翻译自 The Architecture of Modern Observability Platforms 。作者 KEVIN LIN 。

可观测性平台是一个端到端的系统,帮助组织了解其应用程序和服务的健康状况。这种了解来自于现代可观测性的三大支柱:指标(时间序列数据)、日志(基于文本的数据)和跟踪(带有关联数据/元数据的请求数据)。
现代可观测性的挑战是规模——我们不再只有单个主机运行 LAMP 堆栈,每天生成几兆字节的可观测性数据,而是现在有数千个服务的 Kubernetes 集群,每小时产生数千兆字节的可观测性数据。
在规模上收集、摄取、存储和查询可观测性数据是现代可观测性平台的设计目标。根据底层架构的不同,运行这些平台的成本可能相差 100 倍以上。本文介绍了实施不同类型架构的不同解决方案。

在深入讨论架构之前,先了解一些概念。在利用可观测性数据时,有四个明确的阶段:
- 收集:可观测性数据在边缘收到(通常以在主机上运行的代理形式)
- 摄取:可观测性数据在目标地处理(通常涉及批处理、压缩和其他转换,以使数据以最佳格式存储)
- 存储:可观测性数据保留(通常涉及索引)
- 查询:可观测性数据被查找(通常涉及将查询转换为对底层存储系统的 GET/LIST 请求)

随着可观测性从检查 syslog 演变为专用的监控系统,早期的平台为每个可观测性支柱构建了高度专业化的服务。这意味着指标、日志和跟踪是由完全独立的系统处理的,具有独立的收集、存储和查询层。
在开源世界中,可能会运行 Prometheus、Elasticsearch 和 Jaeger。以下是每个服务的流水线列表。
指标的 Prometheus 流水线:
收集(Prometheus 抓取器)-> 摄取(Prometheus)-> 存储(Prometheus)-> 查询(Prometheus)
日志的 Elasticsearch 流水线:
收集(Logstash)-> 摄取(Elasticsearch)-> 存储(Elasticsearch)-> 查询(Elasticsearch)
跟踪的 Jaeger 流水线:
收集(Jaeger 收集器)-> 摄取(Jaeger)-> 存储(Cassandra)-> 查询(Jaeger)
在此期间成立的可观测性供应商(例如 Splunk、New Relic、Datadog)很可能是基于类似架构构建的(即每个支柱都有独立的服务)。

随着可观测性范围的增加(以及供应商的增多),开始出现了一些标准。这最终导致了 Open Telemetry (OTEL) 在 2019 年发布,它是这一领域两个重要项目 OpenTracing 和 OpenCensus 合并后的产物。
到 2023 年,该标准已经(大部分)成熟——它提供了一个供应商中立的规范和实现,用于从任何来源收集指标、日志和跟踪数据,并将其发送到任何目的地。
目前所有的可观测性供应商都支持 OTEL 。

随着可观测性数据越来越庞大,人们开始意识到使用高性能数据库来存储和索引所有这些数据的方法并不具备可扩展性。
与其在昂贵的数据库中预先索引所有内容,不如只进行部分索引,并将数据存储在云对象存储解决方案(例如 S3 ,通常采用 gzip + parquet 格式)中,这样可以将每字节的成本降低一个数量级。
在开源世界中,您可以在以下解决方案中找到这种架构:
采用对象存储后端的可观测性供应商:logz、grafana cloud 和 axiom 。
注意:ClickHouse 是一种高性能的开源列式数据库,也是存储指标、日志和追踪数据的常用解决方案。然而,ClickHouse 的一个缺点是它将存储层和查询层耦合在一起,这意味着在基于 ClickHouse 的架构中,基本的解耦(我们稍后将在本文中讨论)是不可行的。

当所有可观测性数据都使用统一存储后,简化其摄取就成为可能。
由于数据量大、吞吐量高,以及流量模式的突变,规模化时的摄取非常困难。因此,您可以使用像 Kafka 这样的流式平台来整合所有数据。这些平台专为实时大规模摄取数据设计,并允许实时对数据进行丰富和转换。
我不知道有任何采用这种架构的开源可观测性项目。可能的原因是,除非您使用统一存储后端为所有三个支柱构建了一个可观测性平台,否则构建专用的摄取机制比部署 Kafka 等流式平台更高效。
可观测性供应商 Coralogix 采用了一种类似的统一基于流的架构。
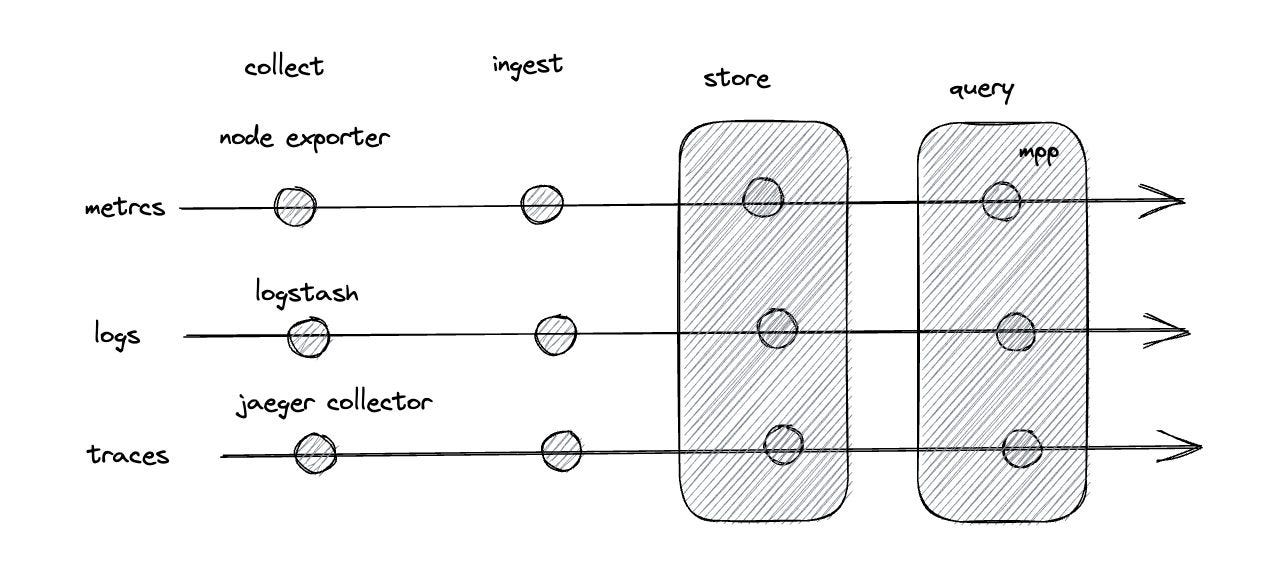
当所有可观测性数据都存储在统一存储中时,简化查询就成为可能(通常也是必要的)。
当数据被索引时,查询数 TB 的数据是昂贵的,并且当数据没有索引时,以可接受的延迟进行查询也很困难。这时,大规模并行处理(MPP)技术就发挥作用了——通过启动多个处理器来独立处理数据(使用类似 Spark 和 Trino 的工具),再结合元数据存储(如 Hive 或 Apache Iceberg ),可以在几秒钟内处理数 TB 的"非索引"数据。
与摄取类似,我不知道有任何采用这种架构的开源可观测性平台。原因与摄取类似——除非从一开始就构建支持统一存储的可观测性平台,否则部署像 Spark 或 Trino 这样的工具的开销不值得。
可观测性供应商 Observe 采用了使用 Snowflake 作为其 MPP 引擎的统一查询架构。
世界上有很多可观测性数据和许多平台可以帮助您利用这些数据。这一切都有代价——主要驱动因素是可观测性平台的底层架构(以及供应商希望实现的利润)。
通过统一存储层,可观测性平台能够在规模上实现扩展,同时将成本降低一个数量级。统一摄取层和查询层也有可能带来类似的好处。
现在有机会通过统一可观测性管道的每个层面来创建一个更具规模和可负担性的可观测性平台。在之前的文章中,我们展示了对比 Datadog ,通过将日志统一处理可以将成本降低 95% 以上。
这种统一架构有效地将规模化的可观测性变为商品化。随着被观察数据量的持续增长,这是一件好事——按照我们目前的速度,即使企业公司也开始寻找替代解决方案来降低成本。
尽管如此,拥有数据只是开始——真正的价值在于将这些信息转化为洞察力和业务结果。一旦我们不再担心成本,我们就可以尽早回到专注于这一点。