从集群创建到工作负载就绪,自动化每一步。
译自 Managing 100s of Kubernetes Clusters using Cluster API,作者 CSS Engineering。
由核心基础设施团队成员 Zain Malik 和 Nibir Bora 撰写。
在 City Storage Systems,我们的核心基础设施团队驾驭着管理 100 多个多租户 Kubernetes 集群的复杂性,每个集群每天托管数万个活动 Pod。我们的整个软件堆栈在 Kubernetes 上运行,从关键任务微服务到有状态数据库和可观测性解决方案。
这篇博文深入探讨了我们在集群配置、生命周期管理和升级中实现完全自动化的历程。借助新的工具集,我们将配置和准备工作负载就绪集群所需的时间从 1.5 周缩短到不到 1 天,同时保持精简的工程师团队。这种转型是由我们在几个月内迁移到 Microsoft Azure 的战略决策催化的。在过渡期间,我们运营的集群数量增加了一倍以上。
我们提供了一组 Kubernetes 自定义资源 和 Operator,对我们的基础设施和相关操作进行建模。Kubernetes 运营商模式的灵活性使这种方法极其强大,我们相信它可用于管理任何公有云提供商上的集群。
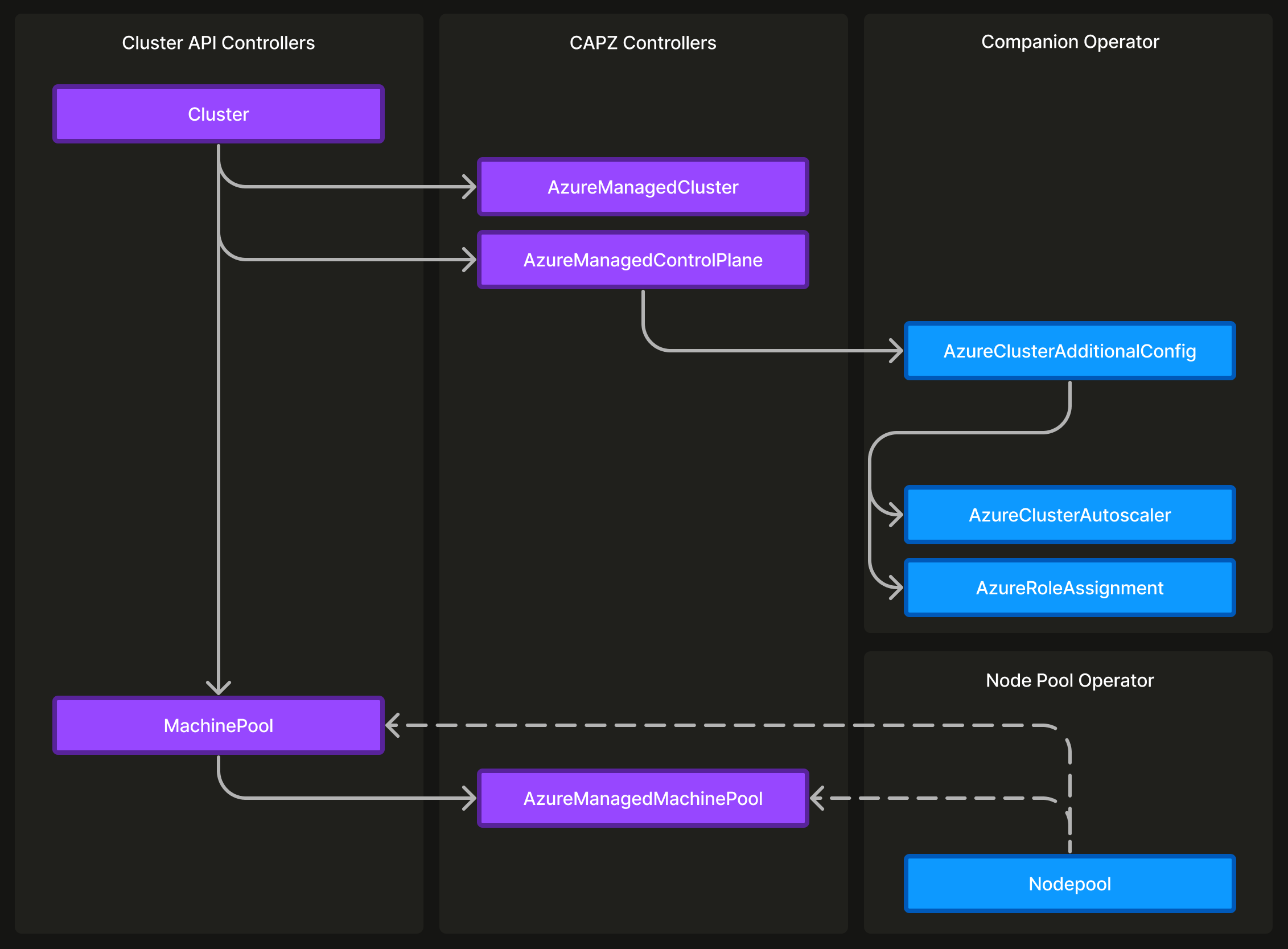
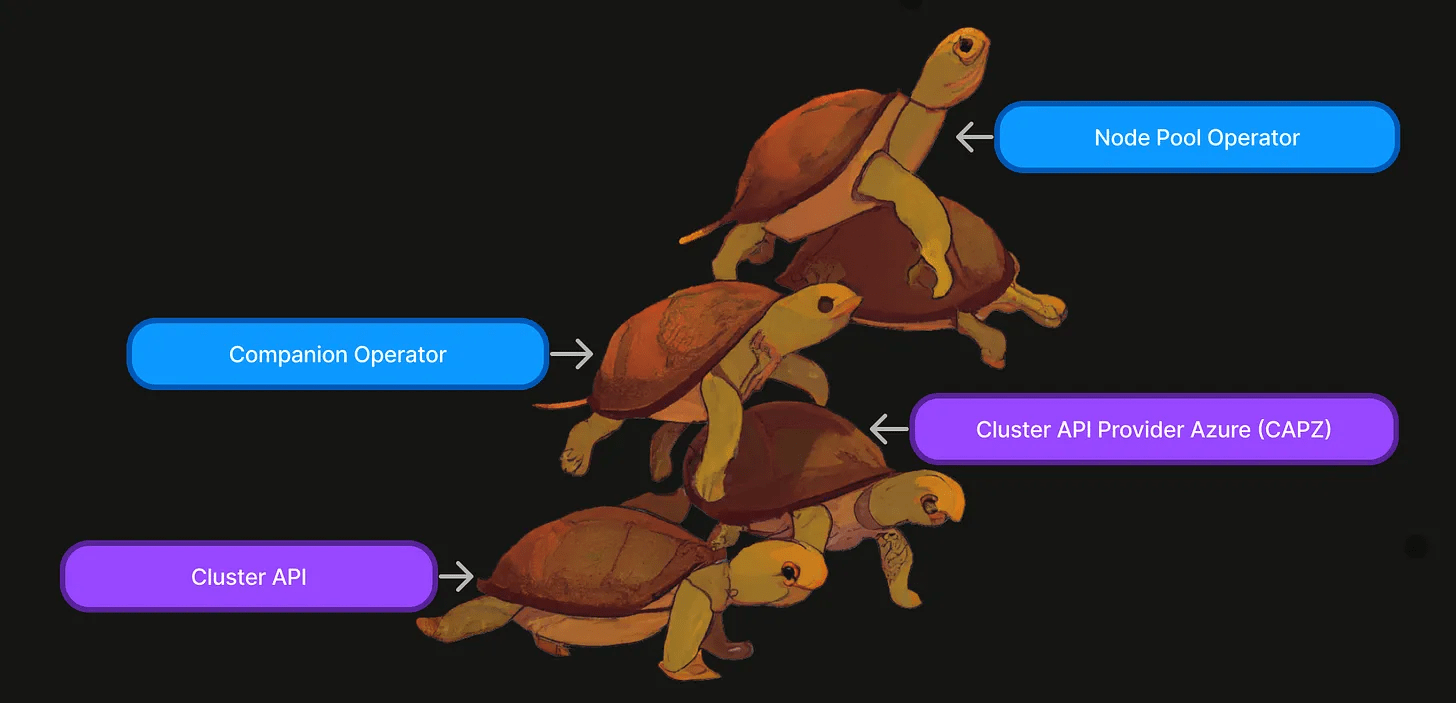
图 1:用于管理 Kubernetes 集群和节点池的所有自定义资源的层次结构。
我们最初使用 Terraform 创建集群,然后使用自定义内部 Kubernetes 运营商管理节点池。包括 Kubernetes 版本升级在内的更改是通过 GitOps 处理的。然而,所需的认知开销和手动干预使得这种方法不可持续,特别是将 80 多个集群从一个云提供商迁移到另一个云提供商。
这促使我们探索 Cluster API,它提供声明性 API,用于简化多个 Kubernetes 集群的配置、升级和管理。两个关键因素使Cluster API 特别有吸引力:
- 可扩展性: Cluster API 的自定义资源由提供商自定义资源扩展,然后可以由捕获组织需求的更高级别自定义资源扩展。由于我们的集群是多租户的,这使我们能够从工作负载开发人员那里抽象出有关节点池的任何详细信息。
- Operator 模式: Cluster API 及其提供商的任何扩展都是 Kubernetes Operator,与我们以 Kubernetes 为中心的管理基础设施的方法保持一致。利用我们团队构建运营商的经验,学习曲线很小。
要使用 Cluster API 和适用于 Azure 的 Cluster API 提供商 (CAPZ) 创建集群,我们只需创建以下自定义资源的对象:
- Cluster(来自 Cluster API)
- AzureManagedCluster 和 AzureManagedControlPlane(来自 CAPZ)
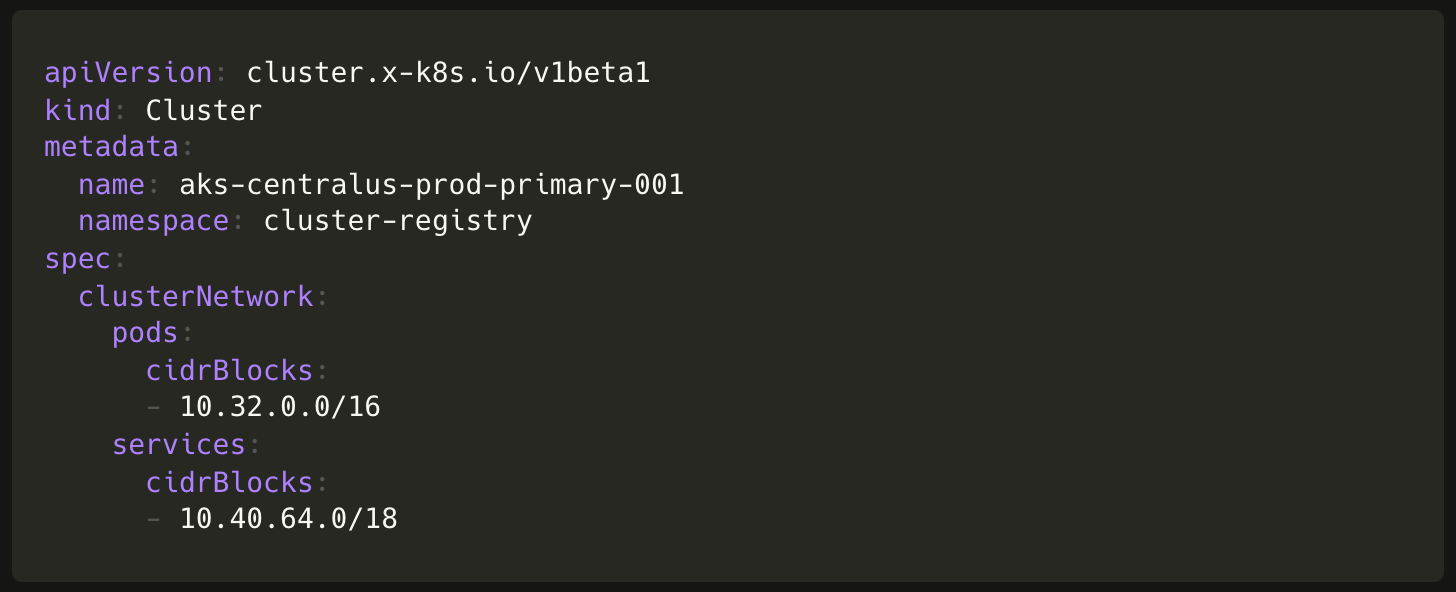


类似地,要创建节点池,我们需要创建以下自定义资源的对象:
- MachinePool(来自Cluster API)
- AzureManagedMachinePool(来自 CAPZ)


我们能够将这些流程无缝集成到我们现有的 CI 流水线中,完全依赖 GitOps 进行集群管理。我们不使用 Cluster API 提供的 clusterctl CLI。
但是,立即采用 Cluster API 有三个主要障碍:
- Cluster API 中对托管 Kubernetes 发行版的支持有限。尽管这是Cluster API 路线图的一部分,但所做的工作主要集中在自管理 Kubernetes 上。
- CAPZ 对托管 Kubernetes 发行版 Azure Kubernetes Service (AKS) 的支持仍处于实验阶段,缺少我们用例所需的基本功能。
- 没有主要的工程组织将 Cluster API 用于 AKS(至少在我们当时所知)。
我们依靠与 Microsoft Azure 的合作关系来找到前进的道路。他们建议我们在开源中协作 CAPZ 项目以实现功能完整性。Microsoft AKS 团队的几名工程师以及我们核心基础设施团队的工程师为 CAPZ 项目做出了贡献,优先考虑与我们的生产用例相一致的功能。这种合作取得了巨大的成功。它使我们能够在三个月内使用 Cluster API 和 CAPZ 启动我们的第一个 Kubernetes 集群。
虽然Cluster API 和 CAPZ 简化了集群创建,但这些集群尚未为工作负载做好准备。
- 新集群无权访问 Azure 容器注册表 (ACR) 中的容器映像。将此类依赖项排除在Cluster API 之外以保持界面的通用性是一种合理的设计选择。
- AKS 集群配置了默认集群自动扩缩器配置文件。可以通过手动运行 Azure CLI 命令来配置除默认值之外的任何内容。我们调整集群自动扩缩器以实现资源优化和对所有生产集群进行双箱填充。
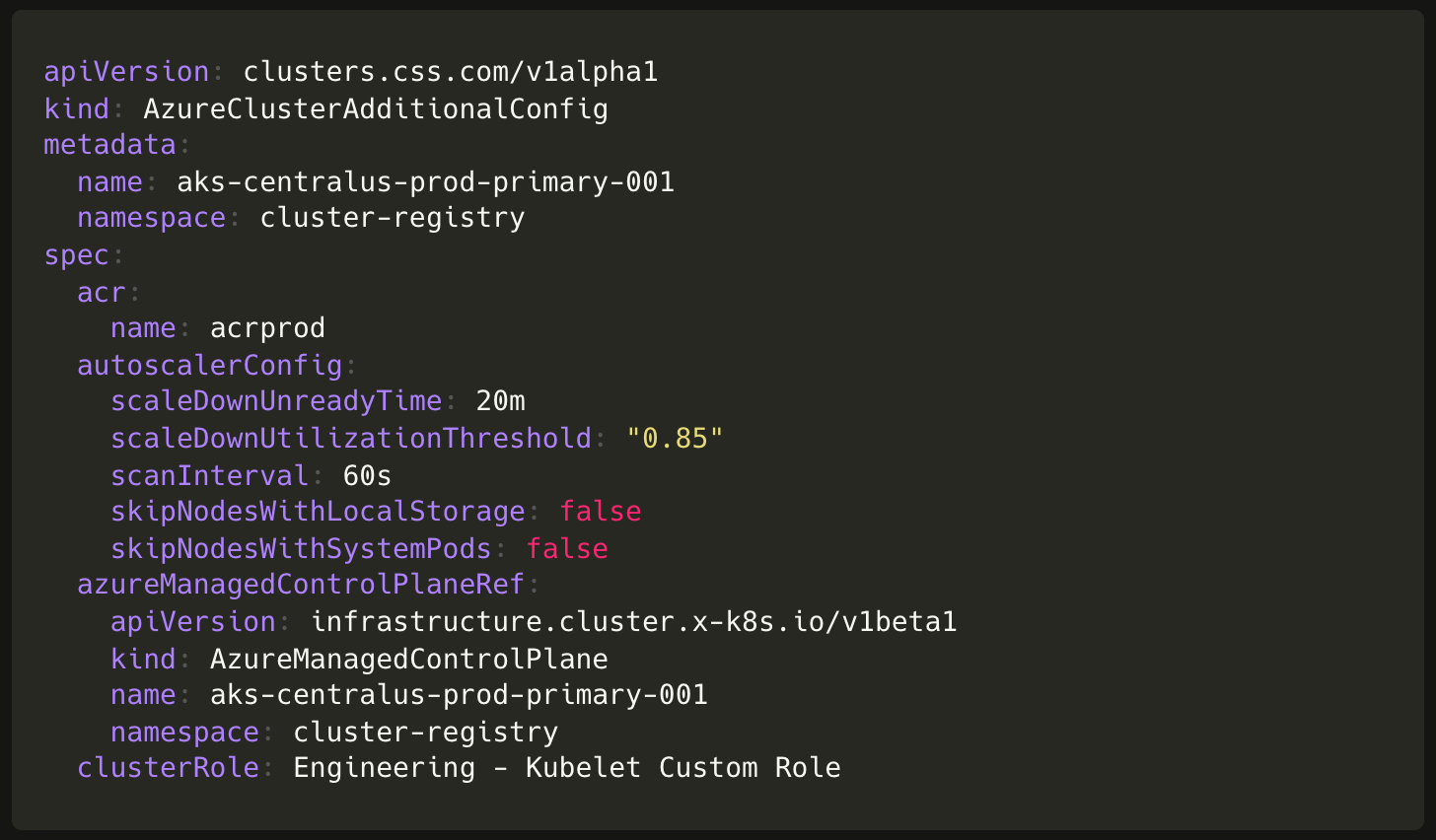
使用 Terraform 并运行 Azure CLI 命令为每个集群配置这些内容与我们最大程度减少人工干预的原则不符。因此,我们决定编写一个配套的 Kubernetes 运算符。这引入了 AzureClusterAdditionalConfig,这是一个可扩展的自定义资源,适用于集群所需的任何其他 Azure 托管服务配置。对于 ACR 权限,这会解析为 AzureRoleAssignment 对象,以及用于自定义集群自动扩缩器配置的 AzureClusterAutoscaler 对象。


引入配套 operator 使我们能够通过使用 GitOps 安装单个 Kubernetes 资源来完全自动执行集群创建,并准备它们以支持工作负载。这种简化的方式促进了 80 多个生产集群在不同云提供商之间的迁移。
在新的云提供商上运行生产工作负载几个月后,我们发现了两个主要的运营痛点。
- 我们没有在第一次尝试中确定节点类型(实例系列、磁盘类型等设置)。其中一些字段(如 machineType、diskSize、diskType、maxPod、type(抢占式与常规))是 AKS 上不可变的字段。这意味着我们不得不多次替换运行生产工作负载的节点池。每次替换都涉及创建新的节点池、清空旧节点池,然后删除它。此过程需要人工协调和 GitOps 工作流中的多个步骤。
- 在更新 Kubernetes 版本时,我们了解到 AKS 的就地节点池升级在遇到不允许任何中断的应用程序(PodDisruptionBudget 设置)时往往会进入无限重试循环。由于 AKS 仅允许每个集群一个并发节点池更新操作,因此这会阻止其他节点池上的操作,包括手动扩展。因此,我们也不得不采用多步骤节点池替换过程进行升级。
我们实现了一个节点池 Kubernetes operator,它引入了一个封装了替换节点池多步骤过程的 Nodepool 资源。在后台,该运算符会创建一个新的节点池、清空旧节点池,然后在对用户完全不透明的过程中删除它。从用户的角度来看,所有节点池操作都是通过单个 GitOps 更改就地完成的。这种端到端自动化在 Kubernetes 版本升级期间尤其强大。

唯一的限制是,我们无法使用 ownerReference 将新的 Nodepool 资源链接到 Cluster API 的 MachinePool 或 CAPZ 的 AzureManagedMachinePool 资源的现有层次结构。相反,这些资源并排存在,并使用 objectReference 链接。在完全删除节点池时,此缺点变得明显,因为资源层次结构是使用 finalizers 删除的。

图 2:完整的集群管理堆栈。
不断发展的集群管理工具链使我们能够管理两倍数量的集群和应用程序,同时维持核心基础设施团队中相同数量的工程师。这一成就标志着运营效率的显着提升,这得益于我们对 GitOps 原则的坚定承诺和消除人工干预过程。沿着同样的思路,自修复、漂移检测等是我们平台上的首要理念。这种思维方式使我们始终能够优先考虑组织需求,同时平衡效率、可靠性和敏捷性,利用 Kubernetes 的可扩展性。
回顾我们的历程,我们有一些关键的收获和失误:
- 大胆的豪赌:当我们探索集群管理的行业最先进技术时,我们找不到任何符合我们所追求的自动化水平的内容。在这样的时刻,我们依靠公司的核心价值观 - 大胆的豪赌。从长远来看,对Cluster API 的押注是富有成效的。
- 开源的隐藏成本:战略合作伙伴关系和推动适当的社区参与对于使我们的开源协作取得成功至关重要。我们确实了解到,长期承诺对于能够有效地引导开源项目以继续满足我们的需求是必要的。在可预见的未来,我们仍致力于为Cluster API 做出贡献。
- 早期采用者的风险:我们经历了一次持续数小时的 Sev1 事件,其中生产集群上的 60% 节点被清除。我们将其追溯到 CAPZ 中的一个错误,其中仅使用序列号后缀来标识节点,而不是使用完整spec.providerID。这导致Cluster API 使用相同 ID 在集群内引用来自不同节点池的节点,进而删除它们。
- 自动化增强可靠性:尽管不是主要重点,但我们的自动化工作显著提高了系统可靠性。我们已成功完成了 4 次无故障 Kubernetes 版本升级。以前,每个版本升级至少都会发生一次故障。
- Kubernetes Operator 模式:我们在基础设施组织中广泛利用 Kubernetes Operator。遵循目标状态协调等标准设计模式使我们能够避开设计争论,减轻对极端情况的担忧,并最大程度地减少学习曲线。这以及专门使用托管 Kubernetes 发行版对我们来说是正确的权衡。我们至今仍致力于这种方法。
那么,我们未来有什么计划?我们已经启动了一项战略计划,以使我们达到下一个规模水平。这涉及自动分区工作负载集群,考虑 API 服务器压力和节点大小等因素。我们还开始配置更多单租户集群。此外,正在努力简化准备工作负载就绪集群所需的时间,包括 IP 地址分配和安装集群附加组件等步骤。所有这些举措都以最大程度地减少人为干预和实现完全自动化为指导。通过此路线图,我们旨在熟练地高效管理 500 多个 Kubernetes 集群。
我们要感谢 Microsoft 的 Cécile Robert-Michon、David Tesar 和 Jack Francis。每个人都在项目的不同阶段做出了贡献。