得各种独特的好处。
由于 eBPF 程序在内核空间中运行,因此它们可以比在用户空间中运行的监控应用程序更有效地从内核中收集有关资源利用率的数据。因此,您可以减少用于分析的资源,并为实际工作负载消耗更多资源。
使用 eBPF,您可以编写自定义程序以高度可定制的方式收集分析数据。您不必局限于 /proc 中提供的通用信息。
因此,基于 eBPF 的分析为您提供了比传统方法更深入的可见性级别。
eBPF 程序在沙盒环境中运行,并且必须通过内核验证才能执行。这些控制将有缺陷的 eBPF 分析例程使系统面临风险的风险降至最低。
您可以在不修改内核或插入内核模块的情况下使用 eBPF 进行分析。只要您的节点运行的是 Linux 内核版本 4.16 或更高版本,那么 eBPF 就内置其中。(公平地说,一些 Linux 发行版默认安装了用户空间分析工具,但这与将分析功能直接内置到内核中不同。)
总体而言,值得注意的是,eBPF 作为一种分析解决方案并非没有挑战。
最大的挑战是编写和部署 eBPF 程序需要一些努力。您需要知道如何使用 C 等编译语言进行编码,并且您必须能够编译程序并将其加载到内核中,以便它们能够与 eBPF 交互(您还可以使用解释语言(如 Python)进行 eBPF 编程,但只能在包装器的帮助下)。如果您已经熟悉 Linux 和编程,那么学习如何执行这些操作并不是特别困难,但这个过程比运行不需要自定义编码或专门部署的传统监控工具更复杂。
eBPF 程序在运行前也必须经过验证,这是个特性,而非缺陷,因为(如上所述)验证有助于防止错误代码给系统造成问题。但这确实意味着你必须掌握 eBPF 验证过程的复杂性,以确保你的代码能够运行。
事实上,eBPF 仍然是一项相对较新的技术,并且仍在不断发展。因此,不同的内核版本提供了不同版本的 eBPF,并且 eBPF 程序在不同的内核上运行时可能略有不同。如果你想在预置了不同 Linux 版本的多个节点上使用 eBPF 进行分析,这可能会带来挑战。
在 Kubernetes 中利用 eBPF 作为分析解决方案的过程很简单。归结为:
- 确保集群中的每个节点都预置了支持 eBPF 的 Linux 内核。
- 在每个节点上部署 eBPF 代理以收集持续分析数据。
- 将数据推送到分析工具,以便理解数据。
此过程的确切步骤将根据你想要收集的分析数据以及你用来与框架交互的 eBPF 代理而有所不同。但作为一个示例,这里有一个在 Ubuntu 上使用 eBPF 进行 CPU 分析的简单方法。(此示例假定你的 Kubernetes 节点预置了 Ubuntu 20.04 或更高版本。)
首先,安装 bpfcc-tools 0.12.0-02 或更高版本:
sudo apt-get install bpfcc-tools此软件包提供了一个名为 profile 的工具,该工具通过 eBPF 分析 CPU 利用率。
接下来,运行该工具以收集分析数据:
profile如果你不传递任何参数,profile 将持续分析来自整个系统的堆栈跟踪,并在命令行上打印分析和跟踪数据。如果你想分析特定进程或控制分析频率,请查看该工具的手册页以了解适当的 CLI 参数。
要将数据移动到可以分析它的位置,你可以将 profile 的输出重定向到文件或数据流:
profile > /some/file然后,在所选的分析或可视化工具中聚合数据以理解数据。
这是一个使用 eBPF 进行分析的非常基本的示例。对于更复杂的使用案例,你可能希望编写自己的自定义 eBPF 程序,而不是依赖于通用工具(如 profile),它无法对收集哪些数据以及如何收集数据提供太多控制。
但是,如果你只是想寻找一种快速简便的方法来在 Kubernetes 中使用 eBPF 进行分析,那么我们刚才介绍的方法就可以完成这项工作。
作为部署自己的 eBPF 代理和手动管理分析数据的替代方案,你还可以使用 groundcover,它利用底层的 eBPF 来监视堆栈跟踪并收集此数据。使用 groundcover,你可以获得基于 eBPF 的分析效率,而无需设置和管理自己的工具。
eBPF 并不是收集分析数据的唯一方法,但它比传统分析方法更高效、更安全。eBPF 可以让你以更低的开销获得更多数据,并且导致服务器出现问题的风险更低。如果你尚未转向 eBPF 作为提升分析方法的一种方式,现在是时候了。