
LLM 绘图简介——使用多模态 AI 创建软件架构图并通过粘贴截图进行迭代
译自 How To Create Software Diagrams With ChatGPT and Claude,作者 Jon Udell。
在我之前的文章中,关于ChatGPT 和 Claude 可以看到你屏幕上的什么内容以及开发者如何利用它,我提到过一个浏览器扩展,它使用从完整 CNN 网站获取的图像来增强纯文本的lite.cnn.com。它运行良好,但是使用了已弃用的Manifest V2。当我让 Claude 将其更新到 V3 时,我想要绘制一些架构更改图。因此,在这篇文章中,我将回顾一下这个绘图过程。
对于第一次迭代,我让 Claude 参考扩展的 JavaScript 代码,并要求它绘制架构图。这产生了一个有用但略微错误的 ASCII 图表。
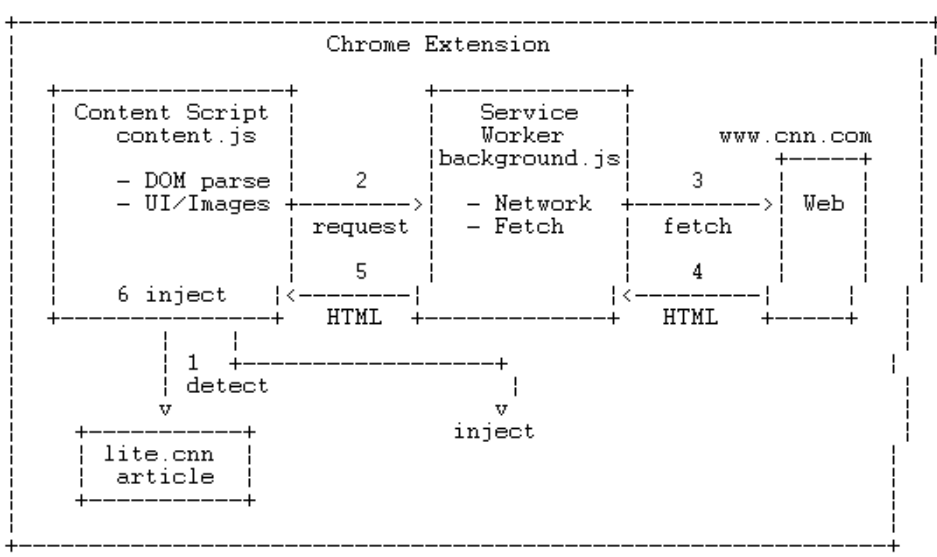
顺便说一下,V2 和 V3 版本的主要区别在于,在 V3 中,DOM 解析(在 V2 中发生在后台脚本中)移动到了内容脚本中。这是因为后台脚本现在是一个服务工作者(V3 强制要求),它无法访问 DOM 解析 API。
V3 还强制要求哪些内容被整合到新版本的扩展中?我问了,Claude 给了我一个概述:permissions 和 host_permissions 之间的分割,以及基于 Promise 的消息传递。这是对 LLM 之前流程的令人愉快的反转。之前,我会阅读 Manifest V3,找出哪些方面与我的项目相关,然后想办法应用它们。现在我有了带有解释的工作代码,我可以在代码的上下文中对其进行询问。
我们称它们为语言模型,但是当一图胜千言时,LLM 将乐于处理图片。
Claude 图表中的实体和数据流大致是我设想的那样。我可以通过一些手动编辑来修复损坏的 ASCII 布局,但这感觉很愚蠢。我宁愿为此工作征用一个合适的工具,尤其是一个可以往返于简洁的人工可写语法工具。
当我打开chatgpt.com/gpts时,Whimsical Diagrams 正好作为特色 GPT 出现在那里。所以我启动了它,向它展示了 JavaScript 代码,粘贴了 Claude 的 ASCII 图表的图片,并要求改进。这是它的第一次尝试。

这看起来好多了。我点击了whimsical.com的链接,在那里我可以进行进一步的编辑,但我找不到一种导出到标准格式的方法,而这种格式可以让我通过其他工具进行往返处理。这时,我想起了过去使用过的一些格式(不是很广泛):Mermaid 和 Graphviz。
我要求 Whimsical GPT 使用这两种格式中的一种来表示该图表。它给了我该图表的 Mermaid 语法,以及它的渲染结果。隐式地,它告诉我我想要绘制的图表类型有一个名称:“序列图”。

但这并不是迭代的正确地方。所以我将代码带到了Mermaid Live。这证明我可以编辑 Mermaid 代码并查看实时预览,但这仍然不是很有效,因为我不知道如何编辑代码。我的序列图中还可以出现哪些结构,以及这些结构如何改进它?
该图表很好地显示了扩展各个部分之间的数据流,但它没有表示内容脚本中发生的处理步骤:从服务工作者获取的完整文章页面的 HTML 中解析图像 URL,并将它们注入到 lite.cnn.com 页面中。Claude 提供了一些想法:使用“Note over”声明在图表上放置注释,或使用“自消息传递”(来自同一参与者的消息)。我说:“让我们两种方法都试试”。Claude 满足了我的要求,之后我选择了自消息传递。后来,当我阅读 Mermaid 文档时,我意识到这个短语不是 Mermaid 官方术语的一部分。它隐含在序列图的参考页面中。

但是由于该页面明确记录了“Note over”声明,我怀疑我不会更深入地挖掘以找到我更喜欢的替代方案。
现在我把不断发展的 Mermaid 代码展示给 ChatGPT,并请求改进建议。它提出一个不错的建议。
alt Article not yet loaded
CS->>LitePage: Observe page for article load (dom internal)
end
Jon: 这是什么意思?
ChatGPT: 在 Mermaid 序列图中,alt 用于表示替代流程或条件块。它允许你显示一个可能有多个结果的决策点。在你的场景中,它就像在说:
“如果文章已加载,则继续获取并注入图像。
如果文章尚未加载,则观察并等待其出现,然后继续。”
Jon: 代码是否真的这样做?
ChatGPT: 是的,看这里。
1234567891011 |
if (document.querySelector('.article--lite')) {
fetchAndProcessImages(); // Article is already loaded
} else {
console.log('Article not found, waiting for content to load');
new MutationObserver((mutations, observer) => {
if (document.querySelector('.article--lite')) {
observer.disconnect();
fetchAndProcessImages(); // Article has now loaded
}
}).observe(document.body, {childList: true, subtree: true}); // Watch for DOM changes
}更多即时学习!我通过在一个有意义的上下文中看到它的应用发现了 Mermaid 的 alt 功能。虽然我从未使用过 JavaScript MutationObserver,但我现在已经在一个对我来说有意义的上下文中看到了它的应用。当我需要它时,我可能会记住这个例子。
在这个过程中,我还在某个时刻了解到这些 Mermaid 图表可以在 GitHub Markdown 中渲染。这是扩展自述文件中的最终版本。
我对结果感到满意,它很好地说明了扩展程序的工作原理。我对导致此结果的过程更满意。通过应用使用大型语言模型的最佳实践中的规则 3 和 4(“招募一个助手团队”、“请求合唱式解释”),我得到了我想要的图表。更重要的是,我比以往更有效地学习了支持工具和技术。
这项练习也让我开始思考 Mermaid 和 Graphviz 的用途。当我要求我的助手以 Graphviz 的方式重现图表时,结果并不理想。我得出结论,序列图适合此目的,而 Mermaid 是制作它的正确方法。
接下来,我要求 Claude 和 ChatGPT 总结这两种格式的适当用途。我将每个人的列表展示给对方,以获得包含三类合并结果:Mermaid 专用、Graphviz 专用和共享。说实话,一个有三列的表格就足够了。但由于我正处于绘图状态,我认为将其转换为维恩图会很有趣。
有趣的是,这两种格式都不是它的优势。当我问 ChatGPT 如何渲染表格时,它编写了一个 Python 程序来执行此操作,经过几次迭代后,我得到了一个可用的结果。

Claude 使用 SVG,这也需要多次迭代以及与 ChatGPT 的交叉检查。
<svg viewBox="0 0 900 700" xmlns="http://www.w3.org/2000/svg">
<!-- Background rectangle: https://developer.mozilla.org/en-US/docs/Web/SVG/Element/rect
Using fill attribute to set background color -->
<rect width="900" height="700" fill="#f5f5f5"/>
<!-- Definitions for reusable elements: https://developer.mozilla.org/en-US/docs/Web/SVG/Element/defs -->
<defs>
<!-- Filter effect for drop shadow: https://developer.mozilla.org/en-US/docs/Web/SVG/Element/filter
Combines blur, offset and opacity adjustments -->
<filter id="shadow" x="-20%" y="-20%" width="140%" height="140%">
<!-- Gaussian blur: https://developer.mozilla.org/en-US/docs/Web/SVG/Element/feGaussianBlur -->
<feGaussianBlur in="SourceAlpha" stdDeviation="2"/>
<!-- Offset for shadow: https://developer.mozilla.org/en-US/docs/Web/SVG/Element/feOffset -->
<feOffset dx="1" dy="1"/>
<!-- Adjust shadow opacity: https://developer.mozilla.org/en-US/docs/Web/SVG/Element/feComponentTransfer -->
<feComponentTransfer>
<feFuncA type="linear" slope="0.2"/>
</feComponentTransfer>
<!-- Merge shadow with original: https://developer.mozilla.org/en-US/docs/Web/SVG/Element/feMerge -->
<feMerge>
<feMergeNode/>
<feMergeNode in="SourceGraphic"/>
</feMerge>
</filter>
</defs>
<!-- Title text: https://developer.mozilla.org/en-US/docs/Web/SVG/Element/text
text-anchor="middle" centers text horizontally around x coordinate -->
<text x="450" y="50" text-anchor="middle" font-family="Arial, sans-serif" font-size="24" font-weight="bold" fill="#2d3e50">
Mermaid vs Graphviz Feature Comparison
</text>
<!-- Circle Labels: https://developer.mozilla.org/en-US/docs/Web/SVG/Element/text -->
<text x="350" y="120" text-anchor="middle" font-family="Arial, sans-serif" font-size="20" font-weight="bold" fill="#2d3e50">Mermaid</text>
<text x="550" y="120" text-anchor="middle" font-family="Arial, sans-serif" font-size="20" font-weight="bold" fill="#2d3e50">Graphviz</text>
<!-- Venn Diagram Circles: https://developer.mozilla.org/en-US/docs/Web/SVG/Element/circle
fill="none" makes circles transparent, only showing stroke (border) -->
<circle cx="350" cy="380" r="220" fill="none" stroke="#333" stroke-width="2" filter="url(#shadow)"/>
<circle cx="550" cy="380" r="220" fill="none" stroke="#333" stroke-width="2" filter="url(#shadow)"/>
<!-- Feature Lists: Using text element with tspan for multi-line text
https://developer.mozilla.org/en-US/docs/Web/SVG/Element/tspan -->
<!-- Mermaid-specific features - left aligned with text-anchor="start" -->
<text x="160" y="300" text-anchor="start" font-family="Arial, sans-serif" font-size="14" fill="#4a6785">
<!-- dy attribute creates vertical offset from previous line -->
<tspan x="160" dy="0">Git flows</tspan>
<tspan x="160" dy="25">Sequence diagrams</tspan>
<tspan x="160" dy="25">User journeys</tspan>
<tspan x="160" dy="25">Timeline charts</tspan>
<tspan x="160" dy="25">Requirements diagrams</tspan>
<tspan x="160" dy="25">Quick prototyping</tspan>
</text>
<!-- Shared features - centered with text-anchor="middle" -->
<text x="450" y="350" text-anchor="middle" font-family="Arial, sans-serif" font-size="14" fill="#2d5e1e" font-weight="bold">
<tspan x="450" dy="-30">Flowcharts</tspan>
<tspan x="450" dy="25">State diagrams</tspan>
<tspan x="450" dy="25">ERD diagrams</tspan>
<tspan x="450" dy="25">Class diagrams</tspan>
<tspan x="450" dy="25">Basic directed graphs</tspan>
</text>
<!-- Graphviz-specific features - left aligned -->
<text x="600" y="300" text-anchor="start" font-family="Arial, sans-serif" font-size="14" fill="#8b2635">
<tspan x="600" dy="0">Complex layouts</tspan>
<tspan x="600" dy="25">Fine-grained control</tspan>
<tspan x="600" dy="25">Advanced edge routing</tspan>
<tspan x="600" dy="25">Subgraph clustering</tspan>
<tspan x="600" dy="25">Mathematical graphs</tspan>
<tspan x="600" dy="25">Advanced node shapes</tspan>
</text>
</svg>
我不确定我更喜欢哪种方法,但在两种情况下,我现在都有可以返回并从中学习的工作示例。请注意,这不是一个苹果与苹果的比较。Python 版本向我介绍了一个特定于维恩图的库,该库使图表易于人工编写。为此,SVG 版本需要一个包装库或工具。但是,如果我想学习原始 SVG 的各个方面,我有一个不错的起点,尤其是我要求——并且 Claude 乐意提供——将 SVG 功能(如 filter)链接到这些功能文档的注释。
最后,这段经历放大了之前关于 ChatGPT 和 Claude 可以在你的屏幕上看到什么的片段。当我们迭代这些图表时,我不必用文字解释每个版本的进展情况。粘贴屏幕截图是一种更容易且同样有效的方式来发送反馈。我们称它们为语言模型,但当一图胜千言时,LLM 将乐意使用图片。