eBPF 代码的魔力,将对等地址直接传播到 TCP 流中以重建通信拓扑
译自 Building a network topology of a Kubernetes application in a non-intrusive way,作者 Ilya Shakhat。
一个 Kubernetes 应用程序在逻辑上分成两部分:一部分是计算资源(由 pod 表示),另一部分提供对应用程序的访问(由服务表示)。应用程序客户端可以使用抽象名称访问它,而无需关心实际上有哪个 pod 处理请求。并且,由于单个服务可能有多个 pod 作为后端,因此它还充当负载平衡器的角色。在默认的 Kubernetes 部署中,此负载平衡功能使用非常简单的 iptables 或 Linux IPVS 来实现——两者都在 L4(比如 TCP)层工作,并且执行朴素的、基于随机的循环机制。当然,云提供商还可以提供更传统的负载平衡解决方案来公开应用程序,但我们先从简单的开始。
当我们考虑在 Kubernetes 中部署的应用程序中可能发生的各种问题时,有一类问题需要了解处理客户端请求的特定实例。例如:(1) 某个应用程序 Pod 部署在拥用较差网络连接的主机上,建立新连接所需时间长于其他 Pod,或者 (2) 随着时间的推移,某个 Pod 的性能随之下降,而其他 Pod 的性能保持稳定,又或者 (3) 某个特定客户端的请求影响了应用程序性能。分布式跟踪通常是深入了解此类问题的其中一种方法,显然,它用于跟踪客户端请求到后端应用程序的路径。传统上,分布式跟踪需要某种形式的检测,它可能从手动添加代码转变为向运行时完全自动注入。但完全不修改客户端代码就能实现同样的效果吗?
要调试上述问题,我们基本上需要分布式跟踪的两个特性:(1) 收集与请求延迟相关的指标,以及 (2) 确切地知道每个请求的去向。第一个特性可以使用由 eBPF(一种允许动态附加探针到内核函数的技术)支持的大量工具之一,以一种非侵入性的方式轻松实现,例如,记录哪个进程建立了新连接,获取套接字/连接相关指标,甚至检查是否有重传或恶意连接重置。在 openEuler 生态系统中,这样的工具是 gala-gopher,它提供大量不同的探针,包括套接字、TCP 和 L7/HTTP(s) 探针。然而,第二个特性(知道单个请求的去向)要难以实现得多。在分布式跟踪框架中,它是通过向应用程序 payload 注入 span/trace ID,然后从客户端和后端同时使用相同的 span ID 关联观察结果来实现的。对应用程序代码来说是非侵入性的意味着相同的信息需要以通用方式注入,但对应用程序协议执行此操作根本不可行,因为这样需要拦截出站流量、对其进行解析、注入 ID 和将其序列化并转发。看起来我们刚刚重新发明了一种服务网格!
在继续之前,我们先来看一下网络监控中可获得的数据。这里我们假设监控器会从托管应用程序 Pod 的所有节点获取信息,然后这些数据会被例如 Prometheus。收集起来。要实现这个,我们需要一些实验环境。
首先,我们需要一个已部署的多节点 Kubernetes 集群。在华为云中,相应的服务称为 Cloud Container Engine(CCE)。
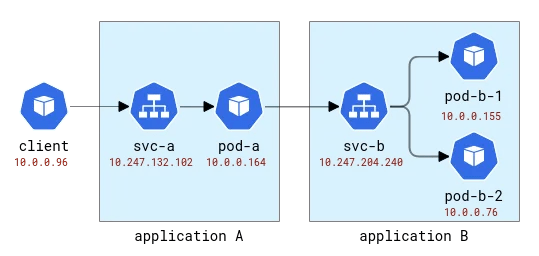
然后我们需要一个测试应用程序,为此,我们将使用一个非常简单的 Python 程序,它接受一个 HTTP 请求,并能够向原始请求中指定地址发出传出 HTTP 请求。这样,我们可以轻松地链接应用程序。
这些应用程序将以拉丁字母 A、B 等来命名。应用程序 A 被部署为 Deployment A 和 Service A,依此类推。第一个应用程序还将对外公开,以便可以从外部调用它。

A 和 B 应用程序拓扑
在 Kubernetes Gala-gopher 部署为守护程序集,并在每个 Kubernetes 节点上运行。它提供由 Prometheus 使用并最终通过 Grafana 可视化的指标。服务拓扑根据指标构建,并由 NodeGraph 插件可视化。
让我们发送一些请求到应用程序 A,并像这样转发到应用程序 B:
[root@debug-7d8bdd568c-5jrmf /]# curl http://a.app:8000/b.app:8000
..Hello from pod b-67b75c8557-698tr ip 10.0.0.76 at node 192.168.3.218
Hello from pod a-7954c595f7-tmnx8 ip 10.0.0.148 at node 192.168.3.14
[root@debug-7d8bdd568c-5jrmf /]# curl http://a.app:8000/b.app:8000
..Hello from pod b-67b75c8557-mzn6p ip 10.0.0.149 at node 192.168.3.14
Hello from pod a-7954c595f7-tmnx8 ip 10.0.0.148 at node 192.168.3.14
在输出中,我们看到对应用程序 B 的其中一个请求发送到了一个 pod,而另一个请求发送到了另一个 pod。这是拓扑在 Grafana 中的显示方式:

A 和 B 应用拓扑,由度量重建
顶部和中间行显示某些内容向应用程序 B 的 pod 发送了请求,而底部显示 A 的一个 pod 向服务 B 的虚拟 IP 发送了一个请求。但这看起来根本不像我们预期的那样,对吧?我们只看到三组节点,它们之间没有链接。来自 192.168.3.0/24 子网的 IP 地址是来自集群私有网络(VPC)的节点地址,10.0.0.1/24 是 pod 的地址,但 10.0.0.129 除外,它又是用于节点内通信的节点地址。
现在,这些指标是在套接字级别收集的,这意味着它们正是应用程序进程可以看到的内容。收集是通过 eBPF 探针完成的,因此第一个想法是检查操作系统内核是否比套接字中可用的信息更了解应用程序连接。该集群配置了默认 CNI,Kubernetes 服务作为 iptables 规则实现。iptables-save 的输出显示了配置。最有趣的是这些实际配置负载均衡的规则:
-A KUBE-SERVICES -d 10.247.204.240/32 -p tcp -m comment
--comment "app/b:http-port cluster IP" -m tcp --dport 8000 -j KUBE-SVC-CELO6J2CXNI7KVVA
-A KUBE-SVC-CELO6J2CXNI7KVVA -d 10.247.204.240/32 -p tcp -m comment
--comment "app/b:http-port cluster IP" -m tcp --dport 8000 -j KUBE-MARK-MASQ
-A KUBE-SVC-CELO6J2CXNI7KVVA -m comment --comment "app/b:http-port -> 10.0.0.155:8000"
-m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-VFBYZLZKPEFJ3QIZ
-A KUBE-SVC-CELO6J2CXNI7KVVA -m comment --comment "app/b:http-port -> 10.0.0.76:8000"
-j KUBE-SEP-SXF6FD423VYX6VFB
负载均衡在客户端所在的同一节点上完成。因此,如果我们将 pod 映射到节点,则如下所示:

将 A 和 B 应用程序拓扑映射到 Kubernetes 节点
内部 iptables(实际上 nftables)使用 conntrack 模块来理解数据包属于同一连接,并且应该以类似的方式进行处理。Conntrack 还负责地址转换,因此具有客户端应用程序的节点应该知道将数据包发送到何处。让我们使用 conntrack CLI 工具检查一下。
# node-1
# conntrack -L | grep 8000
tcp 6 82 TIME_WAIT src=10.0.0.164 dst=10.247.204.240 sport=51030 dport=8000 src=10.0.0.76 dst=192.168.3.14 sport=8000 dport=19554 [ASSURED] use=1
tcp 6 79 TIME_WAIT src=10.0.0.164 dst=10.247.204.240 sport=51014 dport=8000 src=10.0.0.155 dst=10.0.0.129 sport=8000 dport=56734 [ASSURED] use=1
# node-2
# conntrack -L | grep 8000
tcp 6 249 CLOSE_WAIT src=10.0.0.76 dst=192.168.3.14 sport=8000 dport=19554 [UNREPLIED] src=192.168.3.14 dst=10.0.0.76 sport=19554 dport=8000 use=1
好的,我们看到在第一个节点上,地址已从应用程序 A 的 pod 转换,并获得了具有某个随机端口的节点地址。在第二个节点上,连接信息被反转,因为其自身数据包实际上是回复,但考虑到这一点,我们看到请求来自第一个节点和相同的随机端口。请注意,Node-1 上有两个请求,因为我们发送了 2 个请求,并且它们由不同的 pod 处理:同一节点上的 pod-b-1 和另一个节点上的 pod-b-2。
这里的好消息是,有可能在客户端节点上了解实际的请求接收者,但对于服务器端,它需要与客户端节点上收集的信息进行关联。像这样:

连接由 conntrack 模块追踪。蓝色圆圈是在套接字中观察到的本地地址,紫色的则是远程地址。这个挑战就是要关联紫色和蓝色。
当客户端和服务器 pod 都在同一节点上时,关联变得更加简单,但仍然有一些关于哪些地址是真实的以及哪些应该被忽略的假设:

同一节点上的两个 Pod 之间的连接。源地址真实,而目标地址需要进行映射
在这里,操作系统可以全面了解 NAT,并可以在真实源和真实目标之间提供映射。有可能从 10.0.0.164 重建到 10.0.0.155 的完整流。
为了总结本节,应该可以扩展现有的 eBPF 探针以包括来自 conntrack 模块有关地址转换的信息。客户端可以知道请求的去向。但服务器并不总是能够知道客户端是谁,直接没有集中关联算法。相比之下,分布式跟踪方法为客户端和服务器提供了有关对等方的信息,直接且立即来自通信数据。因此,FlowTracer 来了!
这个想法很简单——直接在连接中在对等方之间传输数据。这并不是第一次需要这样的功能,例如,HTTP 负载均衡器会插入 X-Forwarded-For HTTP 头,让后端服务器知道客户端。这里的限制是我们希望停留在 L4,从而支持任何应用程序级别协议。这样的功能也存在,并且一些 L4 负载均衡器(例如这个)可以注入原始地址作为 TCP 头选项,并让服务器可以使用它。
需求总结:
- L4 层传输对等地址。
- 能够动态启用地址注入(如同在 K8s 中轻松部署应用)。
- 非侵入式且快速。
最直接的方法似乎是使用 TCP 头选项(也称为 TOA)。有效负载是 IP 地址和端口号(因为它们在地址转换过程中会发生变化)。由于华为 Kubernetes 部署仅支持 IPv4,所以我们可以限制仅支持 IPv4。IPv4 地址是 32 位,而端口号需要 16 位,总共需要 6 个字节,外加 1 个字节表示选项类型和 1 个字节表示选项长度。这里是 TCP 标头的规格外观:

头部可包含最多40字节的多个选项。每个选项可以具有可变长度和类型/种类。

一般而言,Linux TCP 数据包已经拥有了一些选项,例如 MSS 或时间戳。但仍然有大约 20 字节的空间可供我们使用。
现在,当我们知道在哪里放置数据时,下一个问题是应该在哪里添加代码?我们希望解决方案尽可能通用,可用于所有 TCP 连接。理想的位置是网络堆栈中内核中的某个位置,它位于所谓的套接字缓冲区(表示网络连接信息的结构)中,从顶级一直到准备好通过网络传输的数据包。从实现的角度来看,代码应该是 eBPF 代码(当然!),然后可以动态启用地址注入功能。
这种代码最明显的位置是 TC,一个流量控制模块。在 TC 处,eBPF 程序可以访问已经创建的数据包,它可以从数据包中读写数据。一个缺点是需要从头解析数据包,即即使 bpf_skb_load_bytes_relative 函数提供一个指向 L3 头部开头的指针,但仍然需要手动计算 L4 的位置。最成问题的是插入操作。有 2 个名称很有希望的函数 bpf_skb_adjust_room 和 bpf_skb_change_tail,但它们最多允许调整 L3 数据包的大小,而不是 L4。一个替代的解决方案是检查现有的 TCP 头部是否包含某些选项并覆盖它们,但让我们首先检查通常的数据包包含什么。
1514772378.301862 IP (tos 0x0, ttl 64, id 20960, offset 0, flags [DF], proto TCP (6), length 60)
192.168.3.14.28301 > 10.0.0.76.8000: Flags [S], cksum 0xbc03 (correct), seq 1849406961, win 64240, options [mss 1460,sackOK,TS val 142477455 ecr 0,nop,wscale 9], length 0
0x0000: 0000 0001 0006 fa16 3e22 3096 0000 0800 ........>"0.....
0x0010: 4500 003c 51e0 4000 4006 1ada c0a8 030e E..<Q.@.@.......
0x0020: 0a00 004c 6e8d 1f40 6e3b b5f1 0000 0000 ...Ln..@n;......
0x0030: a002 faf0 bc03 0000 0204 05b4 0402 080a ................
0x0040: 087e 088f 0000 0000 0103 0309 .~..........
这是客户端与后端应用程序建立连接时发送的 TCP SYN 数据包。头部包含多个选项:用于指定最大段大小的 MSS,然后是选择性确认,一个特定的时间戳用于确保数据包的顺序,一个可能用于单词对齐的操作码 NOP,最后用于调整窗口大小的窗口缩放。从该列表中,时间戳选项是最好的被覆盖的候选者(根据维基百科,采用率仍然约为 40%),而 DeepFlow——非侵入式 eBPF 跟踪的领导者之一——在其平台中进行了该项操作。
虽然这种方法似乎可行,但实现起来却并非易事。TC 程序能够访问已翻译的地址,这意味着应该从 conntrack 模块中以某种方式检索转换映射并予以存储。TC 程序附加到网卡,所以如果某个节点有多个网卡,那么该部署需要正确识别附加位置。读模块必须解析所有数据包才能找到 TCP,然后才能迭代遍历标头以找到我们的标头所在的位置。还有其他方法吗?
2023 年 8 月通过 Google 搜索这个问题时,经常会看到搜索结果页面底部显示没有更多结果(希望这篇博文能改变这种情况!)。最有用的参考信息是 Facebook 工程师在 2020 年制作的一个 Linux Kernel 补丁链接。该补丁显示了我们在寻找的内容:
BPF-TCP-CC 早期工作允许 TCP 拥塞控制算法用 BPF 编写。它提供了机会,以便在测试/发布新拥塞控制构想时缩短生产环境中的周转时间。同样的灵活性可以扩展到编写 TCP 头部选项。
人们常常希望测试新的 TCP 头部选项以改善 TCP 性能并非什么稀奇的事。另一个用例是为了数据中心,它具有更为受控的环境,可以在仅限内部流量中放入标头选项,这样做灵活性更大。
圣杯是这些函数:bpf_store_hdr_opt 和 bpf_load_hdr_opt!两者都属于一种特殊的 sock ops 程序类型,自 5.10 内核起均可用,意味着几乎可以在 2022 年之后的任何版本中使用。Sock ops 程序是附加到 cgroup v2 的一种单一函数,允许仅针对某些套接字启用它(例如,属于特定容器)。程序接收到单个操作,用于指示套接字的当前状态。当我们要编写新的头部选项时,我们首先需要为活动或被动连接启用写入,然后我们需要告知新的头部长度,之后才可写入头部负载。读取操作更简单,但是,我们也需要首先启用读取功能,然后才能读取头部选项。在创建 TCP 数据包时,会调用 TCP header 回调。此操作发生在地址转换前,因此我们可以将套接字源地址复制到头部选项中。读者可以轻松地从头部选项中提取值并存储在 BPF 地图中,以便稍后,使用者可以进行读取并从观察到的远程地址映射到实际地址。第一运行代码的 BPF 部分远少于 100 行。相当不错!
不过,魔鬼藏在细节中。首先,我们需要一种从 BPF 映射中删除旧记录的方法。执行此操作的最佳时机是 conntrack 模块从其表中删除连接时。Arthur Chiao 的这篇 文章 很好地描述了 conntrack 模块和连接生命周期的内部结构,因此很容易在内核源中找到正确的函数 — nf_conntrack_destroy。此函数在从内部表中删除 conntrack 条目之前接收该条目。由于这是连接正式结束的时间,因此我们还可以添加一个探针,该探针也将从我们的映射表中删除连接。
在 sock ops 程序中,我们没有指定将新的头部选项注入到哪些数据包中,假设它适用于所有数据包。事实上也确实如此,但只有在连接处于已建立/已确认状态时,读取才有效,这意味着服务器端无法从传入的 SYN 数据包中读取头部选项。SYN-ACK 也在常规 TCP 栈之前处理,并且既不能注入头部选项,也不能读取它们。实际上,该功能仅在连接完全使用第一个 PSH(数据包)运行时才在两端起作用。对于工作连接来说,这完全没问题,但如果连接尝试失败,则客户端不知道它 尝试 连接到哪里。这是一个至关重要的失误;此信息对于调试网络故障很有用。正如我们所了解的,Kubernetes 负载平衡是在客户端节点上实现的,因此我们可以从 conntrack 中提取信息,并以与通过流接收的数据相同的格式存储它。Conntrack 函数 __nf_conntrack_confirm 在这里提供帮助 — 它在新的连接即将确认时被调用,对于主动客户端(传出)TCP 连接,这发生在发送第一个 SYN 数据包时。
有了所有这些补充,代码变得有点臃肿,但总共仍然远少于 1000 行。完整补丁可在 此 MR 中获得。是时候在我们的实验设置中启用它并再次检查指标和拓扑了!
瞧:

正确的 A/B 应用拓扑