
在这篇文章中,我们将探讨如何将大型语言模型 (LLM) 与关系数据库相结合,使用户能够以自然的方式询问有关其数据的问题。它演示了一个使用 Go 构建的检索增强生成 (RAG) 系统,该系统利用 PostgreSQL 和 pgvector 进行数据存储和检索。提供的代码展示了核心功能。以下是该
译自 Building a RAG for tabular data in Go with PostgreSQL & Gemini,作者 Paolo Galeone。
大型语言模型 (LLM) 非常适合处理非结构化数据。到目前为止,尽管结构化数据无处不在,但尚未深入探索它们与结构化数据的用法。让 LLM 能够与关系数据库交互可能是一个有趣的想法,因为它将解锁让用户“与数据聊天”的可能性,并让 LLM 发现数据湖中的关系。
在本文中,我们将探讨 Gemini(Google 开发的多模态大型语言模型)与 PostgreSQL 的可能集成,以及如何构建检索增强生成 (RAG) 系统以在结构化数据中导航。所有操作都将使用 Go 编程语言完成。这是关于在 Go 中使用 Vertex AI 系列的第四篇文章,因此它将与这两篇文章中介绍的相同先决条件相同:服务帐户创建、环境变量等。可以在每篇文章中阅读先决条件部分。
- 使用 Vertex AI 在 Google Cloud 上进行自定义模型训练和部署(使用 Go)
- Vertex AI 中用于表格数据的 AutoML 管道(使用 Go)
- 在 Go 应用程序中使用 Gemini:限制和详细信息
本文试图实现上一篇文章末尾提出的想法。鉴于将所有用户数据转换为文本表示会超出 Gemini 的最大上下文长度,我们实现了一个 RAG 来克服此限制。
在进入 PostgreSQL、Go 和 Gemini(通过 Vertex AI)的实现之前,我们需要了解 RAG 系统的工作原理。将其比作侦探在大量文档档案中搜索线索非常恰当。在 RAG 中,我们有三个组件:
- 侦探:这是一个生成模型,如 Gemini,它利用其知识来回答你的问题或完成任务。
- 档案:这是你的 PostgreSQL 数据库,其中包含所有表格数据(你的文档)。
- 线人:这是一个检索器,一个特殊的工具,它既能理解你的问题,又能理解档案中的数据。它就像你的线人,扫描档案以查找与侦探最相关的文档(线索)。
如何知道哪些文档是相关的?这就是嵌入的用武之地。嵌入就像信息的浓缩摘要。想象一下,每篇文档和你的问题都被缩小成一组唯一的数字。这些数字在空间中的距离越近,它们的含义就越相似。
线人使用嵌入技术将你的问题的嵌入与档案中所有文档的嵌入进行比较。然后,它检索嵌入最相似的文档,实质上是为侦探指明了正确的方向。
有了这些相关的文档,侦探(生成模型)就可以分析它们并利用其知识来回答你的问题或完成你的请求。
鉴于此结构,我们需要:
- 侦探:在我们的案例中,它将是通过 Vertex AI 使用的 Gemini。
- 嵌入模型:一个能够从文档创建嵌入的模型。
- 档案:PostgreSQL。我们需要转换数据库中的结构化信息为嵌入模型有效的格式。然后将嵌入存储在数据库中。
- 线人:pgvector。PostgreSQL 的开源向量相似性搜索扩展。
嵌入模型只能创建文档的嵌入。因此,我们需要找到一种方法将结构化表示转换为文档作为第一步。
LLM 非常擅长从文本数据中提取信息并执行使用文本描述的任务。根据我们的数据,我们可能很幸运地拥有“易于叙述”的东西。在本文中描述的情况下,我们将使用一天内收集的有关睡眠、身体活动、食物、心率和步数(以及其他)的所有数据,以供单个用户使用。有了这些信息,很容易提取用户一天的常规描述,逐节进行。由于数据如此规则,我们可以尝试使其符合模板。
我们可以定义一个模板,总结/突出我们希望在通过我们的 RAG 搜索时能够检索的重要部分。该模板将由 Gemini 在聊天会话中用作提示的一部分。在此聊天会话中,我们将要求模型从 JSON 数据中提取我们希望在报告中显示的信息。
### Date [LLM to write date]
## Activity
- Total Active Time: [LLM to fill from activities_summaries.active_minutes]
- Calories Burned: [LLM to fill from activities_summaries.calories_out]
- Steps Taken: [LLM to fill from activities_summaries.steps]
- Distance Traveled: [LLM to fill from activities_summaries.distance / activities_summary_distances.distance]
- List of activities: [LLM to iterate through activities_summary_activities and fill name, duration, calories burned]
### Active Minutes Breakdown
- Lightly Active Minutes: [LLM to fill from activities_summaries.lightly_active_minutes]
- Fairly Active Minutes: [LLM to fill from activities_summaries.fairly_active_minutes]
- Very Active Minutes: [LLM to fill from activities_summaries.very_active_minutes]
### Heart Rate Zones
- [LLM to iterate through activities_summary_heart_rate_zones and fill from heart_rate_zones (zone name, minutes)]
## Sleep
- Total Sleep Duration: [LLM to fill from sleep_logs.duration]
- Sleep Quality: [LLM to fill from sleep_logs.efficiency]
- Deep Sleep: [LLM to fill from sleep_stage_details where sleep_stage='deep sleep'] (minutes)
- Light Sleep: [LLM to fill from sleep_stage_details where sleep_stage='light sleep'] (minutes)
- REM Sleep: [LLM to fill from sleep_stage_details where sleep_stage='rem sleep'] (minutes)
- Time to Fall Asleep: [LLM to fill from sleep_logs.minutes_to_fall_asleep]
## Exercise Activities
- [LLM to iterate through daily_activity_summary_activities / minimal_activities and fill name, duration, calories burned (from activity_logs)]
...
在深入了解 Go 代码之前,我们必须设计数据库中数据的结构。
最简单的解决方案是创建一个表,其中包含我们的 LLM 将生成的文本报告及其“紧凑表示”(嵌入)在一起。
由于我们的数据已经存储在 PostgreSQL 上,因此理想的做法是使用同一个数据库来存储嵌入并对其执行空间查询,而不是引入一个新的“向量数据库”。
pgvector 是 PostgreSQL 的扩展,它允许我们定义数据类型“向量”,并为我们提供运算符和函数来执行余弦距离、l2 距离等多种度量。
安装并授予超级用户访问我们数据库用户的权限后,我们可以启用扩展并定义用于存储数据的表。
-- Enable the pgvector extension
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE IF NOT EXISTS reports (
id SERIAL PRIMARY KEY,
user_id BIGINT NOT NULL REFERENCES users(id),
start_date DATE NOT NULL,
end_date DATE NOT NULL,
report_type TEXT NOT NULL,
report TEXT NOT NULL,
embedding VECTOR
);启用 vector 扩展后,我们可以定义 embedding 字段类型为 vector。无需指定向量的最大长度,因为该扩展支持动态形状的向量。
该表被定义为存储所有用户的报告。在本文中,我们将仅介绍每日报告(因此 start_date 将等于 end_date),但该概念很容易推广到不同类型的报告。这也是 report_type 字段的原因。
将 SQL 表映射到结构是一个好习惯。使用 galeone/igor 从 Go 交互 PostgreSQL 时,这几乎是强制性的。
import (
"time"
"github.com/pgvector/pgvector-go"
)
type Report struct {
ID int64 `igor:"primary_key"`
UserID int64
StartDate time.Time
EndDate time.Time
ReportType string
Report string
Embedding pgvector.Vector
}
func (r *Report) TableName() string {
return "reports"
}仅此而已。我们现在可以与 Vertex AI 交互以:
- 从结构化数据过渡到非结构化数据,让 Gemini 填充先前定义的模板。
- 生成报告和嵌入。
- 让用户与 Gemini 创建聊天会话并创建其提示的嵌入。
- 执行空间查询以检索数据库中(希望)相关文档。
- 将这些文档作为搜索上下文传递给 Gemini。
- 要求模型通过查看提供的文档来回答用户问题。
我们可以设计一个数据类型 Reporter,其目标是生成这些报告。使用(在三篇文章后众所周知的)与 Vertex AI 交互模式,我们将创建 2 个不同的客户端:
- 用于 Gemini 的生成式 AI 客户端
- 用于我们的嵌入模型的预测客户端
import (
vai "cloud.google.com/go/aiplatform/apiv1beta1"
vaipb "cloud.google.com/go/aiplatform/apiv1beta1/aiplatformpb"
"cloud.google.com/go/vertexai/genai"
"google.golang.org/api/option"
"google.golang.org/protobuf/types/known/structpb"
)
type Reporter struct {
user *types.User
predictionClient *vai.PredictionClient
genaiClient *genai.Client
ctx context.Context
}
// NewReporter creates a new Reporter
func NewReporter(user *types.User) (*Reporter, error) {
ctx := context.Background()
var predictionClient *vai.PredictionClient
var err error
if predictionClient, err = vai.NewPredictionClient(ctx, option.WithEndpoint(_vaiEndpoint)); err != nil {
return nil, err
}
var genaiClient *genai.Client
const region = "us-central1"
if genaiClient, err = genai.NewClient(ctx, _vaiProjectID, region, option.WithCredentialsFile(_vaiServiceAccountKey)); err != nil {
return nil, err
}
return &Reporter{user: user, predictionClient: predictionClient, genaiClient: genaiClient, ctx: ctx}, nil
}
// Close closes the client
func (r *Reporter) Close() {
r.predictionClient.Close()
r.genaiClient.Close()
}我们的记者用来生成报告以及报告的矢量化表示(嵌入)。
我们可以从使用 predictionClient 调用文本嵌入模型开始。
模式总是相同的。在 Go 中使用 Vertex AI 非常复杂,这是因为必须通过填写正确的 protobuf 字段来创建每个客户端请求,这很冗长,而且不是即时的。看看我们必须编写的样板代码,以便从响应中提取嵌入。_vaiEmbeddingsEndpoint 是包含所选模型端点的全局变量。
在我们的例子中,端点是 Google 的模型 textembedding-gecko@003。此方法返回 pgvector/pgvector-go 包提供的 pgvector.Vector。
import "github.com/pgvector/pgvector-go"
// GenerateEmbeddings uses VertexAI to generate embeddings for a given prompt
func (r *Reporter) GenerateEmbeddings(prompt string) (embeddings pgvector.Vector, err error) {
var promptValue *structpb.Value
if promptValue, err = structpb.NewValue(map[string]interface{}{"content": prompt}); err != nil {
return
}
// PredictRequest: create the model prediction request
// autoTruncate: false
var autoTruncate *structpb.Value
if autoTruncate, err = structpb.NewValue(map[string]interface{}{"autoTruncate": false}); err != nil {
return
}
req := &vaipb.PredictRequest{
Endpoint: _vaiEmbeddingsEndpoint,
Instances: []*structpb.Value{promptValue},
Parameters: autoTruncate,
}
// PredictResponse: receive the response from the model
var resp *vaipb.PredictResponse
if resp, err = r.predictionClient.Predict(r.ctx, req); err != nil {
return
}
// Extract the embeddings from the response
mapResponse, ok := resp.Predictions[0].GetStructValue().AsMap()["embeddings"].(map[string]interface{})
if !ok {
err = fmt.Errorf("error extracting embeddings")
return
}
values, ok := mapResponse["values"].([]interface{})
if !ok {
err = fmt.Errorf("error extracting embeddings")
return
}
rawEmbeddings := make([]float32, len(values))
for i, v := range values {
rawEmbeddings[i] = float32(v.(float64))
}
embeddings = pgvector.NewVector(rawEmbeddings)
return
}需要指出的是,我们没有考虑模型的输入长度限制,因为我们假设报告文本和模型输入始终低于 3072 个 token 。无论如何,如果将 autoTruncate 参数设置为 false,则当输入长度超过限制时,此方法将会失败。
该函数现在可供最终用户(用于嵌入他们的问题)和报告生成方法使用,后者将创建类型 Report(该类型 Report 将被插入到数据库中)。
在 Go 中,我们可以利用 embed 包直接在二进制文件中嵌入文件。而嵌入模板正是该模块的完美用例:
import "embed"
var (
//go:embed templates/daily_report.md
dailyReportTemplate string
)GenerateDailyReport 方法将使用 gemini-pro 来按照要求填充模板。模板填充完毕后,我们将调用先前定义的 GenerateEmbeddings 方法来完全填充前面定义的 Report 结构。
// GenerateDailyReport generates a daily report for the given user
func (r *Reporter) GenerateDailyReport(data *UserData) (report *types.Report, err error) {
gemini := r.genaiClient.GenerativeModel("gemini-pro")
temperature := ChatTemperature
gemini.Temperature = &temperature
var builder strings.Builder
fmt.Fprintln(&builder, "This is a markdown template you have to fill with the data I will provide you in the next message.")
fmt.Fprintf(&builder, "```\n%s```\n\n", dailyReportTemplate)
fmt.Fprintln(&builder, "You can find the sections to fill highlighted with \"[LLM to ...]\" with instructions on how to fill the section.")
fmt.Fprintln(&builder, "I will send you the data in JSON format in the next message.")
introductionString := builder.String()
chatSession := gemini.StartChat()
chatSession.History = []*genai.Content{
{
Parts: []genai.Part{
genai.Text(introductionString),
},
Role: "user",
},
{
Parts: []genai.Part{
genai.Text("Send me the data in JSON format. I will fill the template you provided using this data"),
},
Role: "model",
},
}
var jsonData []byte
if jsonData, err = json.Marshal(data); err != nil {
return nil, err
}
var response *genai.GenerateContentResponse
if response, err = chatSession.SendMessage(r.ctx, genai.Text(string(jsonData))); err != nil {
return nil, err
}
report = &types.Report{
StartDate: data.Date,
EndDate: data.Date,
ReportType: "daily",
UserID: r.user.ID,
}
for _, candidates := range response.Candidates {
for _, part := range candidates.Content.Parts {
report.Report += fmt.Sprintf("%s\n", part)
}
}
if report.Embedding, err = r.GenerateEmbeddings(report.Report); err != nil {
return nil, err
}
return report, nil
}我们针对 Gemini 创建了一个 ChatSession,为该模型提供虚假历史记录作为背景,并发送 JSON 序列化的用户数据作为其唯一信息来源。
例如,生成的(部分)报告为:
### April 4, 2024
## Activity
- Total Active Time: 41 minutes
- Calories Burned: 346
- Steps Taken: 704
- Distance Traveled: 0 miles
- List of activities:
- Weights: 41 minutes, 346 calories
### Active Minutes Breakdown
- Lightly Active Minutes: 254
- Fairly Active Minutes: 18
- Very Active Minutes: 35
### Heart Rate Zones
- Out of Range: 6 minutes
- Fat Burn: 35 minutes
- Cardio: 0 minutes
- Peak: 0 minutes
## Sleep
- Total Sleep Duration: 7 hours 30 minutes
- Sleep Quality: 75%
- Deep Sleep: 95 minutes
- Light Sleep: 250 minutes
- REM Sleep: 118 minutes
- Time to Fall Asleep: 10 minutes
## Exercise Activities
- Weights: 41 minutes, 346 calories
...
某些信息是正确的,但其他信息缺失,尽管数据中存在这些信息(例如,JSON 中存在有氧运动/峰值信息,但模型将 0 插入为值 - 这是错误的)。使用 LLM 填充模板只是加快模板完成过程的一种方式,尽管这些数据以结构化格式提供,但最好的做法是创建正确的查询来讲述正确的故事。从而避免 LLM 的随机性。
假设我们已将所有报告插入数据库,我们现在可以接收来自用户的消息并尝试回答。
假设 msg 包含用户问题。我们必须:
- 生成嵌入
- 搜索可用的最佳相似报告(前 k 个,其中 k=3,仅用于限制上下文大小)
- 在 chatSession 中与 Gemini 共享报告并询问用户问题
- 发送结果
// 1. Generate the embeddings
var queryEmbeddings pgvector.Vector
if queryEmbeddings, err = reporter.GenerateEmbeddings(msg); err != nil {
return err
}
// 2. Search for similar reports
var reports []string
// Top-3 related reports, sorted by l2 similarity
if err = _db.Model(&types.Report{}).Where(&types.Report{UserID: user.ID})
.Order(fmt.Sprintf("embedding <-> '%s'", queryEmbeddings.String()))
.Select("report").Limit(3).Scan(&reports); err != nil {
return err
}
// 3. Share the reports with Gemini inside a chatSession and ask the user question
builder.Reset() // builder is a stringBuilder
fmt.Fprintln(&builder, "Here are the reports to help you with the analysis:")
fmt.Fprintln(&builder, "")
for _, report := range reports {
fmt.Fprintln(&builder, report)
}
fmt.Fprintln(&builder, "")
fmt.Fprintln(&builder, "Here's the user question you have to answer:")
fmt.Fprintln(&builder, msg)
var responseIterator *genai.GenerateContentResponseIterator = chatSession.SendMessageStream(ctx, genai.Text(builder.String()))
// 4. Send the result
for {
response, err := responseIterator.Next()
if err == iterator.Done {
break
}
for _, candidates := range response.Candidates {
for _, part := range candidates.Content.Parts {
reply := fmt.Sprintf("%s", part)
fmt.Println(reply)
}
}
}请注意,第 3 点是部分的:我们处于一个 chatSession 中,其中初始提示指示 Gemini 以某种方式行事,并且我们将发送包含报告和用户问题的消息。
相反,第 4 点演示了如何从 Gemini 接收流式响应 - 在创建基于 websocket 的应用程序时很有用,其中 Gemini 响应可以通过 websocket 直接流式传输回用户。
下图显示了这种交互如何使用户能够从其数据中获取见解 🙂
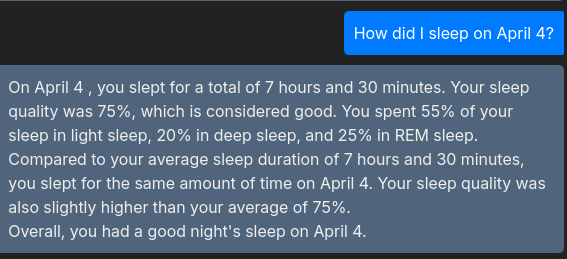
通过 Vertex AI 与 Gemini 和其他模型进行交互非常简单,一旦理解了要遵循的模式以及如何从 Protobuf 结构中提取/插入数据。所提出的解决方案允许为存储在 PostgreSQL 中的数据创建 RAG,通过生成模板。此模板已由 Gemini 填充 - 但更好的解决方案(尽管开发时间更长)是手动填充模板并创建这些“故事”。通过这种方式,我们可以至少从数据生成部分消除 LLM 的随机性。
pgvector 的集成使我们能够以无缝的方式在 PostgreSQL 上存储嵌入并进行空间查询。
在本文的结尾,我们还泄露了在fitsleepinsights.app上实现此功能的屏幕截图。在本文发布时,该应用程序尚未部署 - 但源代码可在 Github 上获得 @ https://github.com/galeone/fitsleepinsights/。