告别单点故障!Slack 如何用 Kubernetes 和 Go 将传统 Cron 升级为分布式作业调度器?利用 Kafka 消息队列和现有 Monster Job Execution Service,实现 Cron 脚本的可靠执行和监控。巧妙的 Leader Election 机制,保证系统高可用。云原生架构助力 Slack 轻松应对海量任务,运维效率 Up!
译自:How Slack Transformed Cron into a Distributed Job Scheduler
作者:Joab Jackson
十年来,Slack 在一台服务器上运行其 cron 作业。但是,当服务器开始出现问题并占用维护时间时,该公司的管理员知道需要一个更具弹性的作业调度器。因此,他们将 cron 转换为分布式系统。
在 ScyllaDB 的 Monster Scale Summit 上(上周以虚拟方式举行)的 一次演讲 中,Claire Adams,Slack 的基础设施软件工程师,描述了这家协作服务提供商如何将 Unix 调度实用程序 Cron 转换为分布式服务,
“人们真的厌倦了处理这个 cron 盒子。没有人真正想维护它。它很久以前就设置好了,”Adams 说。“人们有一些遗留知识,但没有人真正掌握所有古怪的东西。”
“我们需要更可靠的东西。”
正如每个铁杆 Linux 用户 所知,cron 是一个基于时间的作业调度器,允许管理员通过在名为 crontab 的文件中进行调度,在特定时间和日期运行脚本和应用程序。
您可以想象,拥有超过 3800 万日活跃用户 的 Slack 有大量的任务要运行。
总体而言,Slack 大约有 385 个 cron 脚本,它们共同每小时执行 2,000 个,每周总计 340,000 个作业,每年 2000 万个。
对于 Slack 来说,Cron 处理的任务既包括支持用户功能(如提醒和电子邮件通知),也包括后端维护任务(如数据库清理和运行分析作业)。
在 Slack 的前 10 年里,cron 是从单个 crontab 运行的,该 crontab 在 Amazon Web Services 上的单个服务器上运行。
然而,该系统有其局限性。尤其棘手的是软件更新,它是通过在另一台服务器上复制服务,然后切换过来完成的——速度要足够快,以免错过任何计划的作业。
然而,最后一根稻草是,在它的最后一年,cron 服务器不断因错误的内存不足错误而绊倒,需要手动修复。更多的停机时间。
“我们不能发生很多可能影响用户的事件。作为产品,我们需要更可靠、更稳定,”Adams 说。“这促使我们进行了重写。”

显然,需要一个分布在多台服务器上的调度系统。该公司希望通过迁移到分布式系统来提高可靠性、减少维护窗口并更深入地了解正在运行的作业。
团队可以采取不同的方法。例如,Slack 是 Kubernetes 的重要用户,因此他们研究了使用 Kubernetes 自己的内置 cron,cronjob。然而,这种方法需要每天启动 53,000 个 pod,并且难以调试。并且必须要求用户重写他们的脚本。所以,很麻烦。
尽管如此,“对我们来说,使用我们已经投资的技术是有意义的”,她说。
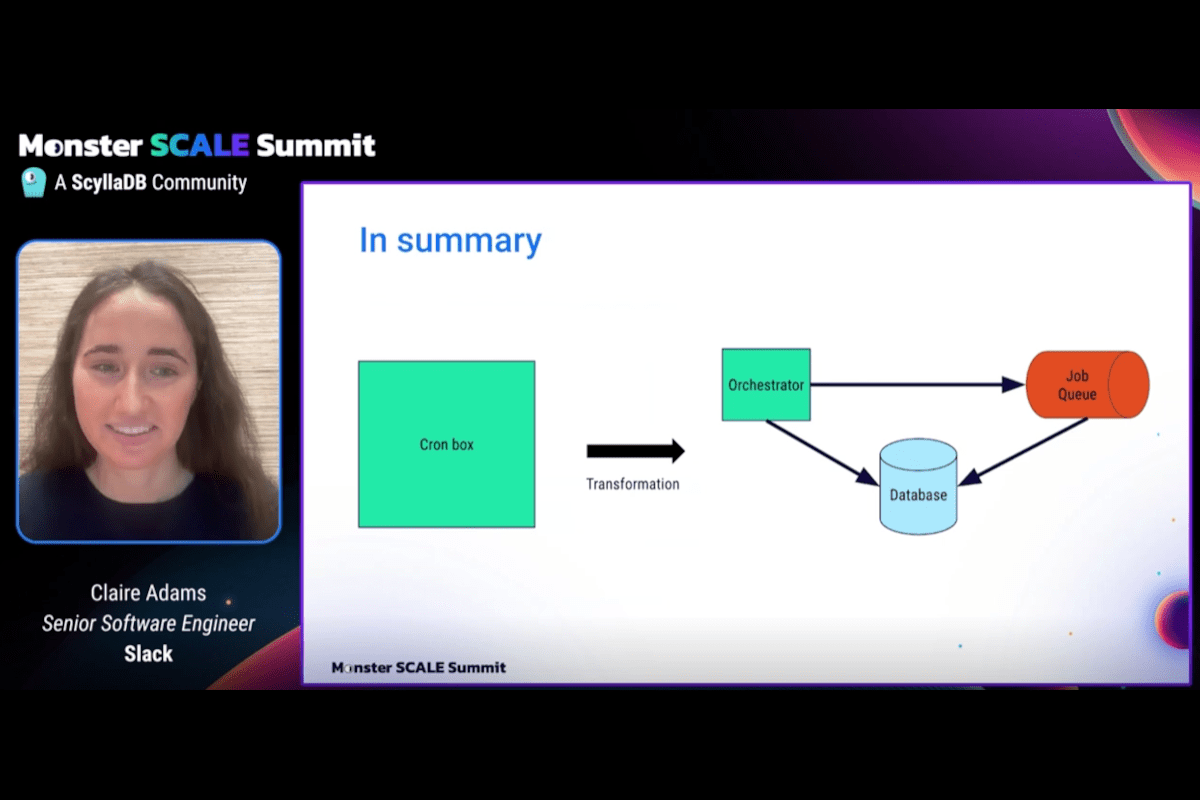
最后,需要三个不同的组件来替换曾经强大的 cron 盒子。
该系统将继续使用 cron,它将运行 cron 脚本而不进行修改。但是,cron 不会在自己的内存中运行作业,而是将它们交给单独的作业执行引擎。

碰巧的是,该公司已经构建并维护了一个异步计算平台或作业执行服务。它基于 Kubernetes 并用 Go 编程语言 编写,是一个庞然大物,每天执行 100 亿个作业。
但非常值得注意的是,它没有调度程序。只有队列。Cron 本身就是一个非常好的调度程序。幸运的是,Go 有一个可以使用的 Cron 库。这意味着无需重写任何 cron 脚本。
在此设置中,所有 cron 作业都有自己的专用队列。每个脚本都包装为一个作业,以便可以执行。 排队通过 Kafka 完成,每个作业都有自己的 Kafka 主题。一个 AWS EC2 实例实际执行工作。
因为 cron 服务器不是在自己的内存中执行脚本,所以它仍然可以在单个服务器上运行。
设计团队最初考虑了一种将脚本分散到多个 cron 服务器上的方法,但这会导致很多复杂性,需要确定哪个服务器应该运行哪个脚本。
相反,团队采用了另一种方法:使用锁进行领导者选举。
不是让每个服务器执行一些脚本,而是由一个领导者服务器执行所有脚本,并将它们交给作业引擎。备份服务器随时准备在主服务器快速发生故障时接管。

系统的最后一部分是一个数据库,用于跟踪脚本的执行情况。通常,这些信息可以在服务器上记录的 cron 日志中找到,尽管这些日志很难追踪和解析。
如果有一个集中的门户,可以保存所有状态,提供诸如上次作业运行的时间或是否成功的信息,那不是更好吗?这就是数据库的作用。
向一个每天执行 100 亿个作业的庞大作业执行器添加一些 cron 脚本不成问题。 额外的好处是,这是一个成熟的、完全受支持的系统。
“我们已经投入了数年时间来使这个作业队列系统非常可靠、非常可扩展、具有良好的保证、良好的随叫随到轮换和良好的维护,”Adams 回忆起当时的推理。“所以如果我们能够利用它,[它会]让我们的生活轻松很多。”
Slack 迁移到其分布式 cron 已经大约一年了。 到目前为止,新系统已成功执行了超过 600 万个脚本。 更好的是,它减轻了随叫随到的负担,使管理员不必每次因内存错误而弄脏服务器时都重置服务器。
“即使有更多的组件,它也更容易维护,”Adams 说。
Adams 的结论是什么? 使用你拥有的东西。 在他们的情况下,它是一个现有的作业队列、Golang 和 Kubernetes。 “你可以在减少维护负担的同时获得大规模的胜利,”她说。
即使是简陋的 cron 盒子也提供了一两个教训。
“Slack 在一个节点上运行了 10 年的关键功能。 处理这个不太理想的系统已经很长时间了。 但这已经足够好了。 它完成了工作。 我认为这是一个非常重要的收获,”她说。 “即使有点摇摇欲坠,长时间保持简单也是可以的。”
“然后,当你厌倦了,你可以尝试更好的东西。”